適切な調査対象者の抽出(サンプリング)とは? 〜調査・リサーチ・統計の基礎その2


ある会社のウェブ事業部の話です。
会社の業績が思わしくないため、最も評価の低い事業部を廃止することが決定しました。ウェブ事業部の評価は、運営しているウェブサイトのアクセス数で行われます。アクセス数の根拠としては、アレクサのデータが使われることになりました。もしあなたがウェブ事業部の責任者だとしたら、どういう行動に出ますか?
ご存知ない方のために少し説明しますが、アレクサは、だれでも参加できるインターネット視聴率調査のようなものです。アレクサの調査に参加するためのツールバーが配布されていて、そのツールバーをインストールしたブラウザでアクセスしたウェブサイトのデータがアレクサのサーバーに自動的に送られます。そして全世界のアレクサツールバーから集められたデータが集計され、だれでもそれを閲覧できるといったサービスです。
つまりこのサービスは、無料でどのウェブサイトが人気なのだろうという疑問に答えてくれるのです。さまざまなブログでもその出力データが紹介されたりしています。
さて、話を戻しますと、私がこのウェブ事業部の責任者なら、組織維持のため、すぐに事業部全員の会社のパソコンと、自宅のパソコンにアレクサツールバーをインストールさせるように行動を起こします。
先ほど「アレクサはインターネット視聴率調査のようなもの」と言いましたが、実はこのアレクサのデータは、リサーチ/データリテラシーの観点からは、視聴率調査と呼べるほどに精度の高いデータだとはいえません。遊びで楽しむ分にはかまいませんが、ビジネス上の重要な判断を下すためのリサーチデータとしては使えません。
自由参加型調査は操作できる
だれでも無条件に参加できる調査のことを、ここでは「自由参加型調査」と称しておきます。自由参加型調査に率先して参加するのは、マーケティングでいうところの「アーリーアダプタ」だったり、参加することで得られる何かの特典に対して興味の度合いが強い人間だったり、ポイントや金銭目当てだったりすることが多いでしょう。
インターネットを使った調査サービスを提供している会社には、自社で抱える調査協力者(モニタ、パネル)がいますが、彼らは調査に協力することで得られるインセンティブ(謝礼など)を得ることを目的とした自由参加者で、インターネット利用者の中でもお金に敏感な人の割合が高いはずです。
自由参加ということは、逆にいえば組織票で結果を操作できるということでもあります。私が以前勤めていた会社で行っていた企画で、葉書投票の集計結果にもとづいてある「賞」を授けるというものがありました。この投票には参加資格の制限があったのですが、それでも受賞したい会社が仕込んだ組織票だと思われる葉書が多数ありました。
そしてアレクサも自由参加型調査に当たります。
何百万人に聞いた調査でも使えない
また、たとえアレクサが全世界で何百万人にインストールされていたとしても、インストールした人が統計的に正しく「平均的」なネットユーザーでない限り、どのサイトがどれくらい見られていたかといったランキングとしては使えません。
現在、全世界で約8億人のインターネット利用者がいるといわれています(comScoreの2007年6月データから)。もし800万人がアレクサをインストールしたとしても、ネット利用者全体の1%です。しかもその1%は、インターネット利用者の中でも、コンピュータ技術者やサイト運営者、IT業界の人や、SEO関係者、ネットマーケティング担当者など、ヘビーユーザーに偏っているであろうことは容易に想像できます。利用している国によるバラつきもあるようです。たとえて言うなら、沸かしたばかりのお風呂の熱い上澄みのようなものです。
「熱いサンプル」だけで調査してはいけない
風呂の温度を正確に測るためには、よくお湯をかき混ぜる必要があります。風呂の湯加減を調べようと手を入れたらもの凄く熱かったので、水をジャンジャン足してからザブンと入ったら、下のほうはまだ水だった、という経験はないでしょうか? 同じように、調査のサンプルにおいて、全体の推定をより精度高く行うためには、全体の中からランダムに調査対象者を抽出しなければなりません。
