嘘ニュース対策をグーグルが導入。検索結果にファクトチェック情報を掲載【SEO記事12本まとめ】
世界的に問題となっている「フェイクニュース」対策でファクトチェックの情報を表示開始
2017年4月14日 7:00
グーグルは、ニュース記事などで語られている内容が事実かどうかの検証状況に関するラベルを検索結果に表示するようにした。「フェイクニュース」対策のために導入した、いわゆる「ファクトチェック」の情報提供だ。
ほかにも、グーグル社員によるSEO豆知識シリーズ【日本版】、AMPの機能強化、アメブロのHTTPS化完了、alt属性の2つのTIPS、ネガティブSEOへの対策などなど、SEOや検索エンジンに関する話題をまとめてお届けする。
- 今週のピックアップ
- 日本語で読めるSEO/SEM情報
- 海外SEO情報ブログの掲載記事から
- 海外のSEO/SEM情報を日本語で
- SEO Japanからのピックアップはなし
嘘ニュース対策をグーグルが導入。検索結果にファクトチェック情報を掲載
ファクトチェック自体は第三者が行う (The Keyword)

グーグルは、ニュース記事などで語られている内容が事実かどうかの検証状況に関するラベルを検索結果に表示するようにした。
世界的に問題となっている「フェイクニュース」対策のために導入した、いわゆる「ファクトチェック(Fact Check、事実検証)」の情報提供だ。国際ファクトチェック・デイ(4月2日)から少し遅れて4月7日に発表している。
ファクトチェックのラベル表示は、いくつかの国のグーグルニュースではしばらく前に導入されていたのだが、あらたに、すべての国のすべての言語での通常のウェブ検索の検索結果で、ファクトチェック結果があれば明確にわかる形で表示されるようになっている。
日本語サイトでの例を見つけることができなかったので、英語サイトの例をいくつか紹介する。
こちらは、世界で最大2700万人が奴隷状態であることを報じた記事に関する表示だ。
PolitiFactによるファクトチェック結果として、「Mostly True」(ほぼ事実)というラベルが付いている。

こちらは、ナチスによるホロコースト(ユダヤ人大量虐殺)で、ユダヤ人の母親が殺される前に自分の赤ちゃんを抱っこしているとする写真に関する表示だ。
Snopes.comによるファクトチェックの結果として「False」(偽り)というラベルが付いている。つまり、その写真は主張されている内容とは異なるということだ。

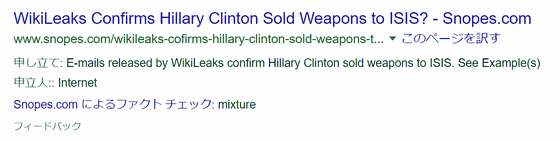
こちらは、ヒラリー・クリントン氏がISISに武器を売ったと報じた記事だ。
Snopes.comによるファクトチェックの結果として「Mixture」(事実と偽りの主張が混在している)というラベルが付いている。つまり、本当かどうかはっきりしない(または一部は正しいが事実ではない内容も含まれている)ということだ。
ラベルにはこのほかにも種類がある。
注意したいのは、事実かどうかを検証するのはグーグルではないという点だ。ファクトチェックを行うのは第三者のメディアであり、グーグルはその確認結果を表示しているに過ぎない。検索結果に表示されるファクトチェック情報を一切保証しないことを、グーグルは明言している。
そのため、検索結果で「True(事実)」のラベルが付いているからといって、絶対に事実とは限らない。また、1つの検索結果ページで、同じトピックに関して異なるファクトチェック結果が表示される可能性もあるという。
検索結果ページにおけるファクトチェック状況の表示は、記事発行者(サイト管理者)または第三者がファクトチェックしたうえで、記事が真実を語ったものか間違った情報なのかをグーグルに通知することで設定される仕組みだ。
通知には構造化データを利用する。グーグルは構造化データの情報を参照し、ファクトチェックの状態を検索結果に掲載する(Share the Factsウィジェットを利用することでも可能)。
ただし、ファクトチェックの結果を構造化データで設定したとしても、必ずそれが採用されるわけではなく、次の条件を満たす必要がある。
- アルゴリズムが「信頼できる」と判断したサイトによるファクトチェックである
- Googleニュースのファクトチェックの条件を満たしている
