検索結果でフェイスブックページにリッチスニペットが表示されるようになった
- 今週のピックアップ
- 日本語で読めるSEO/SEM情報
- 海外SEO情報ブログの掲載記事から
- 海外のSEO/SEM情報を日本語で
- SEO Japanはお休みです
海外のSEO/SEM情報を日本語でピックアップ
検索結果でフェイスブックページにリッチスニペットが表示されるようになった
ローカルビジネスは検索結果で目立つチャンス (LocalVisibilitySystem.com)
グーグルの検索結果でフェイスブックページにリッチスニペットが表示されるようになった。
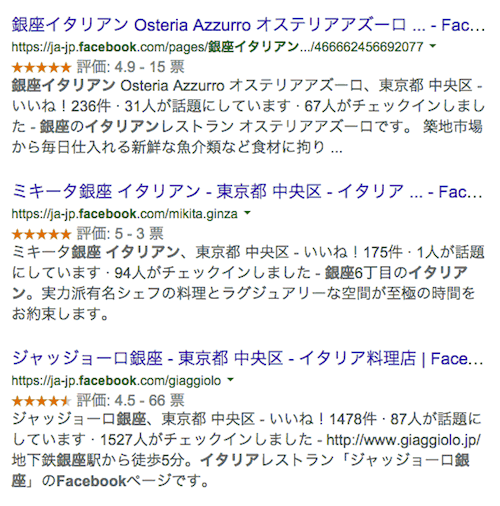
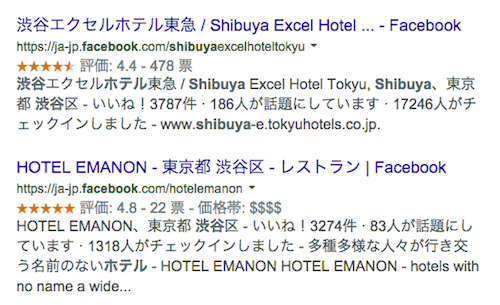
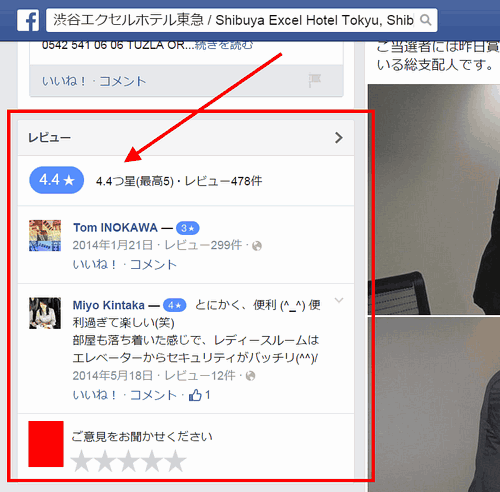
対象は、Facebookページの「レビュー」だ。たとえば上図の渋谷エクセルホテル東急ならば、Facebookページには次のようなレビューが表示されている。
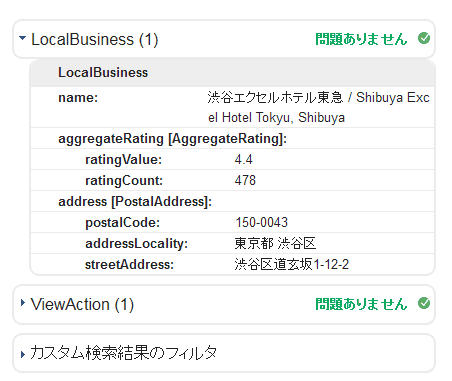
このページを構造化データテストツールで検証すると、リッチスニペット用の構造化データでマークアップされていることがわかる
一般的に、リッチスニペットは検索結果で視線を引く。レストランやホテルなど地域系ビジネスを営んでいるならば、フェイスブックページでレビューをたくさん集めれば、集客に一役買ってくれるかもしれない。
フランチャイズ店のサイトを定形フォーマットにすると重複コンテンツになる
適切に扱われるが、誘導ページにならないように注意 (English Google Webmaster Central office-hours hangout)
重複コンテンツと誘導ページに関係するグーグルによるQ&Aを紹介する。
6月30日に開催された英語版ウェブマスター向けオフィスアワーで、参加者が次のように質問した。
同じ商品を販売しているフランチャイズ店がたくさんある。だけど異なる都市で経営している。
各フランチャイズ店では、定形のデザインのウェブサイトで同じようなコンテンツを公開している。
サイトにnoindex robots meta タグを付けるべきか、それともこのままにしておいて構わないか? ペナルティを受けることはあるか?
