検索避けをするには? → noindexタグもrobots.txtも指定 → 逆効果だったorz などSEO記事まとめ10+4本
「(not provided)」で隠されたキーワードを探る方法、不正コピーサイト対策、グーグルの中核アルゴリズム、HTTPS設定などなど
2015年10月30日 7:00
検索結果に自分のページが表示されないように、念には念を入れてnoindexタグを指定してrobots.txtでもクロールを禁止したら……。
ほかにも「(not provided)」で隠されたキーワードを探る方法、不正コピーサイト対策、グーグルの中核アルゴリズム、HTTPS設定、ランド・フィッシュキン氏による「2つのアルゴリズムの世界におけるSEO」などなど、SEOの話題をたっぷりお届けする。
検索避けをするには? → noindexタグもrobots.txtも指定 → 逆効果だったorz
まだある誤用 (Kazushi Nagayama on Twitter)

グーグルの検索結果に表示したくない場合、
- noindex robots metaタグをページに記述し
- さらにそのページへのクロールをrobots.txtでブロックする
の両方を同時に行うのは、よろしくない。
なぜ良くないのか、それはこういうことだ。
robots.txtでクロールを禁止すると、Googlebotはそのページをクロールしない。
クロールしなければ、そのページにnoindexタグがあるかどうかは、わからない(たとえ記述されていても)。
結果として、noindexの効果が出ず、検索結果に表示され続けてしまう。
noindexタグとrobots.txtを併用するという間違った使い方は、このコーナーでも何度か注意を促したことがある。だが現実問題として、誤用してしまうウェブ担当者が依然として多いようだ。
実際に、グーグルの長山氏が、ツイッターでこんなことを発信していた。
@suzukik あるページが既にインデックスされている場合、それをインデックスされないようにするために robots.txt でクロールをブロックしてしまい、結果として noindex が検索エンジンに認識されないままになってしまう、というのはしばしば見られる誤りなので、
— Kazushi Nagayama (@KazushiNagayama) 2015, 10月 15@suzukik それは避けるべきプラクティスである、ということはもっと広めていきたいですね
— Kazushi Nagayama (@KazushiNagayama) 2015, 10月 15なお、robots.txtでブロックしたら、そのページに書かれているものは、noindex robots metaタグに限らずグーグルには認識されない。また301リダイレクトのようにHTTPヘッダーのなかで通知するものも認識されない(クロールしない、言い換えればそのURLにアクセスしないのでヘッダーを返されることがないから)。
必ず理解しておこう。
日本語で読めるSEO/SEM情報
(not provided)に負けない! GAと検索アナリティクスでコンバージョンキーワードを調べる賢い方法
ヤフーに使えないのが残念 (デジタルマーケティング研究所)
そのままでは「(not provided)」で隠されているが、うまく情報を組み合わせることで「コンバージョンに至った検索キーワード」を調べる方法を解説している記事を紹介する。
グーグル検索のHTTPS化により、アクセス解析ツールでのキーワードの取得が不可能になった。ほぼすべてが「(not provided)」で記録されてしまう。コンバージョンに至ったキーワードも当然わからない。HTTPS化の影響を受けずに、キーワード情報を取得できるのは、Search Consoleの検索アナリティクスだけだ。
しかし検索アナリティクスは検索結果でのデータを提供するだけで、検索結果をクリックした後のユーザー行動までは知ることはできない。したがって、一般的なアクセス解析ツールとは異なり、そのキーワードでアクセスしたユーザーがコンバージョンに至ったかどうかまでは追跡できないのだ。
しかし、「Search Consoleの検索アナリティクスとGoogleアナリティクスのランディングページレポートを組み合わせることで、コンバージョンに寄与したキーワードを調査する方法」を、こちらの記事では解説している。
手順を簡単に説明すると次のようになる。
Googleアナリティクスで、Google検索から訪問してコンバージョンしたユーザーは、どのページに着地していたかを調べる
検索アナリティクスで、そのページに着地したキーワードを調べる
なかなか賢いやり方だ。詳しい設定方法は元記事を参照してほしい。
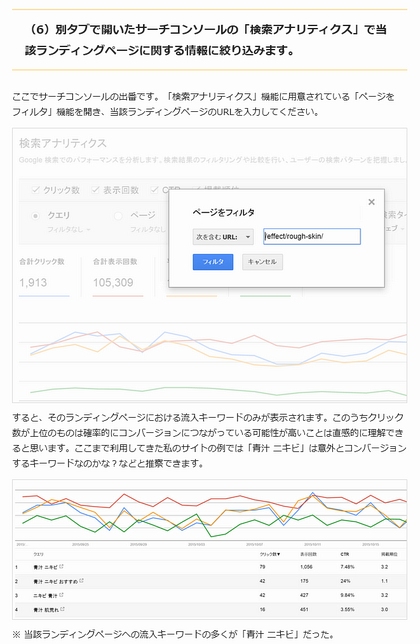
残念なのはヤフー検索には使えない点だ。検索アナリティクスのようなツールをヤフーは提供していないからだ。