- Googleニュースの一般的なガイドラインを満たしている
- 構造化データの一般的な品質ガイドラインを満たしている
- ファクトチェック構造化データのガイドラインを満たしている
つまり、信頼性が低いサイトのファクトチェックは検索結果には利用されない。
とは言うものの、この表示はサイトが自らファクトチェック結果をグーグルに伝える形で示さなければ表示されない。そのため、意図的にフェイクニュースを掲載しているサイトの情報に関して、グーグルの検索結果で「このページの情報はフェイクニュースだ」と表示されることはない。
上記で紹介した検索結果の例も、ファクトチェック情報が表示されているのはファクトチェックを行ったサイトの検証ページであり、元のニュースページ自体ではない。
つまり、フェイクニュースが存在したとしても、グーグルの検索結果にフェイクニュースが通常どおり掲載される可能性は残っている。同じ検索結果ページ内に、その情報を検証した結果を伝える第三者のページの情報が並ぶだけだ。
それでも、自分の探している情報が事実なのか間違いなのか、あるいは真偽がはっきりしていないなどの記事の真実度を判断する一定の材料にはなる。何かの情報を目にした際に「この記事のファクトチェック状況は?」と気にする意識が進むといいだろう。
ちなみに、日本語記事のファクトチェックの例を見つけることができなかったのは、日本語のサイトでファクトチェックを行い構造化データを設定しているところがまだないからだろうと思われる。
グーグルの発表で紹介されているDuke Reporters' LABには日本報道検証機構のGoHoo(ゴフー)もリストアップされているが、サイトではまだ構造化データは設定されていないようだ。
日本でも、こうしたメディアが今後増えていくことに期待したい。
なおグーグルから日本語での公式アナウンスは出ていないが、ヘルプ記事は日本語化されている。
- 一般の検索ユーザーとして知っておきたい
日本語で読めるSEO/SEM情報
グーグル社員がつぶやくSEO豆知識シリーズ【日本版】
ハッシュタグは #Google検索豆知識 (長山一石 on ツイッター)
SEOの豆知識をグーグルのゲイリー・イリェーシュ氏が解説する“DYK(知ってたかい?)”で始まるツイートのシリーズがある。小ネタだが有用な情報が多いので、このコーナーでも何度か紹介している。
グーグル社員の長山氏も、ツイッターで「#Google検索豆知識」シリーズの投稿を始めた。もちろん日本語だ。
イリェーシュ氏に対抗してのものかどうかは定かではない。いずれにせよ、グーグル社員からSEOに役立つちょっとした知識を得られる機会が増えるのは、ありがたいことだ。
サーチ・コンソールの[クロールエラー]にたくさん404エラーのURLがあっても慌てないでください。Googleがたまたま存在しないURLをクロールしようとしてしまっただけかもしれません。404を返すべきURLでエラーが出ているなら、無視しても大丈夫です。 #Google検索豆知識
— Kazushi N. | 長山一石 (@KazushiNagayama) 2017年4月10日
SearchConsoleにデータの不備などが発生する・した場合、このヘルプ記事が更新されます: https://t.co/J0CeXhMEpO 残念ながら今のところ英語しかないみたいです…聞いていただければ説明します #Google検索豆知識
— Kazushi N. | 長山一石 (@KazushiNagayama) 2017年4月10日
イリェーシュ氏もびっくりするような、役立つSEO豆知識がどんどん出てくることを期待しよう。
とは言っても、SEOには何の役にもたたない(でもおもしろい)お遊び的な小ネタもある(「SEO豆知識」ではなく「Google検索豆知識」なので)。せっかくなので、こちらも紹介しておこう。
[一回転] で検索すると検索結果が一回転します #Google検索豆知識
— Kazushi N. | 長山一石 (@KazushiNagayama) 2017年4月10日
「Google」は「Googol」(10^100) のミススペルらしいです。 #Google検索豆知識
— Kazushi N. | 長山一石 (@KazushiNagayama) 2017年4月10日
- すべてのWeb担当者 必見!
