テクニカルSEOをスッと理解できる! 元SEO初心者が生み出した18の身近なたとえ(前編)
「壊れたバス」から「モナ・リザ」まで、SEO学習に役立つ18の比喩を紹介。身近なたとえ話で、SEOを簡単に理解しよう。
2025年9月22日 7:00
SEO(特にテクニカルSEO)は専門用語が多く、学ぶ意欲があっても、あらゆることがどのように連携し合っているかを理解するのは難しい。学び始めたばかりの人であれば、圧倒されることがあるかもしれない。
2023年にテクニカルSEO担当のエグゼクティブとしてSalience Search Marketingに入社したとき、私にはテクニカルSEOの経歴がなかった。学習に役立てるため、私は複雑なSEOの概念を理解しようと比喩で視覚化した。これが私にとってこの仕事の意味を理解する手段となり、ひいては他の人に説明する手段にもなった。
これらのアナロジーは、次のような人たちにも有益だ:
- SEO初心者
- SEOを教えている人
- もっとうまく説明する方法が知りたい人
故障したバスから『モナ・リザ』をめぐる議論まで、私が初心者としてテクニカルSEOを理解するのに役立った比喩を紹介しよう。
ウェブサイト
初めて見るHTMLコードは少し難しそうに思えるかもしれないが、私は自分の役割をこなすほど、コードの背後にある論理や構造がわかるようになった。「ウェブサイトを家のようなもの」と考えるようになったことで、コードがより明白になった。
比喩1HTMLは家の基礎と骨組み

私はHTMLを、「すべてを結びつけるレンガや構造のようなもの」だと思っている。HTMLなくしてウェブサイトは存在しない。壁のない家がないのと同じだ。
比喩2CSSはデザイン

CSSは家を美しくする、次のようなものだ:
- 塗料
- 壁紙
- レイアウト
同じ構造の家でも、部屋ごとに異なる装飾にできる。HTML要素のスタイルを際限なくさまざまな方法で設定できるのと同じだ。
基本的なCSSはHTMLより読みやすい。たとえば、次のCSSを見てみよう。
body {
background-color: blue;
}
h1 {
color: yellow;
text-align: center;
}
これは、次のようにシンプルだ。
- ウェブページの色設定(HTML要素「body」のスタイル設定)
- 見出しの色設定と中央揃え(HTML要素「h1」のスタイル設定)
ちなみに、史上初のウェブサイトで、スタイルが設定されていないウェブサイトがどのように見えるかを確認してみよう。
比喩3JavaScriptで機能を追加
JavaScriptを使うと機能性を追加できるが、使いすぎると動作が遅くなることもある。私はこれを「音声アシスタント」「自動ロック」「モーションライト」など、テクノロジーを駆使したスマートハウスのようなものと考えている。うまく機能しているときはすばらしいが、故障するとイライラする。
JavaScriptを多用しすぎているウェブサイトは、次のようなことが起こりやすい:
- 読み込みが遅い
- ボットがクロールしにくい
- エラーが起こりやすい
シンプルな設定のほうが、うまく動作することが多いのだ。
比喩4CMSとフレームワークは、IKEAの家具のようなもの

WixやShopifyなどのプラットフォームを利用すれば、コードを書かなくても機能的なサイトを簡単に構築できる。これがCMSだ。
まるでIKEAの家具のようなものなもので、正しく組み立てる必要はあるが、難しい作業はすでに済んでおり、すべてをゼロから構築することはないのだ。
クロール、インデックス化、リンク構造
検索エンジンには、指定されたキーワードに対する検索結果を表示する表のシステムだけでなく、そうした検索を実現するための裏側のシステムがある。検索エンジンがウェブサイトを見つけ、ページをたどっていき、内容を理解するためのものだ。
私はこれらのシステムについて学び始めたとき、次のような現実世界の概念で考えたほうがわかりやすいと思った:
- 公共交通機関
- 地図
- 交通ルールなど
比喩5サーバーのレスポンスコードはバスの状況で理解
レスポンスコード(HTTPレスポンスコード、404や403などのこと)について初めて知ったとき、私は公共のバスの運行状況をイメージしながら理解していった。

200 OK: バスが到着し、目的地まで連れて行ってくれる。
→ページは問題なく読み込まれる301 Moved Permanently: バスの路線が変更されたが、目的地には到着する。
→URLが新しいURLにリダイレクトされる302 Found: 一時的な回り道のようなもの。目的地には到着し、路線は後で元に戻る。
→URLが新しいURLにリダイレクトされる(一時的)403 Forbidden: バスの乗車券は持っているが無効。
→URLへのアクセスが拒否される404 Not Found: バスが来ない。
→URLはもはや存在しない410 Gone: バスの路線が永久に廃止された。
→このURLのコンテンツは永久に削除された。500 Internal Server Error: バスが故障した。
→サーバーで何らかの問題が発生した。503 Service Unavailable: バスが満員か、メンテナンス中。
→サーバーがビジー状態か、オフラインになっている。

