クロール配分をウェブマスターツールとExcelを使って調べる方法
難しいツールを使わずに、最近話題の「クロール配分」を調べる方法。
2010年6月7日 9:00
SEO業界では最近、「クロール配分」が話題に上っている。クロール配分は新しい概念ではなく、ランドのイラスト付きガイドの日本語訳で説明したような内容を、マット・カッツ氏がエリック・エンゲ氏によるインタビュー記事でおおっぴらに語っていた。
ただし、ここで大きな問題となるのは、グーグルがサイトをどのようにクロールしているかを把握する方法だ。これを測定するには多種多様な方法が存在するが(Webサーバーのログファイルを見るのは、わかりやすい解決策の一例)、僕がこれから概説するやり方は、専門知識がなくてもできる。必要なのは以下の3つだけだ。
- グーグルウェブマスターツールの認証済みアカウント
- Google Analytics
- Excel
この記事のゴール
この記事で紹介するやり方で作業すれば、次のような、カテゴリごとにクロール配分やトラフィックシェアを一覧した表を作れる。
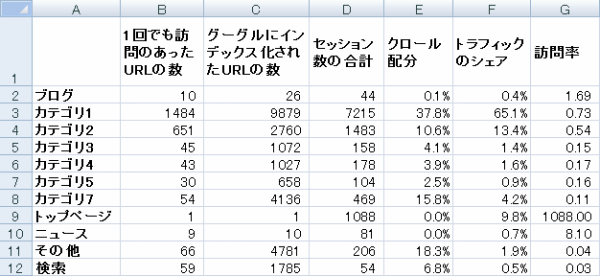
こうして整理すると、サイト内のどこがクロール量に対してトラフィックの価値が高い/低いといった問題をわかりやすくチェック/レポートできるようになるのだ。
ここで説明する方法ではなく、Webサーバーのアクセスログファイルを使う方法で行きたいなら、イアン・ルーリー氏の「how to read log files」(ログファイルの読み方)と「analysing log files for SEO」(SEOのためのログファイル分析)という2つの記事が役に立つかもしれない。
ただし、Googlebotがサイトをクロールしたからといって、必ずページがインデックスされるわけじゃないことは、指摘しておくべきだろう。これは変な話に思えるかもしれないけど、ログファイルを調べたことがあるなら、Googlebotが時に異常な数のページを訪問するのに、多くの場合そのページを実際にコピーしてキャッシュに保存するのは何回か訪問した後になる、ということに気づくだろう。だからこそ、これから紹介する、グーグルから訪問を受けたURLと、ウェブマスターツールから分かるサイト内リンクのあるページを、組み合わせて使う方法がかなり正確だと思う。とはいえ、ログファイルのデータを第3のデータとしてこの手順に組み込めば、もっとすばらしい結果が期待できるだろう(データが増えるのはいいことだ!)。
いずれにせよ、理屈はここまでにして、サイトの中でグーグルがクロールしているページを把握し、実際にトラフィックを獲得しているページと比較するにはどうしたらいいか、専門知識なしで実行できる手順を1つずつ見ていこう。
※Web担編注 原文でもコメントで指摘があり筆者も認めている点だが、この記事の解説は、Excelの扱い方に慣れている人向けになっている。日本語訳バージョンでは可能な限り補足を入れるようにしたが、「読んでそのとおり作業すればできる」解説にまではなっていないので、ご了承いただきたい。
[ステップ1] 内部リンクのデータをダウンロードする

これで、グーグルが内部リンクを把握しているページの表が手に入る。本記事ではこれ以降、このデータをグーグルのクロール数の概算として扱うことを留意してほしい。これについては記事冒頭の解説を参照してほしい。
僕の感触では、これはグーグルで「site:」を使った検索よりも正確だ。ただし、これには落とし穴もある。このレポートからわかるのはリンクが張られているページの数であり、グーグルがクロールしたページの数ではないからだ。それでもグーグルのインデックスを測定するのに悪い方法ではない。この方法が不正確になるのは、「rel=nofollow」付きのサイト内リンクや、(リンクを張っているのに)robots.txtでブロックされているページがたくさんある場合だけだ。
[ステップ2] Google Analyticsで閲覧開始ページのデータを取得する
このステップは、Google Analyticsを使っている人ならよく知っているはずだ。最近30日のオーガニックトラフィックレポートを開いて閲覧開始ページを表示し、データをダウンロードしよう。
留意すべきは、可能な限り多くのデータを入手できるよう、URLに「&limit=50000」を付け足してから「CSVとしてエクスポート」をクリックすべきだということ。ランディングページが5万以上ある場合は、対象の期間を狭くするか、より高度な方法を試してみよう(ログファイルを使う方法について述べた部分を参照してもらいたい)。
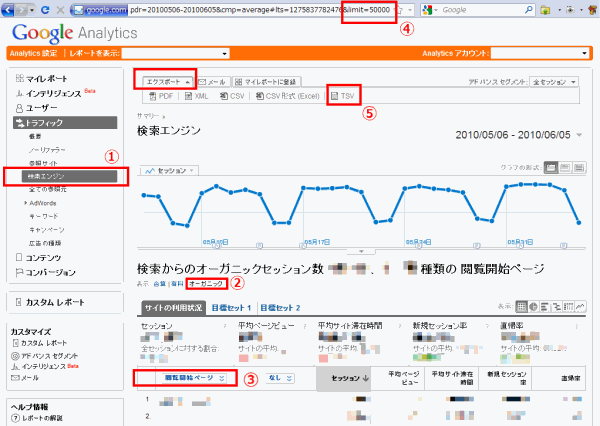
Google Analyticsの管理画面にアクセスしてからの作業の手順は次のとおり。
- [トラフィック]>[検索エンジン]を開く
- グラフの下にある「表示:」で「合算」となっている部分を「オーガニック」に変更する。
- 表の上の「参照元」になってるドロップダウンを「閲覧開始ページ」に変更する。
- ブラウザのURLバーの最後に「&limit=50000」を入れて[Enter]を押す(ページ表示は変わらない)。
- Google Analyticsのグラフの上にある[エクスポート]ボタンをクリックしてTSV形式でダウンロード(経験上、「CSV形式(Excel)」よりもこちらのほうがトラブルが少ない)。
- ダウンロードが完了したら、そのファイルの文字コードをShift-JISに変更して保存しておく。
関連記事
キーワード調査――カテゴリを使って実用性を高める(後編 Excelの配列数式を使ったデータ整理)
2011年9月5日 9:00
エクセルで頻出単語を自動抽出! 検索キーワードの分類・分析を簡単に
2012年6月5日 9:00
Google Analyticsの意外と知られていない便利な裏技5選
2010年6月28日 9:00
Google Analyticsで「ラストタッチ」以外のコンバージョン要因を調べよう
2010年3月8日 9:00
Google AnalyticsのイベントトラッキングでCTA(Call To Action)の効果を追跡
2010年6月21日 9:00
グーグル公認SEOガイドでGooglebotくんと学ぼう など10+3記事(海外&国内SEO情報)
2010年10月1日 10:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00

