あなたも同じミスをするかも? robots.txtのミスで予想外のページをクロール禁止していた悲劇【SEO情報まとめ】
最強級のSEOと最上級のコンテンツすら台無しにする、robots.txtの予想と違う挙動を、あなたは知っているだろうか? 知らなければうっかりハマってしまうかも
2022年11月4日 7:00

最強級のSEOと最上級のコンテンツすら台無しにする、robots.txtの予想と違う挙動を、あなたは知っているだろうか? 知らなければうっかりハマってしまい、「コンテンツがインデックスされない!」となってしまうかも。
「実際の挙動の根拠は?」「どうすればこの落とし穴を避けられるの?」を含めて、詳しく解説する。
ほかにも、モバイル検索でのサイト名表示や、SERPでのCTR向上事例、Google検索にとってのAIの意味などなど、今回はちょっと濃いめのSEOトピックをお届けする。
- グーグルのモバイル検索でサイト名が表示されるようになった
- スニペット改善でCTR向上・検索トラフィック約2倍に⬆UP!
- 2022年10月のスパムアップデートをグーグルが実施
- 10月のグーグルオフィスアワー: サイトマップのlastmod、MFIに移行しない、サイト名が表示されないなど
- 人間が書いたコンテンツをグーグルがスパム判定するのは間違い?
- 【SEOクイズ】noimageindexタグとmax-image-preview:noneタグの違いは?
- ECサイトの在庫切れページで204を返すのは正しいやり方か?
- Search Consoleの検索パフォーマンスの制限をグーグルが解説
- 現在の Google検索における機械学習の重要性とは?
- Googleマルチサーチが日本語環境にやってきた
- Google画像検索で写真のクレジット情報を構造化データで指定できるように
今週のピックアップ
あなたも同じミスをするかも? robots.txtで予想外のページをクロール禁止していた悲劇
robots.txtテスターで確認する (辻正浩 on ツイッター) 国内情報
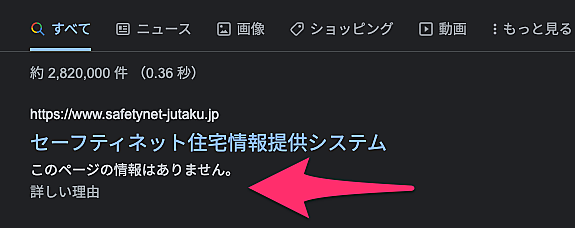
あるサイトのrobots.txt構成ミスをso.laの辻正浩氏が発見した。トップページをグーグルがクロールできないため、スニペットが表示されなくなっているのだ。
もちろん、サイト管理者はトップページのクロールを禁止したかったわけではないはずだ。原因はrobots.txtの記述にあったようだ。
あるrobots.txtの書き方のせいで、管理者が想定していないページをクロール禁止することになっていたのだ。しかし、その挙動は非常にわかりづらく、だれでも同じミスをしてしまいかねないものだった。
結論から言うと、robots.txtでのCrawl-delay指定が原因だった。これはクロール速度を制限する命令として使われているが、実は標準仕様としては定められていない命令だ。
そのため、Crawl-delay指定を無視する検索エンジンもある。Googlebotもその1つなのだが、問題はGooglebotがCrawl-delayを指定している部分は無視する、つまり空白行として扱うことだった。
どういうことか解説しよう。
あなたの予想とは違うGooglebotのrobots.txt解釈
辻氏が発見したサイトが設置しているrobots.txtには、Googlebotが処理しないCrawl-delayがあった。GooglebotがCrawl-delayを処理しないだけなら問題は起きなかったのだが、Googlebotは「その命令が書かれた行をないものとして扱う」ため、前後のUser-agent指定の関係上、その後に出てくるクロール拒否の指定が自分に向けた指示だと解釈してしまったのだ。

つまり、Googlebotにとってのrobots.txtは次のようになる:
User-agent: *
Disallow: /guest/
