「SEO」と「SPA/PWAによるUX向上」を両立させるハイブリッドレンダリングの基礎知識と実現手法
前編を読んで最新ウェブ技術の入り口に立ったら、次はUXやパフォーマンスを実現するSPAの基本と、SEOのためのハイブリッドレンダリングの基本を理解しよう
2019年8月26日 7:00
この記事は、前中後編の3回に分けてお届けしている。中編となる今回は、PWAを可能にしている2つの技術のうち、SPAを可能にするApp Shellアーキテクチャについて見ていこう。
→ まず前編から読んでおく
前編を読んで最新ウェブ技術の入り口に立ったら、次はUXやパフォーマンスを実現するSPAの基本と、SEOのためのハイブリッドレンダリングの基本を理解しよう。
ここでは、ユーザーにとって快適なSPAを実現しながら、検索エンジンがコンテンツをクロール・インデックスできるようにするための基本的な知識として、
- ディープURLインデックス
- サーバーサイドレンダリング
- ハイブリッドレンダリング
- アイソモーフィックアプリ
- プリレンダリング
- JSフレームワークによる完璧なハイブリッドレンダリング/静的サイトジェネレータ
といった具体的な手法を理解していこう。
2. SPAを可能にするApp Shellアーキテクチャ
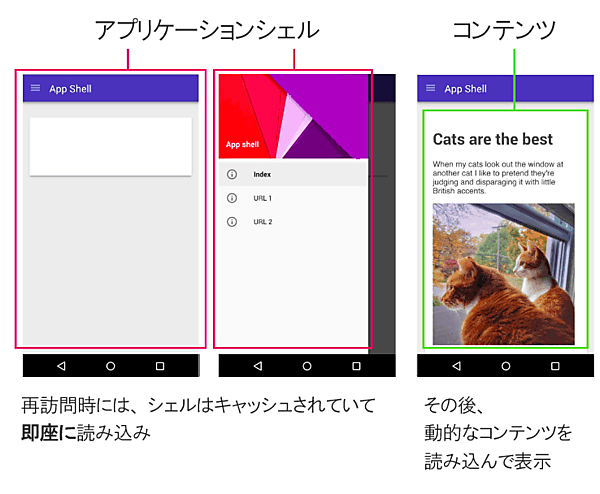
App Shell(アプリケーションシェル)アーキテクチャを一言で言うと、次のようなものだ。
静的なアセット(必要最低限のUIと機能)をキャッシュして高速に読み込めるようにしておき、実際のコンテンツはJavaScriptで動的に読み込む仕組み。
最近のJavaScript SPAフレームワークのほとんどがこうしたアプローチを推奨しており、ロジックとコンテンツを分離することで、スピードとユーザビリティの両方にメリットをもたらしている。
動作はネイティブアプリと同じくらい高速で、データの利用も非常に効率的だ。
URLが一意であるか、それがSEOのポイント
しかし冒頭で述べたように、クライアントサイドのJavaScriptへの依存度が高い状況は、SEOにとって問題だ。
歴史的に見ると、このような問題の多くは、次のようなギャップに起因する。
検索エンジンのクローラーは、コンテンツを検出してインデックス化するために一意のURLを必要とする
SPAは、アプリケーションやウェブサイトの状態が変わってもURLを変更する必要がない(だからこそ「シングルページ」と呼ばれる)
この問題とその解決には、歴史的な経緯がある。
昔のSPAは、ページをリロードせずにコンテンツを動的に操作するために「フラグメント識別子」という仕組みを使っていた。フラグメント識別子とは、URLの最後にハッシュ(「#」)に続けて表示されている部分なのだが、この情報はブラウザのみが扱うものであり、ウェブサーバーへのHTTPリクエストの一部として送信されないという特徴がある。これが、SEOにとって大きな悩みの種だったのだ。
もちろんグーグルもその問題に対応するための仕組みをもっていた。ハッシュをいわゆるハッシュバン(#!)と_escaped_fragment_パラメータに置き換えるというものだった。しかしグーグルは、かなり前にこの手法のサポートを打ち切っており、今後使うことはできない。
HTML5が可能にしたSPAのディープURLインデックス
だが今は、HTML5のHistory APIのpushStateメソッドのおかげで、もっと良い解決策が存在する。JavaScriptを使えば、ページをリロードせずにブラウザのURLバーの内容を変更できるため、ページをアプリケーションやサイトの状態と同期させ、ユーザーにブラウザの「戻る」ボタンを利用してもらえるのだ。
// これをコンソールで実行してブラウザのURLを変更 // ただしページが実際にリロードされることはない history.pushState(null, "Page 2", "/page2.html");
