サイトの著者情報がグーグルに正しく認識されているかを一括で自動チェックするためのクイックガイド
Screaming Frog SEO Spider Toolを使って、グーグルが著者情報をどう認識しているかまで自動チェック
2014年3月3日 9:00
著者情報マークアップ(Authorship Markup)をページのHTMLに加えておくと、グーグルの検索結果ページに表示される際に、Google+のアカウント情報による著者情報が、検索結果内に表示される可能性が出る。
しかし、その著者情報マークアップが正しくできているかどうか、いちいち構造化データテストツールで調べるのは面倒だ。
この記事では、グーグルが著者情報マークアップをどう認識しているかまでのチェックを自動化する方法を解説する。

うちの会社ではほぼ全社員が、ウェブサイトのクロールに「Screaming Frog SEO Spider」というツールを使ってきた。読者の多くも多分、グーグルの構造化データテストツール(以前の名称はリッチスニペットツール)を使って、自分の著者情報(オーサーシップ)の設定などの構造化データをテストしたことがあるだろう。
今回のクイックガイドでは、この2つのツールを組み合わせて、Google Authorshipやrel="publisher"、それに各種のSchema.orgマークアップといった構造化データについて自分のウェブサイト全体をチェックする方法を説明していく。
コンセプト
グーグルの構造化データテストツールは、テスト対象として入力されたURLをグーグル独自のURLに変換して使用する。たとえば、こんな感じだ。
- 次のURLをテストツールに入力すると……:
http://www.contentharmony.com/tools/ ……テストツールは次のURLを吐き出す:
http://www.google.com/webmasters/tools/richsnippets?q=http%3A%2F%2Fwww.contentharmony.com%2Ftools%2F&html=
このURL構造を利用して、構造化データマークアップをテストしたいURLのリストを作成し、Screaming Frogでそのリストを処理できるのだ。
なぜこの方法が、単に自サイトをクロールしてマークアップを検出するより優れているのか
もちろん、自分のサイトをクロールして、その結果に対してScreaming Frogのカスタムフィルタを使い、サイトのコードに含まれる「rel="author"」や「?rel=author」といったフレーズが適切に使われているかどうかをチェックする方法もある。
しかし、今回説明する方法では、実際にグーグルが認識しているものを調べられる。そこから、著者情報などのマークアップの実装におけるエラーも検出できるわけだ。
免責事項:「構造化データテストツールが著者情報の実装がちゃんとできているのに、検索結果で著者情報のスニペットがうまく機能してない」という事例に、僕は何度も遭遇してきた。検討を重ねた結果、この問題は実装方法を変更することで解決した。ほかにも、特定のGoogle+ユーザーに対して著者情報の閲覧が許可されなかったり、表示されななかったりすることもある。結論として、注意すべき重要なポイントは、構造化データテストツールは完璧ではなく、ポジティブな結果を誤って出すということだ。それでも、一度に多数のURLを素早くテストするこのケースでは、われわれのニーズに合致している。
開始する
開始するために必要なものは以下のとおりだ。
Screaming Frogの有料ライセンス(これから使うカスタムフィルタは有料版でのみ利用可能)
Excel 2013、URL Tools for Excel、SEO Tools for Excel のいずれか1つ(この3つはいずれも、数式を使ってURLをExcel内でエンコードできる)
クイックXLSXテンプレートをダウンロードする:Excel Template for Screaming Frog and Snippet Tester.xlsx
これは、Screaming Frogおよびスニペットテストツール用のExcelテンプレートだ
ステップ1~3:ExcelテンプレートにURLのリストを集約する
Excelテンプレートの中で詳細な手順を読めるが、ここではExcelテンプレートの使い方をシンプルな3ステップで説明しよう(このファイルを開く前に、必ずURLツールやSEOツールをインストールしておくこと。そうしないと、後で数式を修正しなければならなくなる)。