Disallow: /content //content / に含まれているスペースも誤りか?解説では「GooglebotはCrawl-delayの行をないものとして扱う」としたが、実際にはGooglebotの挙動は「Allow、Disallow、User-agent以外の行をないものとして扱う」というものだ。そのため、sitemap指定も同様に「ないものとして扱う」動きをする点に注意してほしい(今回の事例では利用していないようだが)。
このサイトでさらに事態を悪化させたのはリダイレクトだった。トップページ (/) から /guest/ へ302リダイレクトしているのだ。
302リダイレクトを、グーグルは次のように扱う:
- 検索結果にはリダイレクト元のURL (
/) を表示 - インデックス対象のURLは
/guest/(robots.txtでブロックしているURL)
robots.txtでブロックしているURLでも、リンクなどの状況により検索結果に掲載されることがある。ところが、/guest/ はクロールをブロックされているためGooglebotはページの中身を見ることができない。
結果としてスニペットを生成できず、冒頭のキャプチャで見せたような結果になってしまう。
解決策(根本)robots.txtにDisallow/Allow以外を書くときは下に書く
robots.txtの修正案はいくつかあるが、いちばんのオススメは「ファイル全体の構成を変える」ことだ。
具体的にはファイル全体の構成として、まずDisallowとAllow関連の指定を行い、Crawl-delay関連の指定はその後にもってくる形にするのだ。
#-----------------------------------------
# Disallow・Allow系の指定をこの下に置く
#-----------------------------------------
User-agent: Bingbot
Disallow: /guest/
Disallow: /content /
……
#-----------------------------------------
# Crawl-delayの指定をこの下に置く
# このブロックにはDisallow系の指定は一切記載しない
#-----------------------------------------
User-agent: *
Crawl-delay: 10
User-agent: Bingbot
Crawl-delay: 120
……元のファイルではUser-agent単位でブロック分けして記述していたが、全体構成を変える形だ。
前述のように、Googlebotの挙動は「Allow、Disallow、User-agent以外の行をないものとして扱う」というものだ。そのため、ファイル全体を
Disallow・Allow系- それ以外(
Crawl-delay系や、必要ならばSitemap系)
で大きく2つのブロックに分け、それぞれのブロック内でUser-agentごとに命令を記載していく。
同じUser-agent指定を複数のブロックに分ける必要がでる手間はかかるが、こうすれば、Googlebotの「行をないものとして扱う」挙動がDisallow/Allowに影響することはなくなる。
解決策(暫定)とりあえず対応も可能
とはいえ、robots.txt全体を書き換えるのは面倒ではある。
暫定的な対処法としては、次の3種類どれかの記述をrobots.txt内に置くだけでも、問題は解決する(robots.txt内のどこに記述してもいい)。
User-agent: Googlebot
Disallow:User-agent: Googlebot
Allow: /User-agent: Googlebot
Disallow:
Allow: /guest/
Allow: /content /ただし、この対処はあくまでも暫定的なものだ。将来、robots.txtをさらに修正したときに副作用で同様の問題が発生する可能性が残っている。
robots.txtの修正後は必ずテスト!