グーグルのジョン・ミューラー氏は次のように回答した。
一般的に言えば、重複コンテンツだとしてみなし、それ相応に適切に扱うだろう。
自動的にペナルティを与えるということはないが、どのページがクエリに最も関連していて、どのページを検索結果に表示すべきかを、グーグルは、それぞれの検索ユーザーが求めていることに応じて判断しようとする。
今回のようなケースでは、「ビジネスの種類 + 場所」のクエリでそれぞれの場所を基にしてどのサイトを出すかを判断するはずだ。
ただし、誘導ページにならないようにするように注意する必要がある。
それぞれのフランチャイズ店が独自にサイトを運用するのだったら構わない。
しかし、そうではなく、同じ会社が都市それぞれにドメイン名を登録してサイトを作っていたとしたら、私たちはおそらく誘導ページだとして手動対策のアクションをとるだろう。
フランチャイズのように同じビジネスをいろいろな場所で営む形態があり、それぞれのフランチャイズ店ごとにウェブサイトを作るとする。
その場合、サイトの体裁が似ていて、さらに本部の用意した共通のコンテンツを使うことだろう。しかしそれでも必ず、フランチャイズ店ごとに独自のコンテンツを掲載するようなルールにするべきだ。単に住所や地名など固有の店舗情報だけを入れ替えるだけならば、重複コンテンツとしてみなされる可能性が高い。
もっとも、重複だとみなされること自体は重大な問題にはならないこともある。フィルタ(重複した検索結果の除外)が働き、複数のページが同時に検索結果に表示されることはなくなるだろうが、地域名が入った検索では適切なページが検索結果に選ばれるだろう。
だが最終的にユーザーがアクセスするページが同じで、単にそのページへたどり着かせるための通過ページとして、地域名の掛けあわせキーワードで上位表示させようと目論んでいたとしたら、誘導ページとして判断される可能性が高い。誘導ページを排除するアルゴリズムや手動対策の対象になりそうだ。
パンダのアルゴリズムはリアルタイム更新の能力あり。更新しないのはデータの問題があるため
いよいよ今週末に更新を実行か? (Google Webmaster Central Sprechstunden-Hangout)
パンダアップデートはリアルタイムでの自動更新なのか、特定のタイミングでの手動更新なのか、情報が錯綜していた。その状況について、7月2日に開催されたドイツ語版のウェブマスター向けオフィスアワーでの質問にグーグルのジョン・ミューラー氏が答えた。
パンダアップデートは今は定期的に更新していると私は理解しているのだが、それは正しいか?
ジョン・ミューラー氏の回答は次のとおりだ。
複雑な問題で、混乱させるような説明を私たちはしてきてしまったように思う。
アルゴリズム自体は定期的に更新できるように設計されている。しかししばらくの間、データを更新できずにいる。つまり技術的には定期的にアップデート可能なのだが、さまざまな理由があって定期更新ができていない。
これに対する「更新のためのデータがないと機能しないのか?
」という質問に、ミューラー氏は次のように答えた。
そのとおりだ。もう少し早く更新できると望んでいるのだが、そううまくいかないことも、時としてある。
しかし状況は良くなっていている。今週か来週かはわからないが、とにかく次のアップデートは間もなくだ。
パンダアップデートのアルゴリズム自体はリアルタイム更新に対応している。だが、更新を実行させるために必要な最新のデータに問題があるようだ。
データの収集に問題があるのかもしれないし、集めたデータの前処理に問題があるのかもしれない。あるいは、まったく別の問題かもしれない。
先週末にアップデートが実行されるかもしれないと予想したのだが、外れてしまった。先週末は米国の独立記念日で、アップデートを実行するのにふさわしいタイミングではなかったようだ。となると、いよいよ今週末あたりだろうか?