ただし、この方法は特効薬ではない。アプリを正しい初期状態でロードして、検索エンジンのクローラーがリクエストしてくる個別状態のURL(ディープURL)に適切な内容を返すようにサーバーを構成する必要がある。
それなりの工数はかかるが、history.pushState()は、SPAでURLの問題を解決するための手段をわれわれに提供してくれる。
それでも残る検索エンジン向け「レンダリング」問題
SPAと検索エンジンの関係におけるURLの問題はHTML5によってスマートに解決された。しかし今のSEO担当者は、より大きな問題に直面している。
その問題とは、コンテンツのレンダリング、つまりレンダリングを「いつ」「どのように」行うのかということだ(ただし、ここまでで説明したURLの問題よりは、はるかに理解しやすい)。
ウェブの世界で言う「レンダリング」とは、HTMLをもとにブラウザが実際に表示を行う処理を指す用語だ。しかし、ここからの解説で使う「レンダリング」という用語は、ブラウザやクローラーに送り出すHTMLを構築する処理のことを指しているので注意してほしい。
この点で、草創期のウェブは今よりシンプルだった。サーバーがページのレンダリングに必要なすべてのHTMLを返すのが普通だったからだ。
だが今では、SPAを利用する多くのサイトが、次のような仕組みを採用している。
サーバーからは最小限のHTMLしか送らない(前述の「アプリケーションシェル」相当の内容)。
クライアント(ブラウザまたはクローラー)がJavaScriptを動かしてコンテンツ部分のHTMLを取得し、シェルの中にうまく入れて表示する。
このクライアント側の処理は、それなりに「重い」ものだ(CPUやメモリを使う)。人間がブラウザで見ているときにはさほどだと感じないかもしれないが、検索エンジンがクロールしたページすべて同様の処理をするとなるとどうだろうか。がウェブの規模を考えると、これは多くの時間と計算リソースを必要とする。
グーグルは2018年の「Google I/O」カンファレンスで次のように述べ、このことが検索エンジンに大きな問題をもたらしていることを明らかにした。
JavaScriptで動いているウェブサイトをグーグル検索でレンダリングする場合、Googlebotがそのコンテンツを処理するためのリソースを利用できるようになるまで、そのレンダリングは延期される。
大規模なサイトでは、ページをクロールしてからこのJavaScriptを動かすインデックス処理が行われるまで数日かかることもある。そのうえ、canonicalタグやメタデータなどの重要な情報が完全に欠けてしまうなど、さまざまな問題に遭遇する可能性が高い。
このテーマについては、グーグルが素晴らしいディスカッションを動画で公開しているので、ぜひご覧いただきたい。最新の検索クローラーが直面しているいくつかの課題がわかりやすくまとめられている。
グーグルは、JavaScriptをレンダリングする非常に数少ない検索エンジンの1つだ。しかもごく最近まで、そのために使われているウェブレンダリングサービスは、(2015年にリリースされた)Chrome 41をベースにしていた(現在は最新版Chrome相当になっている)。
当然ながら、これはSPA以外にも影響を及ぼす話であり、幅広いテーマを含んだJavaScript SEOは、今ホットな分野となっている。レイチェル・コステロ氏が最近執筆したJavaScript SEOに関するホワイトペーパーは、私が読んだこのテーマに関する文献のなかで最も優れたものだ。バルトス・ゴラレウィッツ氏、アレクシス・サンダース氏、アディー・オスマニ氏など、ほかにもたくさんの専門家が執筆者として名を連ねている。
ホワイトペーパーの内容でこの記事にとって重要と思われる話は、次のようなものだ:
2019年時点では、JavaScriptで動作するウェブアプリを検索エンジンが正確にクロールしてレンダリングしてくれるものだと信頼しきるわけにはいかない。
これは何を意味するのか。関係するのは、あなたのサイトがJavaScriptを使ってクライアントサイドでコンテンツをレンダリングする構造であるときだ。