辻氏が指摘するようにrobots.txtの仕様は実際には難解だ(仕様どおりの挙動ではあるのだが)。いま一度ドキュメントを読み返したい(特に「ルールのグループ化」以降の部分が重要だ)。
さらに言えば、robots.txtを編集したときにはrobots.txtテスターで想定どおりの挙動になっているかを必ず確認するのは必須だ。常にテストすることを癖にしよう(robots.txtはめったに編集するものではないが)。
よくあるrobots.txtの誤りで、致命的なトラブルになる事もあるのにあまり知られていない仕様の紹介で連ツイート。
— 辻正浩 | Masahiro Tsuji (@tsuj) October 29, 2022
誤りは表に出ることが少ないので日本語で実例紹介を見たことが無いのですが、公共の面も持つサイトでの誤りを発見したので注意喚起意図で実例を紹介します。(続く
続き)住宅セーフティネット法に基づき公開されたサイトの指名検索結果ではrobots.txtでブロック時の表示です。おそらくサイト管理者が意図していない挙動です。
— 辻正浩 | Masahiro Tsuji (@tsuj) October 29, 2022
公開されているrobots.txtを見て、なぜトップページがブロックされるか分かりますか?考えてみてください。https://t.co/c4nTu9qO59
(続く pic.twitter.com/Y3YB8LGcF8
続き)正解です。
— 辻正浩 | Masahiro Tsuji (@tsuj) October 29, 2022
左のrobots.txtでは一見ブロックをしていませんね。
ただ、Crawl-Delayの指示はGoogleは未対応ですので行自体を全て無視します。そのためGoogleから見ると右のような状態なのです。
右の状態ではすべてのUAを含むグループのbotは/guest/をdisallowしています。(続く pic.twitter.com/su0YzXPNBM
続き)そしてこのサイトは、トップから302で/guest/index.phpに飛ばしています。/guest/はブロックですのでトップがindexに残りつつクロールは出来ない状態となります。
— 辻正浩 | Masahiro Tsuji (@tsuj) October 29, 2022
以上、トップページがrobots.txtでブロックされている挙動になる理由でした。
(続く
続き)Web制作の方はこういう挙動を知らない方が多いのではないでしょうか。SEO屋でも知らない人が多いかと思います。
— 辻正浩 | Masahiro Tsuji (@tsuj) October 29, 2022
robots.txtは重要です。他にも地雷はたくさんあります。書くときには「robots.txtテスター」で意図どおり認識しているか十分に確認しましょう!
(続く
続き)
— 辻正浩 | Masahiro Tsuji (@tsuj) October 29, 2022
Googleのrobots.txtテスターの解説はこちらです。https://t.co/vSsc3galmt
私もrobots.txtを確認するときや実際に書くときには、このテスターでかなり洗います。
robots.txtは気軽に扱われがちですが重要です。1文字のミスで検索流入の大半を失うこともあります。ご注意ください。
(続く
- ホントにSEOを極めたい人だけ
グーグル検索SEO情報①
グーグルのモバイル検索でサイト名が表示されるようになった
知名度があるサイトはクリックが増えるかも (グーグル 検索セントラル ブログ) 国内情報
グーグルは、モバイル検索結果の各項目にサイト名を表示し始めた。日本語ほか英語、フランス語、ドイツ語のモバイル検索でまず導入された。
さまざまな情報からグーグルはサイト名を取得するが、主に利用する要素は次の 4つだ:
WebSite構造化データ<title>要素内のコンテンツ<h1>要素などの見出し要素og:site_name
認知度が高いサイトにはクリック率に良い影響が出るかもしれない。自分のサイトでサイト名が適切に表示されているかどうかをチェックしよう。もし不適切なサイト名が表示されているのであれば、先に挙げた4つの要素がどうなっているかを確認するといい。
特に、WebSite構造化データによるサイト名の指定をグーグルは推奨している。WebSite構造化データのマークアップに関する詳細は技術ドキュメントを参照してほしい。
※筆者補足: さらに確実性を期すために、構造化データなど4つの要素で指定するサイト名に一貫性を保つべきだ。
なお、サイト名はドメイン名単位で決まり、サブドメインやサブディレクトリ単位では設定できない。
サブドメインで運用するサイトでは通常、サイト名としてサブドメインの文字列が表示される。サブディレクトリではトップページに設定されたサイト名が表示される。
- www.example.com ―― サイト名を表示
- example.com ―― サイト名を表示
- example.com/blog ―― example.comのサイト名を表示
- www.example.com/blog ―― www.example.comのサイト名を表示
- blog.example.com ―― サイト名として「blog.example.com」を表示
- すべてのWeb担当者 必見!