HTTPS化によって、検索ユーザーのプライバシーを守ることは素晴らしい取り組みだ。しかしグーグルとは違い、ヤフーはHTTPS化しても、ウェブマスターに対する配慮を見せるつもりはなさそうである。検索サービスはもちろん検索ユーザーが利用するものだが、同時にウェブサイトあっての検索サービスでもあるのに、とても残念なことだ。
不正コピーサイトに徹底抗戦! 勝利を勝ち取った7つの対処策
コピーサイトの対策に苦慮したときの参考に (ウェビメモ)
コンテンツを丸ごとコピーされた挙句に、オリジナルである自分のサイトよりもコピーサイトの方が検索結果で上位表示されてしまうという目も当てられない状況に陥ってしまたサイト管理者が、あの手この手で対策した経緯をつづった記事。
次のような対策を講じて徹底抗戦したとのことだ。
- GoogleのSearch Consoleから著作権侵害の申し立て
- どの程度の不正コピーなのか検証
- JavaScriptでドメインがgirlydrop.comじゃない場合にゴニョゴニョする
- CSSなどの差し替え
- htaccessに追記
- 埋め込まれたアフィリエイト会社に通報
無断コピーを完全に防ぐことは不可能だが、もしそんな事態に苦慮したときの参考になるかもしれない。
グーグル、_escaped_fragment_のAjaxクロールスキームを廃止
AjaxでもそのままでOK (ウェブマスター向け公式ブログ)
グーグルは、Ajaxクロールに関するスキームを廃止したことを公式にアナウンスした。
Ajaxクロールに関するスキームとは、Ajaxで生成するコンテンツをGooglebotに認識、処理させるためにグーグルが定めた特殊な設定だ。Ajaxコンテンツを提供しているサイトではこのスキームに従うことが求められた。
しかし、グーグルの技術力の進歩にともない、現在のGooglebotはJavaScriptを解釈できるようになっている。Ajaxも例外ではなくなった。もはやそのままでもGooglebotはAjaxコンテンツをクロール、インデックスできるのだ。特殊なスキームに従う必要はなくなった。
アナウンスの詳細や注意点、よくある質問は、公式記事を読んでいただきたい。
ただし、グーグルといえども、あらゆるAjax構成を完璧に処理できるわけではない。もし、うまく処理されていないケースに遭遇したら、グーグルにフィードバックしよう。改善に役立ててくれる。
First Click Freeポリシーをグーグルが変更
1日5記事から3記事へ (ウェブマスター向け公式ブログ)
通常は会員などに限定しているコンテンツを、検索結果から来たユーザーには特別に無料で表示する「First Click Free」のポリシーを、グーグルが変更した。
具体的には、次のような変更だ:
変更前無料で読める記事は1日あたり5本まで
変更後無料で読める記事は1日あたり3本まで
マルチデバイス環境が当たり前となり、デバイスを変えれば1人のユーザーが1日で読める記事の数が実質的に増えてしまうことが、大きな理由だ。
ポリシー変更の発表とともに、First Click Freeに関してよくある質問にも答えている。購読制でコンテンツを配信しているサイト管理者は、目を通しておこう。
 海外SEO情報ブログの
海外SEO情報ブログの
掲載記事からピックアップ
App Indexingとリンクの否認ツールに関する記事を今週はピックアップ。
- GoogleのApp IndexingがiOS 9に対応、Safariのモバイル検索結果からでもアプリを直接開けるように
AndroidとiOSの両方でApp Indexingを設定しよう - 【要注意】HTTPS移行後はSearch Consoleから否認ファイルの再アップロードが必要
HTTPS移行のチェックリストに追加
- この記事のキーワード
関連記事
スマホ版ページをnoindexにしてもスマホ検索には出る!?(スマホ対応ラベルも付く) など10+2記事
2015年7月3日 7:00
ウザすぎた!? 全画面広告で69%のユーザーが離脱、こりゃダメだ などSEO記事まとめ10+4本
2015年7月31日 7:00
クリック率25%↑ 再訪問23%↑ 新規ユーザー増加などAMPの成果事例 などSEO記事まとめ10+3本
2016年10月14日 7:00
“縦”のレスポンシブが、真のモバイル最適化には必要なのか などSEO記事まとめ10+4本
2015年10月16日 7:00
世界のトップ10サイトが完全HTTPS化! などSEO記事まとめ10+4本
2015年7月24日 7:00
グーグル検索結果のデザイン変更に対応! titleタグ見直し5つのステップ など11+7記事
2014年3月28日 9:00
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00