その場合、グーグルがあなたのサイトのコンテンツをインデックスするのに大量のコンピュータ資源を必要とする。となると、すべてのコンテンツが迅速に完全な状態でインデックスされるとは限らず、結果として検索におけるパフォーマンスが低下するかもしれないということだ。
これとは反対の話を聞いたことがあるかもしれない。しかし現実的には、あなたのウェブサイトにとってオーガニック検索が貴重なチャネルであるならば、クライアントサイドではなく、サーバーサイドでレンダリングできるようにしておくことが必要なのだ。
とはいえ、サーバーサイドレンダリングは、何かと誤解されることが多い……。
SPAのインデックス問題はサーバーサイドレンダリングで解決
「サーバーサイドレンダリング」とは、要は「検索エンジンのクローラー向けに、JavaScriptの重い処理をしなくてもコンテンツをインデックスできる状態のHTMLを生成する」ということだ。
ここでポイントとなるのは、SPA的な仕組みでサイトをつくっている場合、サーバーサイドレンダリングを行おうとすると、
- ブラウザ向けのSPA
- クローラー向けのサーバーサイドレンダリング
という2つの処理を構築する必要があるという点だ。しかも、その2つは「最終的にユーザーが目にするコンテンツをページのHTML(構造)として構築する」という、まったく同じ目的なのだ。
もう1つのポイントとして、「ブラウザ向けとクローラー向けを、どう切り分けてどう処理するか」という点もある。
「サーバーサイドレンダリング」は、SEO監査でよく推奨される手法だ。僕は、この手法が簡単に実行できる自己完結型のソリューションであるかのように紹介されているのをよく耳にする。だが、本当にそうなのだろうか。そうした説明は、よく言っても、膨大な技術的作業をあまりに単純化した話に過ぎず、最悪の場合は、問題のウェブサイトで可能なことや必要なこと、および得られるメリットを誤解していることもある。
実際のところ、サーバーサイドレンダリングを正しく実装するには、さまざまな選択肢から自サイトに合った手法を適切に選んで組み合わせていく必要がある。選択肢は数多くあり、その組み合わせも多岐にわたるのだ。
とはいえ、最終的に重要になるのはシンプルに「サーバーから静的なHTMLが返されるようにする」ということだ。
サーバーサイドレンダリングの2つのアプローチ:
「動的レンダリング」と「ハイブリッドレンダリング」
では、どんな選択肢があるだろうか。サーバーサイドでコンテンツをレンダリングするという概念をいくつかに分類し、われわれがとりうる選択肢を検討してみよう。
今から説明するのは、前述のI/Oカンファレンスでグーグルが紹介したアプローチの概要だ。
動的レンダリング
普通のブラウザにはクライアントサイドでのレンダリングを必要とする「通常の」ウェブアプリを提供し、一方、ボット(Googlebotやソーシャルメディアサービスなど)には静的なスナップショットを提供するという手法だ。
この処理では、サーバー側で追加の手順が必要になる。具体的には、リクエストごとにユーザーエージェント名に基づいて処理を分岐させ、それがクローラーならば、
- Webサーバーからアプリを取得する
- そのアプリを(サーバー側で)実行してコンテンツをレンダリングする
- 静的なHTMLをクローラーに返す
ということを実行する仕組みを構築するのだ。
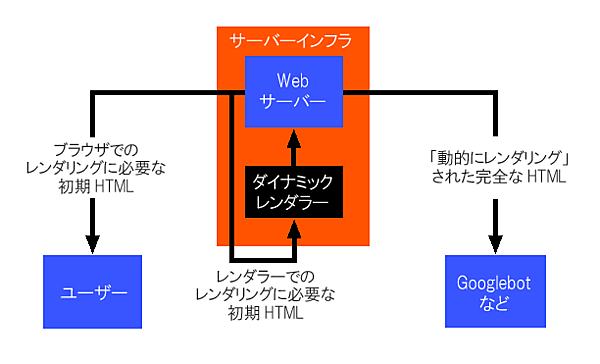 Google I/Oの資料をもとに編集部で作成
Google I/Oの資料をもとに編集部で作成この手法の大きな利点は、たいていの場合、既存のインフラに組み込めることだ。
従来、この処理はPhantomJS(すでにサポートが終了しており、開発の予定もない)のようなサービスで行われていたが、今ではPuppeteer(ヘッドレスChrome)で同様の機能を実現できる。
ハイブリッドレンダリング