スニペット改善でCTR向上・検索トラフィック約2倍に⬆UP!
tableタグとハウツーリッチリザルトを設定 (JC Chouinard on Twitter) 海外情報
検索結果のスニペットを改善してCTR(クリック率)と検索トラフィックを上昇させたケーススタディを、あるサイト管理者がツイッターで共有した。
まず、こちらは改善前のスニペットだ。特に何も設定していない標準的なスニペットだ。

スニペットの改善は、次のステップで行ったそうだ。
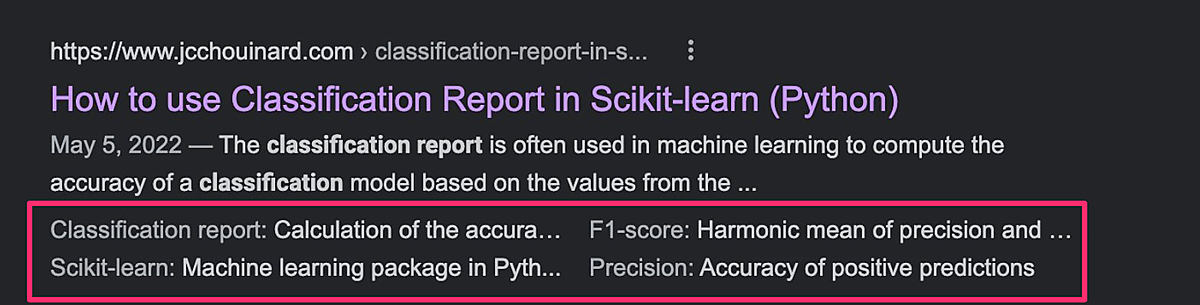
記事本文内でHTMLの
tableタグを使って情報を記載し、スニペットに表形式で情報を表示※筆者補足:tableタグ内のデータはスニペットに表形式で表示されやすい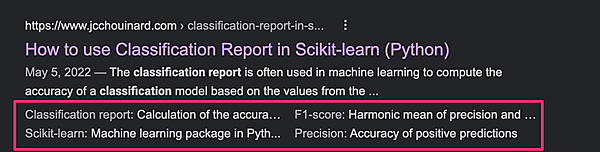
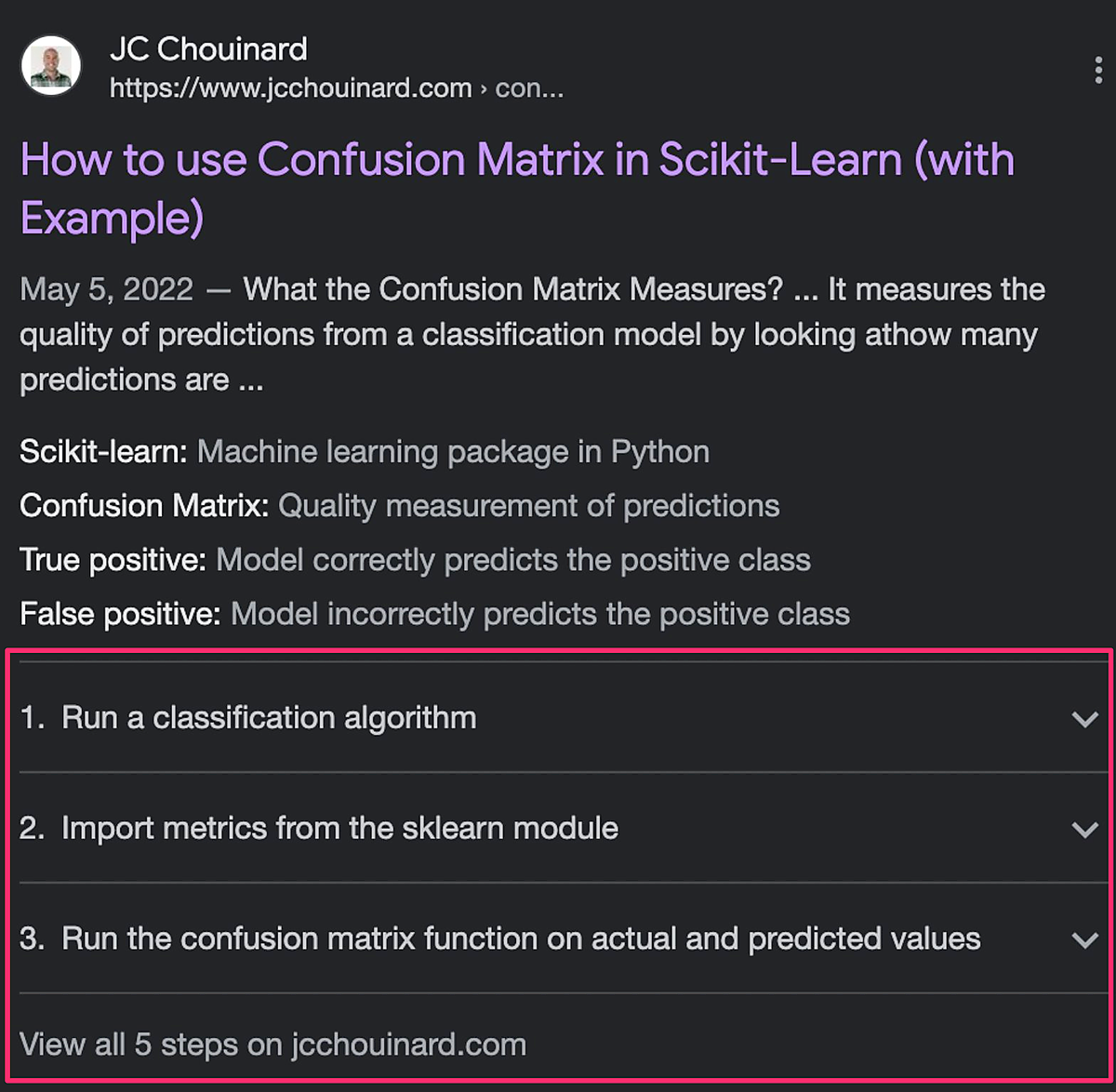
ページのHTMLに
HowTo構造化データを追加して、スニペットにハウツーのリッチリザルトを表示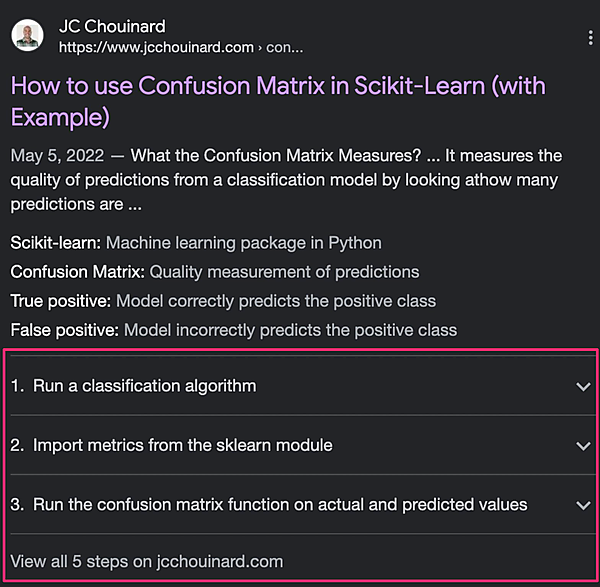
さらに、ハウツーのリッチリザルトに画像を追加
 画像がつくとハウツーがリスト形式ではなくカルーセル形式で表示される
画像がつくとハウツーがリスト形式ではなくカルーセル形式で表示される

改善後には、実際にCTRが上昇している。3%~4%程度だったCTRが5%~6%にまで良くなっていることがグラフからわかる。
Improving CTR is a great #SEO tactic for search results where ranks are good 🧵 pic.twitter.com/6v8sn76enc
— JC Chouinard (@ChouinardJC) October 25, 2022
CTRが上がったため、検索結果のクリック数も増えている。倍近い検索トラフィックを獲得していることがグラフからわかる。
5. Reap the benefits pic.twitter.com/r7wZU1PsRm
— JC Chouinard (@ChouinardJC) October 25, 2022
掲載している情報と相性がよさそうならば試す価値がありそうなスニペット改善施策だ。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
2022年10月のスパムアップデートをグーグルが実施
さまざまなタイプの検索スパムが排除された模様 (金谷 武明 on ツイッター) 国内情報