開発検証用サイトを検索結果に出さないための3つの方法
どこまで厳密にアクセス制限するかで選ぶ (WebmasterWorld)
開発検証用サイトを検索エンジンにインデックスさせないようにするにはどんな方法がベストだろうか?
このような質問がWebmasterWorldフォーラムに投稿された。
ベテランメンバーの1人は、次のような3つの方法を提示した。
- IPアドレス制限
- パスワード認証
- noindex robots meta タグ
いわく、上から理想順だとのこと(このメンバーが考える理想であり、3つすべてを併用することもできる)。
筆者からの補足を交えて説明しよう。
IPアドレス制限は、あらかじめ設定したIPアドレスのコンピュータからのアクセスだけを許可するものだ。検索エンジンのクローラや無関係な外部の人のIPアドレスからはアクセスできない。
ただし、チェック用にサイトを確認するコンピュータのIPアドレスが固定でない場合は手間がかかってしまうのが問題だ。
パスワード認証は正しいパスワードを入力しないとアクセスできない仕組みだ。クローラが正しいパスワードで認証できるはずがないので、この方法でもインデックスを防げる。
ただし一般的に使われる「ベーシック認証」はパスワードがネットワーク上に平文で送信されるため、第三者に開発中サイトを見られる危険がゼロではない。「ダイジェスト認証」にするか、またはHTTPSにするのがいいだろう。
noindex robots metaタグは検索結果に表示しないようにするためのHTMLタグだ。
先の2つとは異なりアクセス制限の機能ではないので、URLを知っていればだれでも自由にアクセスできる。だがheadセクションにタグを1行記述するだけなので、最も簡単に検索でヒットしないようにする設定だといえる。
なおrobots.txtでのアクセス制限も可能だ。しかし、条件によっては検索結果に出てくることがありうる。
ここで取り上げた以外にも方法はあるので、検索エンジンのインデックスを防ぐことに加えて、第三者に対してどこまでセキュリティを高めるかによって、採用する方法を考えるといいだろう。
リッチスニペットのガイドライン違反で手動対策を受けた珍しい事例
対処はリッチスニペット非表示 (Search Engine Roundtable)
リッチスニペットの品質ガイドラインに違反したために、グーグルに手動対策を与えられた事例がSearch Engine Landの寄稿記事で紹介された。
構造化データに関するグーグルのポリシーには次のように書かれている。
ガイドラインが定める基準を満たしていない場合は、アルゴリズムまたは手動による対策を適用することがあります。
だがリッチスニペットのガイドライン違反が原因で手動対策を実際に与えられた事例が表に出てくるのは、かなり珍しい。筆者は過去に1件あったのを知っているだけだ。よほどひどい乱用・悪用だったに違いない。
ただ、手動による対策の中身はリッチスニペットを非表示にするだけのようだ。検索順位を下げたり、まして検索結果から削除するような対処ではないらしい。リッチスニペットはランキングとは関係ないので、もっともといえばもっともなのだが。
 SEO Japanの
SEO Japanの
掲載記事からピックアップ
更新がなかったため今週もお休み。
- この記事のキーワード
関連記事
半年も持たず失敗するオウンドメディアが持つ6つの特徴 などSEO記事まとめ10+3本
2015年12月4日 7:00
パンダアップデートで低品質評価される5つの原因はこれだ!など10+4記事
2014年10月31日 8:00
SEOの神でも解読できないほど、今のグーグルは複雑怪奇なアルゴリズムなのか など10+3記事
2014年12月12日 6:00
グーグル公式(SEO向け)「検索エンジンの仕組み」 など10+4記事(海外&国内SEO情報)
2013年3月8日 9:00
被リンクなしでの上位表示は可能なのか? マット・カッツ氏いわく……など10+4記事
2014年6月6日 9:00
グーグル「キーワードがnot providedだらけ問題は数か月のうちに何とかする」 など11+3記事
2014年3月14日 9:00
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00