調査のやり方には大きく分けて2つの方法があります。全数調査とサンプル調査です。全数調査は悉皆(しっかい)調査とも言い、国勢調査など国民全員を対象に行う場合に採る方法です。調査において、情報を得たいと考えている対象の全体を母集団といい、母集団から抽出された一部分を標本(サンプル)と呼びます。全数調査では母集団をすべて調査対象とするので精度は高くなりますが、そのいっぽう、膨大な費用が掛かるのが難点です。そのため、たいていの調査ではある限られた調査対象者(サンプル)の回答をもとに母集団全体を推定しています。これがサンプル調査です。
たとえば、「内閣支持率」は私たちがよく目にする調査データですが、これもサンプル調査によって算出されています。「内閣支持率」は国政を左右する重要な指標なので、調査の数値(支持率の絶対値)には高い信憑性が求められます。サンプル調査において、母集団全体の推定をより精度高く行うためには、調査対象者を全体からランダムに抽出する必要があります。
偏ったサンプルとは
ランダムに抽出するということは何となく頭で理解できますが、なぜそうでないといけないかピンときにくいと思いますので、逆の場合を例に挙げて考えてみましょう。
道行く人を対象に内閣支持率を調査しようとして、たまたま代々木公園を通りかかったところ、10万人規模の反政府集会が行われていました。そのとき(実際できるかどうかは置いておいて)その10万人に対して、現在の内閣を支持するか否かを聞くことができたとします。その調査の結果、内閣支持率が5%だったとしましょう。
さて、10万人を対象に調査したこの内閣支持率はデータとして採用するべきでしょうか。答はノーです。なぜなら、反政府集会に参加している人たちは、現政権に批判的な人である可能性が非常に高いからです。この調査の問題は、調査対象者がランダム(無作為)には選ばれていないことなのです。逆の視点からいうと、作為的に調査対象者を選べば、その回答結果は操作できるということを意味します。
この例は極端ですが、調査データが今すぐ欲しい場合に、無料だが作為的なデータがすぐに手に入るとしたら、あなたはその調査結果を使う誘惑から逃れられるでしょうか?
重要なのはデータ数でなく「ランダム」性
調査結果が信頼できるかどうか判断するために重要なのは、集めたデータの数ではないのです。「ランダム」性という質が大事なのです。しかし数が多いということで、私たちは簡単に騙されてしまいます。サンプル数が多くなると、サンプルのランダム性があまり気にならなくなってしまうという盲点を突いたトリックです。
アレクサの例でいうと、もし、世界で最も多く使われているブラウザであるIEに同等の機能が標準で実装され、インターネット利用者の8割以上の実態を反映するようなデータを取得できるようになれば、全数調査に近くなり、そのデータの精度は格段に高くなると思います(プライバシー意識が高まっている現在ではまずありえない話ですが)。
アレクサでは、大企業サイトとアルファブログのアクセスが同程度に
アレクサのデータにどれぐらいの偏りがあるのか、実際の例を使って紹介しましょう。次の図は、SEOで有名な住太陽氏の下記エントリー(記事)で紹介されたものです。
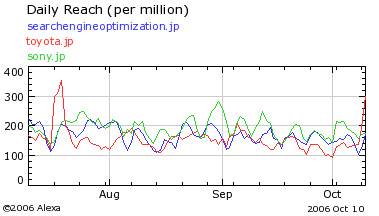
このエントリーの中盤で、アレクサのデータを見たところ、ソニーやトヨタのサイトと彼のサイトのアクセス量がほとんど同じレベルにあると書かれています。
ここまで読んで、「ああ、この人もやっちゃったか」と思ったのですが、最後の方では、自分のサイトの実態は当然違うし、
実情とはまったく異なるデータが出てしまうわけです
とコメントしています。つまり、彼は自分のサイトの実際のアクセスデータとアレクサデータとの乖離をきちんと理解して、
アレクサのデータはだいたいの傾向をつかむ足しにはなりますが、一部のカテゴリのサイトにとっては正確とはいいにくいデータを表示します
と結んでいます。ただ、これが「このエントリーのオチを」という場所で紹介されていました。このようなインターネット業界で影響力のある人は、結論を先に話してもらわないと、途中まで読んで早合点してしまうユーザーも山のようにいるのではないかと、危惧してしまいましたが。