スパム対策を目的としたアップデートを、グーグルは2022年10月19日(太平洋時間)に実施した。検索セントラルのツイッターアカウントによる英語でのアナウンスを、日本語で金谷氏がリツイートしてくれた。
本日、October 2022 Spam Update をリリースしました。 アップデートの詳細はこちらでご確認ください。https://t.co/bGHuiT2JEU
— Takeaki Kanaya ★ 金谷 武明 (@jumpingknee) October 19, 2022
ロールアウトが完了しましたら、ランキングに関する更新情報のリリース履歴を更新し、お知らせします。 https://t.co/5FUBWII7wx
Google 検索ランキングの更新内容のリストにもアップデートは記録されている。リストによれば、2日後の21日(同時間)に展開は完了している。
今回のスパムアップデートが検索結果に及ぼした変化を、米国で名高いコンサルタントのグレン・ゲイブ氏は次のように分析している:
広範囲にわたって影響を与えているわけではないが、影響を受けたサイトには厳しい順位下落が起きている。対象になったスパムの種類は多岐にわたっている:
- 薄っぺらいコンテンツ
- (おそらくAIで生成された)低品質なコンテンツ
- リンクスパム
- コピーコンテンツ
- などなど
Quick update on the Oct Spam Update, definitely not widespread impact, but for those impacted, it was severe. When checking the sites with big drops, I came across a # of issues ranging from thin content, low-quality AI-content (I think), some link spam, stolen content, & more. pic.twitter.com/MAHRGdnfjr
— Glenn Gabe (@glenngabe) October 23, 2022
前回のスパムアップデートは、約1年前の2021年11月だった。このように、グーグルは検索スパム対策への取り組みを常に続けている。
今回グーグルの監視をすり抜けたスパムサイトも、いつかは見破られ大打撃を受けるだろう。さらには、アルゴリズムによる対策をそれでも巧みにくぐり抜けたとしても、次は、スパムチームの人間による目視が控えている。スパムに明るい未来はないのだ。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