これはグーグルがずっと前から推奨している手法で、新しいサイトを構築するならこれを使うのがベストだ。
簡単に言えば、次のようなものだ。
Webサーバーは、アクセスしてきたのが人間であろうがクローラーであろうが、完全にレンダリングされた静的なHTMLを最初から提供する。
クローラーは、URLをリクエストするたびに静的なコンテンツを取得できる。
普通のブラウザでは、初めてページが読み込まれたときは、サーバーから取得したHTMLをそのまま使う。
しかし、その後にユーザーがリンクをクリックするなどの操作をしたときには、初期HTMLに含まれていたJavaScriptが処理を引き継ぎ、SPA的に動作する。
これは理論的には優れた解決策であり、スピードとユーザビリティの点でも多くのメリットがある。後ほどさらに詳しく説明しよう。
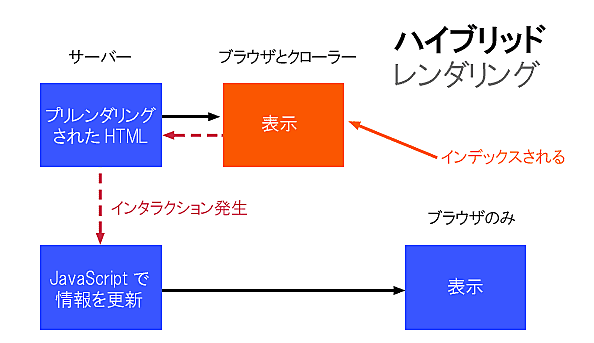 Google I/Oの資料をもとに編集部で作成
Google I/Oの資料をもとに編集部で作成
ハイブリッドレンダリングを実現するアプローチ:
「アイソモーフィックアプリ(ユニバーサルアプリ)」と「プリレンダリング(JAMstack)/静的サイトジェネレータ」
さて、前述したサーバーサイドレンダリングの手法としては、後者の「ハイブリッドレンダリング」のほうがより洗練された手法だ。サーバー側でユーザーエージェント名をもとに処理を分ける必要もない。そういったことから、グーグルはずっと前からハイブリッドレンダリングを推奨している。
ただし、「ハイブリッドレンダリング」が単一の処理ではないことは明記しておきたい。複数のアプローチを実行することで、あらかじめレンダリングされた静的なコンテンツをサーバーサイドで利用できるようにしているのだ。そのアプローチをいくつか紹介しよう。
アイソモーフィックアプリケーション(ユニバーサルアプリ)
これは「ハイブリッドレンダリング」を実現するための手段の1つだ。
「アイソモーフィックアプリケーション」とは、サーバー側とクライアント側のどちらででも同様に実行できる、JavaScriptで構築したアプリケーションのことだ。
昔は「サーバー側はPHPやRuby」「クライアント側はJavaScript」と、異なるプログラミング言語でコードを書く必要があった。
しかし、Node.js(ノードジェイエス)と呼ばれるプログラムによってその世界が変わった。Node.jsとは、JavaScriptで書いたプログラムをサーバー側で動かせるようにするものだ。
これによって開発者は、Webサーバーとブラウザの両方で実行できるコードをJavaScriptで書けるようになったのだ。
アイソモーフィックアプリケーションを実現するには、通常は、JavaScriptフレームワーク(React、Angular Vue.jsなど)をNodeサーバー上で動作するように構成し、クライアントに送信されるHTMLの一部または全部をあらかじめレンダリングする。そのため、該当するページのHTMLをレンダリングして、ディープURLに応答できるようにサーバーを構成する必要がある。
こうしてサーバーが返すHTMLを受け取ったのが普通のブラウザであれば、その時点でクライアントサイドアプリケーションが動作して、処理をシームレスに引き継ぐ。初期表示用にサーバーサイドでレンダリングされた静的なHTMLが、ブラウザによって「再復元」(いい表現だ)されてSPAに戻され、以降のナビゲーションイベントをJavaScriptで実行するようになるのだ。
うまく設定できれば、この手法は素晴らしい成果をもたらす。
- クライアントサイドレンダリングがユーザビリティにもたらすメリット
- サーバーサイドレンダリングがSEOにもたらすメリット
の両方を享受でき、高速な初期表示が可能になるからだ(ブラウザではJavaScript始動時の再復元処理のために、操作が可能になるまでの時間[Time to Interactive]が長くなることが多いという難点はあるが)。