動きのある画像コンテンツをAMPで提供可能に
サムネイル付きカルーセルとフォーム+画像サムネイル (Google Developers Japan)
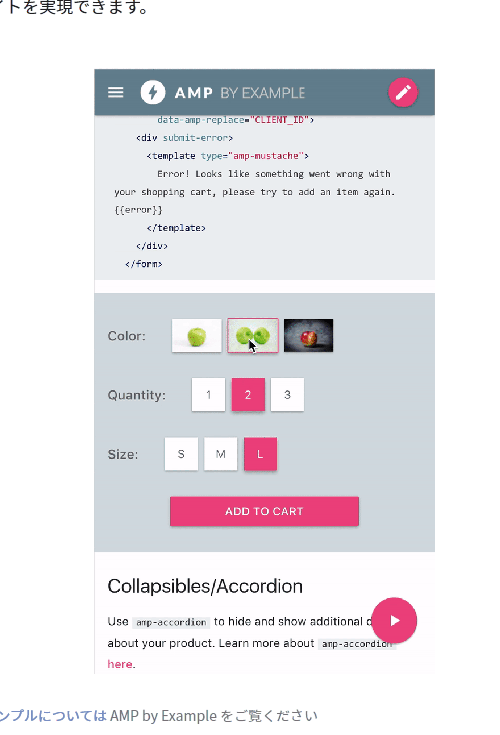
AMPページで、画像のカルーセル表示や選択ができるようになった。具体的には、次の2つの仕組みを実装可能になった。
サムネイル付きカルーセル
画像カルーセルにサムネイル(縮小版)画像を添え、サムネイルをタップすることで、カルーセル内の特定の画像に直接ジャンプできるようにするもの。

フォーム + イメージ サムネイル
入力フォーム内で、画像をボタンのようにタップすることでチェックボックスやラジオボタンのような選択肢として使えるようにするもの(デフォルト設定・複数設定・無効化設定なども可能)。
AMPと言えば「動かないシンプルなコンテンツ向け」という印象だが、動きがある要素も徐々に使えるようになってきた。
元記事ではアニメーションGIFで実際の動きを見ることができる。具体的な利用イメージや仕様の詳細は、元記事でチェックしてほしい。
- AMPがんばってる人用(ふつうの人は気にしなくていい)
毎月恒例のウェブマスター向けオフィスアワー3月開催版
今回はサイト固有の質問が多め (ウェブマスター オフィスアワー)
3月末に開催されたウェブマスター オフィスアワーを紹介する。
念のために毎回説明しているが、「ウェブマスター向けオフィスアワー」とは、グーグルの社員が登場して、一般のウェブマスターからのサイト運営に関する質問に回答したり、ウェブマスターとカジュアルに情報交換したりしていく動画プログラムだ。
だいたい1か月に1回開催されており、イベントページや専用のフォームから質問を投稿できる。
今回取り上げられた主な質問は次のとおりだ。いつものメンバーの、金谷氏と長山氏、アンナ氏の3人が回答してくれた。
- 日付が間違っているスニペット
- 違うページのmeta descriptionが表示される
- 毎年行われるキャンペーンのページがインデックスされない
- Googleアナリティクスのパラメータが付いたURLがインデックスされる
- iframeのインデックス
- クローキングの判断
- Google Optimizeのメリット
- スタンドアロンAMPのimgタグ
- スマホとフィーチャーフォンに存在しないページ
- インデックスが減少
- 手動対策の解除
- 「もっと見る」ボタンで出現するモバイル向けページのコンテンツ
- info:検索の結果がおかしい
今回はサイト固有の質問が多かったように思う。それでも参考になるだろう。YouTubeにアップロードされた録画で視聴できる。
- 一部は、すべてのWeb担当者 必見!