インターネットリサーチは使えないのか
だからといって、アレクサのような調査や調査会社を否定するつもりはありません。調査協力者の偏った属性や偏った回答パターンを調整するためにどうしたらいいのか、といった点も研究が進んでいるようですし、私が前回挙げた5つのチェックポイントの他の項目に関しても、それらをクリアするさまざまな工夫をしています。そして何よりニーズがあるため、売上も好調です。つまり必要とされています。
大手企業でも、安くて早いこういった調査をうまく利用している例があると聞きます。しかしある程度経験を積んで、絶対値は使わないとか、トレンドで見ていくなどといった、使い方のノウハウが必要ではあります。
使い方を知らない素人が、その調査結果に基づいて莫大な投資の意思決定の提案書を書いたとすれば、その結果は悲惨なものになるでしょう。やはり肝心なのは、「理解して」使うということです。
精度の高いインターネット視聴率調査はどのように行われているか?
さてアレクサの対極に位置する例として、インターネット視聴率の商用サービスを提供しているネットレイティングスのNielsen Onlineのケースをお話ししましょう。調査パネルの募集方式は、日本全国の一般家庭および職場を対象にしたRDD方式(電話による無作為抽出方式)で選出した調査パネルであるとウェブサイトには書いてあります。
このRDD方式について説明しておきましょう。
まず、日本全国の携帯電話などを除く電話番号の範囲で、無作為に電話番号を発生させて、電話をかけていきます。ただし事業所の電話として登録されている番号などは事前に除くので、職場に電話することはありません。
次に、その番号で家庭に電話がつながると、その世帯の構成員でインターネット利用者がいるかどうかを確認します。自宅でのインターネット利用者(正確にはPCからウェブサイトを利用している人)がいれば、家庭ユーザーとしての調査モニタに協力してもらいたいとお願いします。また職場でのインターネット利用者がいれば、職場ユーザーとしての調査モニタとして協力を依頼します。
もちろん、これでインターネット利用者の完全な無作為抽出ができるということではありません。携帯電話しか持っていない単身世帯が対象外となってしまいますし、不在率の高い単身世帯にはつながりにくいといったことがあります。
しかしどこかのウェブサイトでオープンに調査パネルを募集するといった手法よりも、はるかにランダム性が高いといえます。先ほども述べたように、単身世帯の含有率は実態よりも低いかもしれない、という特性を理解して使えばいいのです。
なお、補足ですが、この連載の前提としては、グループインタビューのような、少人数の意見を聞いて定性的な情報を参考にする調査は、議論の対象外とします。あらかじめご了承ください。
次回は「誤差と偏り」について解説する予定です。
- アレクサでは、大企業サイトと人気ブログのアクセスが同程度と出ることも
- 熱いサンプルだけで調査してはいけない
- 百万人に聞いた調査でも使えない場合もある
- 自由参加調査は操作できる
- インターネットリサーチは特性を理解して使う
- ネットレイティングスのインターネット視聴率のサンプルの集め方はRDD



衣袋 宏美(いぶくろ ひろみ)
1960年東京都生まれ。東京大学教養学部教養学科卒業。大手電気メーカー勤務後、日経BP社へ。調査部、インターネット視聴率センター長などを経て、2000年ネットレイティングスへ。視聴率サービスやアクセス解析サービスの立ち上げに尽力。2006年株式会社クロス・フュージョンを設立し代表取締役に。2023年活動停止。
- 『Google Analyticsによるアクセス解析入門』単著
- 『PROFESSIONALアクセス解析』単著
- 『ネット視聴率白書2008-2009』編著
- 『Webアナリスト養成講座』監訳
- ブログ: Insight for WebAnalytics
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!