話をあまり単純化したくないため、これ以上詳しい説明は控えたいが、ここで重要なポイントを伝えておく。それは、アイソモーフィックJavaScriptや完全なサーバーサイドレンダリングは強力な解決策として利用できるが、設定がきわめて複雑になることが多いということだ。
では、ほかにどんな選択肢があるだろうか。アイソモーフィックアプリを設定するための時間や費用の確保が難しい人や、達成したい目的に比べて手間がかかりすぎるという人にとって、SEOの効果を損なうことなく、SPAモデル(そしてハイブリッドレンダリング)のメリットを享受できる方法は、ほかにあるだろうか。
プリレンダリング(JAMstack)/静的サイトジェネレータ
レンダリングされたコンテンツをサーバーサイドで利用できるようにするのに、レンダリングの処理を常にサーバー側で行う必要はない。必要なのは、レンダリングされたHTMLをサーバーに置いておき、クライアントに提供できるようにすることだ。したがって、レンダリングの処理はどこで実行しもよい(サーバーでも手元のパソコンでも)。
JAMstackを使ったアプローチでは、コンテンツをHTMLにレンダリングする処理を、ビルドプロセスの一部として行う。
僕は以前、JAMstackによるアプローチに関する記事を書いたことがある。その記事の冒頭でも紹介したが、「JAMstack」とは、次に示す3つの単語から頭文字をとった言葉だ(「Stack」は「組み合わせて使う」といった意味合い):
- JavaScript
- API
- Markup
この事実は、JAMstackがサーバーサイドソフトウェアを使わずに複雑なウェブサイトを構築する手段であることを示している。フロントエンドのコンポーネントからサイトを構築するプロセス(従来のサイトでは、WordPressやPHPで実行されるプロセス)がビルドプロセスの一部として実行される一方、インタラクティブな動作はJavaScriptやAPIによってクライアントサイドで処理される。

次のように考えてほしい(あらゆるものがGitリポジトリにあるとする):
コンテンツは(ヘッドレスCMSや他のAPIベースのソリューションで編集できる)プレーンテキストのマークダウンファイルとして保存しておく。
ページテンプレートとページ生成ロジックは、Go、JavaScript、Rubyなど、あなたが選んだサイトジェネレータが利用している言語でつくっておく。
適切なコマンドラインツールを使って、サイトを静的なHTMLに変換する(この処理はサーバー上で実行しようがどこで実行しようがかまわない)。
生成した静的なHTMLはどこでもホスティングできる。
その結果、簡単にキャッシュできる静的なファイルとしてつくられたWebページを、ほとんど何もすることなく、コンテンツデリバリーネットワーク(CDN)上で安全にホストできるようになる。
ここで生成したファイルには各ページのコンテンツが含まれている。昔ながらの手書きHTMLと違うのは、コンテンツ管理やページ構築の仕組みはCMSなどで管理しながらも、最終的に静的なファイルとして生成している点だ。
正直なところ、僕は静的なサイトジェネレータ(もっと厳密に言えば、そのジェネレータを支える原理や技術)が将来の姿だと思っている。僕が間違っている可能性もあるが、このアプローチの機能と柔軟性が高いことは、GulpやWebpackなど最新のnpmベースの自動化ソフトウェアを使用してCSSやJavaScriptを記述している人にとって明らかなはずだ。
専門家向けウェブホストNetlify(ネットリファイ)が提供しているディープなGit統合を実際のプロジェクトでテストして、それでもJAMstackのアプローチが一時的な流行だと考える人がいたとしたら、僕はその人に反論するだろう。
JavaScriptフレームワークを活用したプリレンダリング済みハイブリッドレンダリング
SPAとプリレンダリングに関するわれわれの議論にとって、JAMstackが重要であることは疑いの余地がない。だが、静的サイトジェネレータがテンプレートに基づいてHTMLを生成できるのであれば、同じことをJavaScriptででも実行できないだろうか。