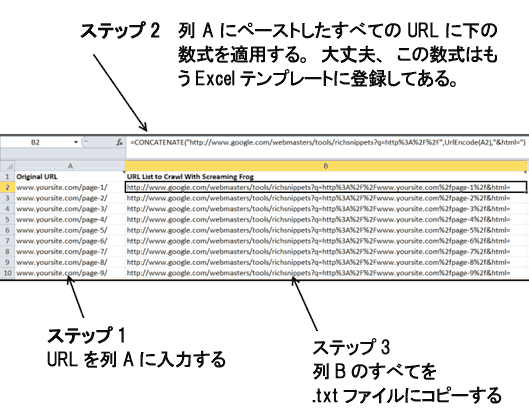
ステップ4:列BのすべてのURLを.txtファイルにコピーする
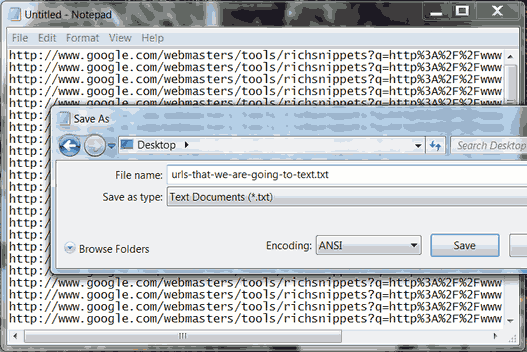
これで、スプレッドシートの列BにクロールすべきURLがずらりと並んだ。この列をコピーしてテキストファイルにコピーすると、1行に1つのURLが入ったテキストファイルができる。これがScreaming Frogのリストモードで使用する.txtファイルだ。
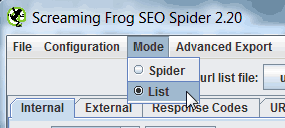
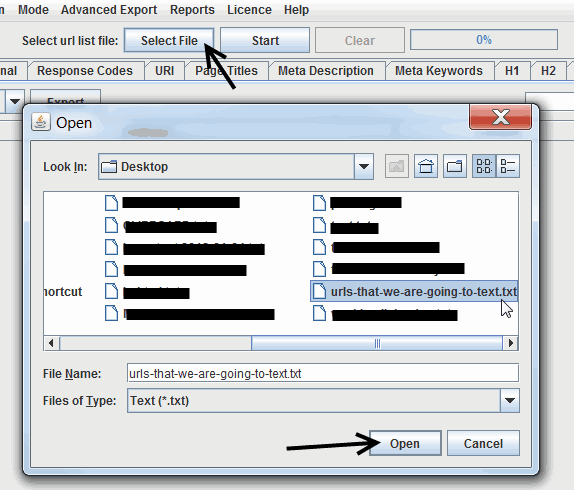
ステップ5:Screaming Frogを開き、リストモードに切り替えて、ファイルをアップロードする
ステップ6:Screaming Frogのカスタムフィルタを設定する
ここで重要なポイントだ。準備したURLすべてのクロールを始める前に、構造化データテストツールから特定のレスポンスを検出できるように、カスタムフィルタをScreaming Frogに設定しておく。
この例では著者情報についてテストするので、Screaming Frogに追跡させたいテキストは以下のとおりだ。
作成者情報はこのウェブページで機能しています。
rel=authorマークアップによってこのウェブページの作成者情報が正常に設定されました。
ページには著者情報のマークアップは含まれません。
作成者情報はこのページで機能していません。
要求したサービスは現在利用できません。
これらのテキストをScreaming Frogに入力すると、フィルタは下図のようになる。
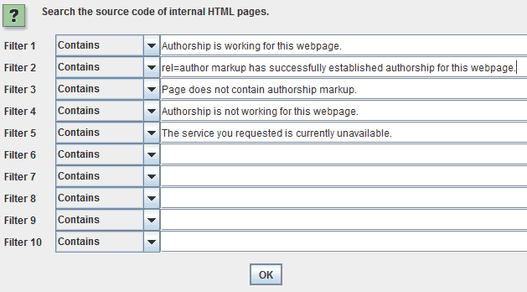
ここで、僕らが追跡する各テキストの意味を明確にしておこう。
第1のフィルタは、ページ上のテキストをチェックして、著者情報が正しく設定されていることを確認する。
第2のフィルタは、フィルタ1と同じ情報を報告する。両方のフィルタを加えるのは、冗長化を図るためだ。フィルタ1と2では、まったく同じページのリストが取得できるはずだ。
第3のフィルタは、構造化データテストツールでページ上の著者情報が見つからなかった場合、そのことを検出する。
第4のフィルタは、著者情報の破損を検出する(これはたいていの場合、リンクが間違っているか、そのGoogle+ユーザーがプロフィールの「寄稿先」セクションにドメイン名を追加していないかのどちらかが原因だ)。
第5のフィルタは、構造化データテストツールの標準的なエラーテキストを含む。これが検出されたURLについては、もう一度精査すべきことがわかる。
以下に、構造化データテストツールで検出されるテキストの一例を示した。

ステップ7:クロールを実行する
この段階で、URLのクロールを始める準備は整った。
グーグルのサーバーに敬意を払うとともに、この方法によるURLクロールが禁止されることを回避するために、クロール速度を遅めに調整することを考えた方がいいかもしれない。規模の大きいサイトであれば特にね。
この設定は、Screaming Frogのメニューで[Configuration]>[Speed]に進み、現在の設定値を下げることで調整できる。
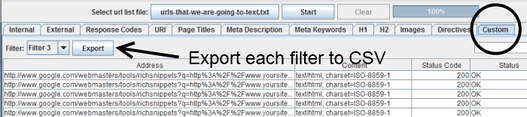
ステップ8:結果をCustomタブにエクスポートする
クロールが終了したら、[Custom]タブに進み、テストした各フィルタを選択して、結果をエクスポートする。
動画チュートリアル
この8つのステップを流れにそって解説している短い動画チュートリアルもある。わからない場合はこちらも確認してみてほしい。
まとめ
ここまで駆け足でざっと説明してきた。
エクスポートした各CSVファイルは、設定したフィルタをファイル名として保存するといいだろう。たとえば、僕のフィルタ3は「ページには著者情報のマークアップは含まれません」というフレーズを含むページのテストだ。そこで、「フィルタ3」というファイル名でエクスポートされたファイルには、構造化データテストツールによって著者情報が一切返されなかったURLが保存されていることがわかる。
このコンセプトを拡張する4つの方法
①複数の著者に関するデータを引き出すために、適切なスクレイパーを使う