写真提供:アレックス・ハーフォード氏
比喩6サイト内リンクは都市の交通網のようなもの
ウェブサイトを都市と考えてみよう。トップページはロンドンのような中心的ハブだ。そこから他の地域に行くには、次のようなもの必要になる:
- 道路
- 電車
- フェリー
- など
サイト内リンクも同様に、ユーザーやボットがページ間を移動するのに役立つ。簡単にアクセスできるページもあれば、直接リンクがなければほぼ見つけられない“離島”のようなページもある。
比喩7リンク切れは行き止まり
リンク切れは、袋小路に行き当たるようなものだ。ユーザー(または検索ボット)は引き返さなければならず、不満が生じ、信頼が損なわれる。これは必ず修正しておく必要がある。
比喩8アンカーテキストは道路標識

アンカーテキストは、リンクのクリック可能な部分であり、移動先の場所について説明する。説明的なアンカーテキストは、道路標識が場所を示すのと同じように、ユーザーやボットが次に何が表示されるかを把握するのに役立つ。
比喩9XMLサイトマップは検索ボットのToDoリスト
サイトマップ(人間向けではなく検索エンジン向けのもの)は、「検索エンジンにクロールしてほしいすべての重要なURLの一覧」だ。私はこれをToDoリストのようなものだと考えている。大事なことは忘れないように書き留めておく必要がある。検索エンジンはサイトマップを使って重要なコンテンツを確実に把握できる。
比喩10robots.txtはナイトクラブのID確認
robots.txtファイルでは、検索エンジンボットが「アクセスできるコンテンツ」と「アクセスできないコンテンツ」を指定する。これはナイトクラブで身分証明書(ID)を確認されるようなものだ。
ボットによってはアクセス禁止の領域がある。ただし、現実世界と同じように、すべてのボットがルールを守るわけではない。
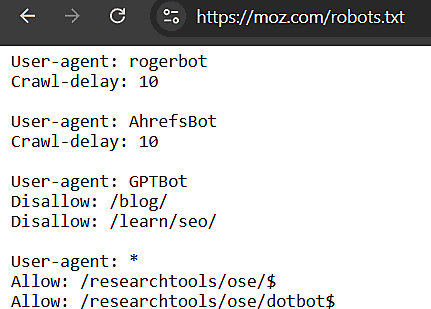
例として、検索エンジンのクローラーに対する指示が記述されているMozの/robots.txtを見てみよう。次のような内容だ:
比喩11ユーザーエージェントは偽のID
人が使っているブラウザであれ検索エンジンのボットであれ、すべてのサイト訪問者は自分の情報を伝える「ユーザーエージェント名」を持っている。SEO担当者は時に、検索エンジンが何を見ているかを確認するために、これらのユーザーエージェント名を偽装してGooglebotであるかのように見せかけてサイトにアクセスすることがある。これは、VIPエリアに入るために偽のIDを使うようなものだ。

Mozのrobots.txtファイルでは、次のような記述でChatGPT用のユーザーエージェント名「GPTBot」に対してクロール禁止を指示している。
# /blog/ と /learn/seo/ でGPTBotをブロック
User-agent: GPTBot
Disallow: /blog/
Disallow: /learn/seo/
ボットによっては、偽のユーザーエージェント文字列を使ってrobots.txtを無視するものもあり、この手口はユーザーエージェント偽装と呼ばれている。偽のIDのようなものだ。さらに身元を隠すために、IPアドレスやサーバーの設置場所を偽装するボットもある。
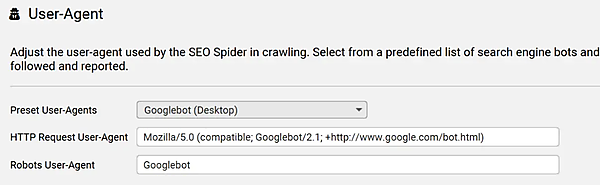
私はこの方法を使い、「Screaming Frog SEO Spider」で「Googlebot」を偽装しているので、クロールの結果はグーグルが見ている内容に近いものになる。
この記事は、前後編の2回に分けてお届けする。後編となる次回では「レンダリングとページ体験」「ウェブサイトのテンプレートページ」「サイト移行と品質保証」「URL正規化と重複コンテンツ」について、身近なものにどうたとえるかを説明する。
- この記事のキーワード
関連記事
SEOを「身近なもの」にたとえたら? 初心者のテクニカルSEO理解に役立つ18の比喩(後編)
2025年9月29日 7:00
SEO監査に有効な「Googlebotブラウザ」の必要性(前編)
2025年4月7日 7:00
内部リンクが多いほど検索トラフィックが多い!? 1800サイト調査から判明した検索トラフィックと内部リンクの相関関係【SEO情報まとめ】
2022年6月17日 7:00
スマホ向けサイトの最適化レベルを自動チェックするグーグル公式ツール2種 など10+3記事
2014年11月28日 8:00
誰も語ろうとしないAIのダークサイドと、LLMクローラーのログ活用法(前編)
6月22日 7:05
SEO施策はAIにも有効? サーバーログが示すAIクローラーの挙動と、疑問に答えるAI×SEO一問一答
4月23日 7:05
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「18 Real-Life Analogies to Explain SEO to Anyone」 by Jasmine Hall (2025/06/05)
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