- 一部は、SEOがんばってる人用(ふつうの人は気にしなくていい)
- 一部は、ホントにSEOを極めたい人だけ
アメブロがHTTPS移行を完了
日本のHTTPS率を押し上げるか? (サイバーエージェントSEO情報ブログ)
アメーバブログ(以下、アメブロ)利用ブロガーにSearch Consoleの設定追加を依頼するお知らせが、サイバーエージェントSEO情報ブログに投稿された。
アメブロで進めていたHTTPS移行により、追加でHTTPSのURL(とAMP版のサブドメイン)もSearch Consoleに登録する必要が生じたのだ。
つまり、アメブロ全体のHTTPS移行が完了した。
アメブロは一般的なブログだ。匿名性や機密性が高い情報を扱っているわけではない。しかしそれでもサイト全体をHTTPSにしたのは、プライバシーやセキュリティをアメブロの運営側が重視しているからにほかならない。
日本でのHTTPSの普及率は低めだが、日本最大級のブログサービスであるアメブロがHTTPSになったことで、目に見える程度に増えるのではないだろうか。
- HTTPSはすべてのWeb担当者が気にかけるべき
グーグルが、セーフブラウジングのサイトステータスツールをリニューアル
万が一のときのために存在を知っておこう (グーグル ウェブマスター向け公式ブログ)
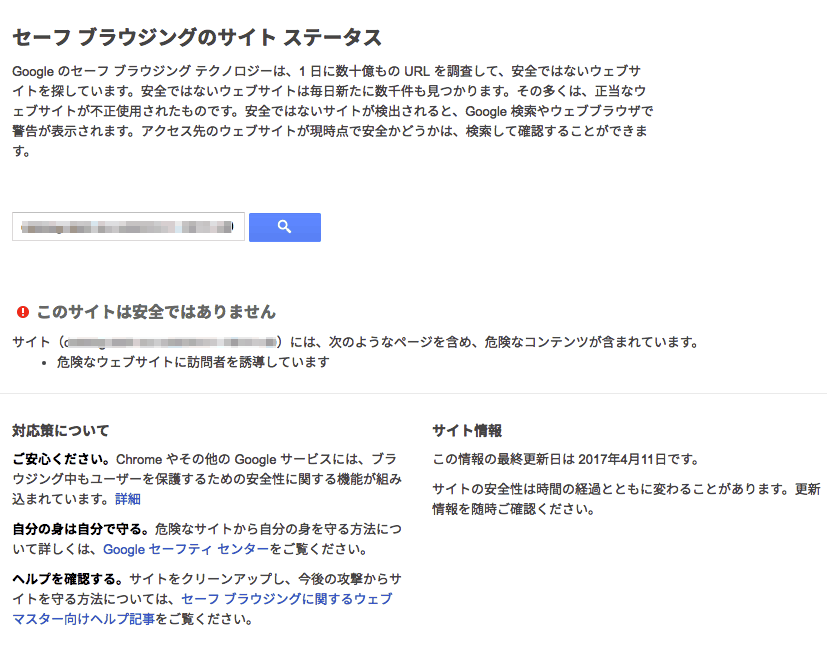
グーグルは、特定のサイトがウイルスやマルウェアが仕込まるなど危険な状態になっていないかチェックするツール「セーフブラウジング」のサイトステータスツールをリニューアルした。
公式記事によれば、新バージョンは次のように改良されたとのことである(読みやすくするために編集部で改行を追加)。
結果の表示が簡潔で明確になり、設計が調整されています。
この変更により、セーフ ブラウジングの警告を受け取ってからツールにアクセスするユーザーや、Google でのマルウェアやフィッシングの検出についてオンラインで調べようとするユーザーにとってより使いやすいツールになりました。
ツールのユーザー インターフェースも整理され、説明はわかりやすく、結果はさらに正確になりました。
このツールは、安全かどうか不安なサイトにアクセスする前に自分でチェックするために使うことも可能だし、自分のサイトに問題が起きていないかチェックするためにも使える。
さらに今回のバージョンアップによって、事前のチェックだけでなく、万が一ハッキングによって自分のサイトでセキュリティの問題が発生した際に対処を知るためにも使いやすくなったはずだ。存在だけでも知っておこう。
- すべてのWeb担当者が念のため知っておく
 海外SEO情報ブログの
海外SEO情報ブログの
掲載記事からピックアップ
AMPとAMP+PWAの記事を今週はピックアップ。
- AMP Start、レスポンシブウェブデザインのAMPサイトを簡単に構築できるテンプレートを公開
美しいAMPサイトが簡単に作成できる!
- すべてのWeb担当者 必見!
- AMPとPWAのコンボで表示速度とコンバージョンを劇的に改善したフライト検索サイトのWego
通信環境が悪い国では効果絶大
- SEOがんばってる人用(ふつうの人は気にしなくていい)
- ホントにSEOを極めたい人だけ
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00