まさにそれをやってくれる新しいタイプの静的サイトジェネレータがある。これが可能なプログラムにはReactベースやVue.jsベースのものが多く、開発者は最新のJavaScriptフレームワークを使ってウェブサイトを構築できる。
ページ(または「ルート」)ごとにSEOフレンドリーな静的HTMLを出力するように設定するのも簡単だ。各HTMLファイルは、人間とボットがすぐに利用できる形で完全にレンダリングされたコンテンツになっている。
そして、生成する静的ファイル自体に、完全なクライアントサイドアプリケーション(つまりSPA)を含むことも、もちろん可能だ。
これはグーグルの言う「ハイブリッドレンダリング」を完璧に実行したものだが、プリレンダリング処理を正確に行っている点が、アイソモーフィックアプリとは大きく異なっている。
この優れた例の1つがGatsbyJS(ギャツビー・ジェイエス)だ。このシステムは、ReactおよびGraphQL(グラフキューエル)で開発されている。
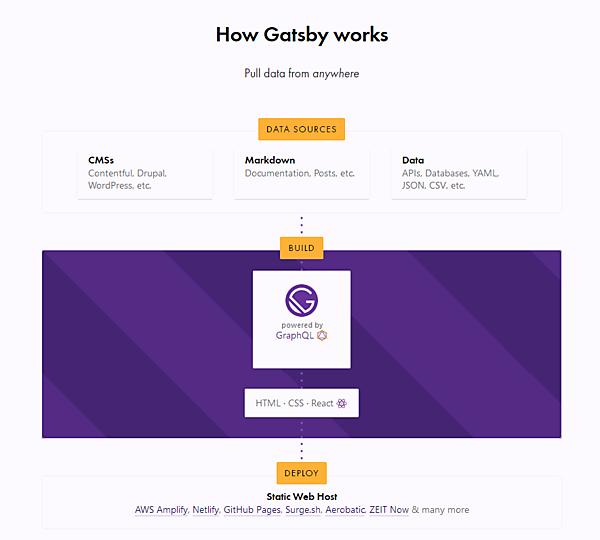
詳しい説明はしないが、ここまでこの記事を読んだ方には、GatsbyJSのトップページと素晴らしい資料をチェックすることをお勧めする。GatsbyJSは手厚くサポートされたツールで、無理なく習得でき、コミュニティも活発だ(豊富な機能を備えたv2.0は9月にリリースされた)。
また、拡張可能なプラグインベースのアーキテクチャや、多くのCMSに対応した幅広い統合機能を備えている。開発者は、SEO効果を損なうことなく、Reactのような最新のフレームワークを利用することが可能だ。また、Vue.jsとReact Static(ご想像のとおり、これはReactを使用している)をベースとしたGridsome(グリッドサム)もある。
今後は、このようなプラットフォームを採用する大企業が増えるだろう。GatsbyJSを使っている大手サイトとしては、次のようなものがある。
- ナイキのJust Do It.キャンペーン(Reactベースの静的サイトジェネレータであるGatsbyJSを利用したもので、Netlifyでホスティングされている)
- Airbnbのエンジニアリングサイト「airbnb.io」
- ブラウンの主要なEコマースサイト
さらに、われわれの友人であるSEOmonitorも、新しいウェブサイトの運用に利用している。
SPAとJavaScriptレンダリングについては、今のところこれくらいで十分だろう。次は、PWAを支える2つの主要な技術の2番目を取り上げる番だ。どうか最後までとことん付き合ってほしい。これから話をするのはService Workerだ。
3回に分けてお届けしてきたこの記事も、次回が最終回となる。後編では、PWAを支える2つの技術のうち、残るService Workerについて解説する。→後編を読む
- この記事のキーワード
関連記事
SEO監査に有効な「Googlebotブラウザ」の必要性(前編)
2025年4月7日 7:00
謎だらけのSEOテクニカル問題を解決する8つのポイントとは? 【中編】グーグルは正しくクローリングできている?
2018年10月29日 7:00
SEO担当者が知っておきたいJavaScriptの基本 ―― グーグルにサイトを正しく理解させるために(後編)
2017年9月25日 7:00
「SEOにテクニカルな要素は必要ない」の嘘――なぜ今、SEOに技術的な理解が必要なのか(全6回の1)
2017年1月16日 7:00
Googleがキャッシュ保存をできるようにしてください。お願いします【SEO情報まとめ】
2025年1月24日 7:00
誰も語ろうとしないAIのダークサイドと、LLMクローラーのログ活用法(前編)
6月22日 7:05
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