Screaming Frogは、このガイドで説明したようなクイックチェックを行うには手軽なツールだが、残念ながら本当の意味でのスクレイピングには向いていない。
この方法を使って、あるページで誰が著者として確認されているかといったデータも引き出したいなら、このコンセプトをOutwit Hubで使えるよう手直しするのがおすすめだ。SEOGadgetのジョン・ヘンリー・シャーク氏がOutwitを使って基本的なスクレイピング作業を行う方法についてすばらしいガイドを書いているので、Outfitを使ったことのない人はこれを読んでもらいたい。
もっとテクニカルにやりたい人向けに、この種の作業を処理できるスクレイパーはこれ以外にもたくさんある。重要なのはプロセスを理解することなので、自分好みのツールを使うといい。
②検索順位に対する著者情報テストと検索ボリューム概算値を比較し、改善の機会を見つける
たとえば、検索ボリュームの大きいキーワードで検索順位が3位になっていて、著者情報がページにないとしよう。賭けてもいいが、このページには時間をかけて著者情報を追加する価値がきっとある。
ExcelでHLOOKUP関数またはVLOOPUP関数を使って、3つのタブからのデータを比較しよう。3つというのは、次のものだ。
- 検索順位
- 検索ボリューム概算値
- 当該ページ上の著者情報の有無
若干のデータ操作が必要になるが、最終的には、著者情報を持つページを除外し、検索ボリューム概算値と現在の検索順位でページを並べ替えたピボットテーブルを作成できるはずだ。
③この方法を使って、著者情報以外の構造化マークアップをテストする
構造化データテストツールは、著者情報以外のテストにも威力を発揮する。このツールは、次のような構造化マークアップのテストにも使える。
以下の各リンクは、いずれも構造化データテストツールへのリンクだが、さまざまな構造化マークアップがツールでどう表示されるかを把握できるようにしてある。
schema.orgやdata-vocabulary.org、および類似したマークアップを参照するすべて
④このアイデアをScreaming Frogの他の機能と組み合わせる
Screaming Frogには、多種多様な使い方がある。SEERのアイシュリー・ブッシュネル氏は、55通り以上あるScreaming Frogの使い方という優れた記事で活用例を集めた。記事をチェックすれば、このコンセプトから実用的なものを生み出す方法をいくつか考えつくはずだ。
さえない注意書きで締めるわけじゃないが、3つのトラブルシューティングを示しておこう。
うまくいかない場合、まずやるべきなのは、送信したURLを手作業でテストし、Excelの各ステップで問題がないかどうかを確かめることだ。また、ページが正しくロードされていることを確認するために、カスタムフィルタの項目に「無効なURLであるか、ページが見つかりません。」を追加してもいい。
大量のURLについて作業する場合は、ごく短い時間に大量のクエリを行ってグーグルに負担をかけたりしないよう、Screaming Frogのクロール頻度をおとなしめにする方がいいだろう。
最初にExcelテンプレートを開くと、URLツールまたはSEOツールをすでにインストール済みかどうかによって、式が誤って変更されてしまうことがある。その場合、1ページ目の手順を読んで、正しい式を見つけて置き換えよう。
- この記事のキーワード
関連記事
301リダイレクトを整理して、サイトの読み込み時間を改善する
2016年8月1日 7:00
グーグルのSGEが検索トラフィックに与える影響を算出する方法(無料のテンプレートあり)【後編】
2024年4月1日 7:00
どの構造化データをWebサイトのどこに入れるのがいい? 5つの設計手順で大規模サイトでもOK!
2019年11月11日 7:00
【検索結果のCTR改善】SEOでスニペットを最適化する8つの方法
2022年5月23日 7:00
謎だらけのSEOテクニカル問題を解決する8つのポイントとは? 【前編】あなたのページがなぜインデックスされないかを把握しよう
2018年10月22日 7:00
SEO×AI グーグルのSGEがオーガニック検索トラフィックに与える影響とは?【前編】
2024年3月25日 7:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00





