SEO Japanの掲載記事からピックアップ
海外のSEO/SEM情報を日本語でピックアップ
- グーグルがバックリンクを認識する6つの要因
(WebmasterWorld)外部のサイトからバックリンクが張られたとしても、それを検索エンジンが直ちに認識するとは限らない。グーグルがバックリンクを認識する代表的な6つの要因をWebmasterWorldのフォーラム管理者tedsterは次のように述べている。
- リンクしているページのPageRank
- リンクしているページにほかにいくつリンクがあるか
- リンクが出現する場所がどのくらいコンテンツの先頭に近いか
- ページのテンプレート全体の中のリンクの場所 ―― たとえばフッター部のリンクはほとんど何も与えてくれないが、メインコンテンツ部の上の位置にあるリンクはもっと多くを与えてくれる
- リンクしているページやサイトに対してかかっているペナルティやフィルタ
- リンクされているページやサイトに対してかかっているペナルティやフィルタ
- グーグル社員お気に入りのウェブマスターツールの機能
(Search Engine Guide)グーグルのPR担当といえばウェブスパムチームのリーダー、マット・カッツ氏が真っ先に思い浮かぶ。しかし最近は、カンファレンスやインタビュー、ビデオなどで、ウェブマスターセントラルチームのエンジニアであるマイリー・オイェ女史の露出が増えてきた。今回ピックアップするのは、Search Engine Guideとのインタビュー記事である。
Googleウェブマスターツールについてのインタビューでかなり長いのだが、その中からマイリーさんのお気に入りの機能を紹介する。
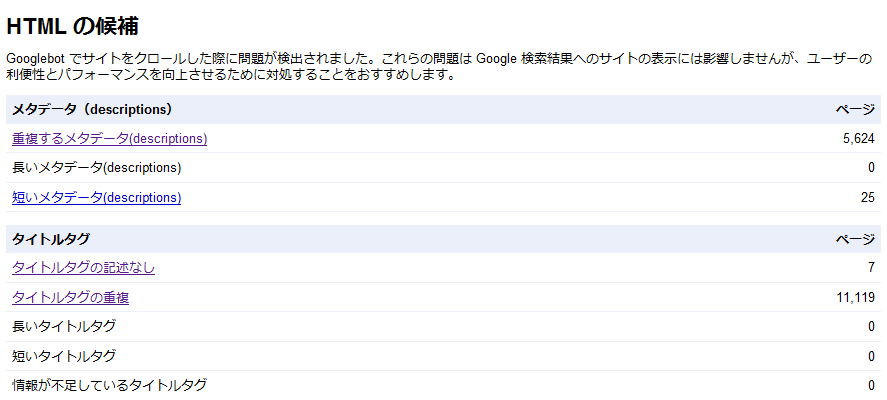
マイリーさんのお気に入りは「HTMLの候補」である。「HTMLの候補」では、重複するmeta descriptionや重複するtitleタグを確認できる。

メインコンテンツ部分の重複を避けるのは当然だとして、meta descriptionの記述やtitleタグが同じあるいはほとんど同じになっていると重複コンテンツだとみなされてしまうことがある。CMSを使っているとmeta descriptionやtitleの重複が発生しやすい。定期的に「HTMLの候補」をチェックして、別々に認識してもらいたいページのmeta descriptionタグやtitleタグにダブりが発生していないか調べておこう。
- グーグルのSSL検索でもリファラーから検索キーワードを取得する方法があった
(Mike Cardwell on the Internet)グーグルがテスト公開しているSSL検索ではリファラーの取得ができないため、アクセス解析ツールで検索キーワードの分析が不可能になると先週のこのコーナーで説明した。
実は、回避策が1つだけある。自分のサイトでもSSLを導入して、標準でHTTPSで通信するように設定して、その状態でインデックスされるようにすることだ。HTTPSからHTTPSへの移動時にはリファラーが渡されるので、キーワードを取得できる。
とはいっても誰にでも容易に実装できるわけでもないだろう。いくつか問題点がある。
- サーバー証明書をお金を払って取得しなければならない
- SSLを導入すると暗号化・復号の処理に負荷がかかるのでサーバーのレスポンスが低下する
- ウェブサーバーがApacheでバーチャルホスト(hostヘッダー)を利用してる場合は専用のIPアドレスが必要になる(IIS6.0と7.0はホストヘッダーとの併用可)
グーグルのSSL検索はウェブ担当者にとって、やはり驚異(面倒?)になりそうだ。
- SEOmozのランドが嘆いた、「グーグルは有料リンクをなんとかできないのか」
(Rand Fishkin(randfish) on Twitter)SEOmozのランド・フィッシュキン氏がツイッターでこんなツイートを発した。
ペイドリンクのテストがとてもうまい具合にいったのがわかって、実際のところ少し悲しい。頼むよグーグルのウェブスパムチーム、もっとうまくやれるんじゃないか?SEOmozは長期的展望とリスクの観点からリンク購入をストップした。グーグルがランキングを操作するための有料リンクを禁止しているにもかかわらず、徹底できていないことを嘆いているのであろう。
SEO Japanの掲載記事からピックアップ
今週はリンクに関する記事を2本ピックアップ。
来週は、SMXシアトルに参加のため、このコーナーはお休みさせていただきます。次回6月18日の記事をお楽しみに!
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00