10月のグーグルオフィスアワー: サイトマップのlastmod、MFIに移行しない、サイト名が表示されないなど
2回分をまとめて紹介 (グーグル ポリシー オフィスアワー on YouTube) 国内情報
グーグル社員によるオフィスアワーの10月の配信を紹介する。2回分だ。金谷氏と小川氏が回答した質問は次のとおりだ。
1回目(10月13日開催)
検索関連の質問
- 「広告に関する問題レポート」導入時期(1:07)
- Google サイトのサーチコンソール所有権確認(2:04)
- Sitemap.xml の lastmod(更新日)(2:56)
- サイトを無断転載された(5:18)
- メディアサイトが MFI に移行しない(9:09)
- ウェルカムバナーの推奨実装方法(12:29)
- サイトがインデックスされない(18:19)
パブリッシャーポリシー関連の質問
2回目(10月27日開催)
検索関連の質問
タイムスタンプにはその場所から再生が始まるようにリンクしてある。気になる質問の回答だけをチェックするのもいいだろう。
検索またはパブリッシャーポリシーに関して質問や相談があれば、こちらのフォームから送っておこう。今後のオフィスアワーで回答してもらえる。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
- この記事のキーワード
関連記事
検索避けの方法|Googleで表示・検索・アクセスされないようにしたい
2021年12月10日 7:00
グーグル検索でインデックスされない! そんなあなたに対処法の指南書をどうぞ【SEO情報まとめ】
2023年4月7日 7:00
HTTPS移行のよくあるQ&A 13連発。順位は? インデックスは? 作業は? などSEO記事まとめ10+3本
2016年2月5日 7:00
【Google公式】英語版SEOオフィスアワーの最新TIPS特集: ページ分割・サイトマップ・title・リダイレクトなどなど【SEO情報まとめ】
2023年1月20日 7:00
コロナ対策で飲食店・食品・小売・学校が #いまできること をグーグルが支援【SEO情報まとめ】
2020年4月24日 7:00
令和のグーグル検索では、広告を出していても検索順位は上がりません!【SEO記事12本まとめ】
2019年4月26日 7:00
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00




