テクニカルSEOの立場から考える「コンテンツとリンク」(テクニカルSEOの復権全6回の4)
「エンティティ」「TF-IDF」「徴証語」「関連語」といったトピックを理解しているだろうか。
2017年2月6日 7:00
「SEOにテクニカルな要素はもうない」というのは本当だろうか? 今の時代に改めて重要性が増しているテクニカルSEOを解説するこの記事、全6回の4回目は、テクニカルSEOの立場から「コンテンツとリンク」について考えてみよう。
まず前回までを読んでおく
→第1回「ウェブ技術の進化」「JavaScript」「HTTP/2」
→第2回「SEOツール」「検索順位」「クローキング」
→第3回「クロール」「スクレイピング」
テクニカルSEOの立場から考える「コンテンツとリンク」
SEOの仕事のかなりの部分が、この数年間で変わってきた。具体的には、「リンクを増やすためにより多くのコンテンツを作成すること」がかなり多くなってきた。
コンテンツを拡充してリンクを増やす方法を巡る議論に、今の時点で何かを加えることに価値があるのかどうか、筆者にはわからない。
しかし、多くの人にとって最重要項目ではなくなっている「既存のリンク」と「既存のコンテンツ」にも何らかのチャンスがあるのではないかと思っている。
グーグルはまずエンティティを見る
グーグルは、クエリを検討する際にはまずエンティティを見ると発表している。
「エンティティ」とは、グーグルのシステム内における固有名詞の表し方を指す用語だ。たとえば「著名人」「著名な場所」「有名な物」「有名な出来事」を識別し、自然言語の理解に影響を与える。
たとえば「ドナルド・トランプ」は単なる文字列であり1つのキーワードだ。
しかし、これを「米国の第45代大統領で、不動産会社トランプ・オーガニゼーションの会長兼社長、1946年6月14日に米国ニューヨーク州で生まれた。妻はメラニア氏で、子にはドナルド・トランプ・ジュニア、イヴァンカ、エリック、ティファニー、バロンがいる」といった意味も含めて扱うのが「エンティティ」だ。
これによりグーグルは、「米国の第45大統領の生年月日は」という検索に対して「1946年6月14日」という答えを出せる。
筆者はセミナーなどでこの件について話す際には、聴衆に「エンティティ戦略を持っているかどうか」を聞いて挙手してもらうようにしている。この話は10回以上やっているが、これまでに手を挙げたのはたったの2人だ。
このテーマに関する最も重要なオピニオンリーダーはビル・スロースキ氏なので、ここは筆者も同氏の見識に任せ、同氏の記事を読むことをおすすめしたい。
また、AlchemyAPIやMonkeyLearnのような自然言語処理ツールの利用をおすすめしたい。さらにおすすめなのは、グーグル自身の自然言語処理APIを使ってエンティティを抽出することだ。
では、「標準的なキーワード調査」と「エンティティ戦略」の違いは何だろうか。
それは、エンティティ戦略を構築するには、すでにある自分のコンテンツをもとにする必要がある点だ。
エンティティを特定する際は、まずキーワード調査を行い、そのランディングページをエンティティ抽出ツールに流し込んで、どのようになるかを知るべきだ。
また、競合相手のランディングページを同様にエンティティ抽出のAPIにかけて、どのエンティティがキーワードに狙われているのかを突き止めよう。
TF*IDF
単語の出現頻度(Term Frequency)と逆文書頻度(Inverse Document Frequency)から算出されるTF*IDFは、米国ではあまり議論されていない自然言語処理のテクニックだ。事実、これまでSEOコミュニティの熱い議論で話題になってきたのは、トピックモデリングのアルゴリズムだ。
心配なのは、トピックモデリングのツールは、ユーザーに有用なコンテンツを制作するという考え方を考慮せず、キーワード密度の暗黒時代にわれわれを押し戻す傾向がある点だ。
これに対し、欧州の多くの国では、リンクがなくてもオーガニックなビジビリティを高める重要なテクニックとして、TF*IDF(あるいは、ドキュメント内頻度[Within Document Frequency]と逆文書頻度に基づくWDF*IDF)が信頼されている。
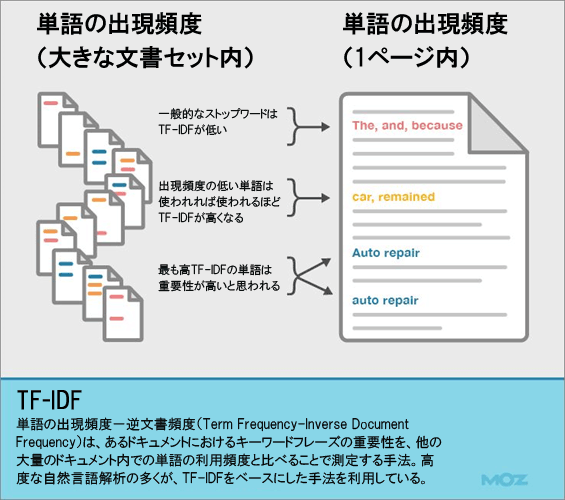
昨年、少しドイツで過ごしたところ、何人かの人と話をしてTF*IDFにはもう一度目を向ける価値があると納得させられた。そこで、うちはTF*IDFを見直し、コンテンツ最適化のプロセスに組み込むようにした。
Searchmetricsのランキング要因に関する2014年の調査では、TF*IDFは実際はビジビリティと負の相関関係にあり、一方、関連語(Relevant Term)および徴証語(Proof Term)は強い正の相関関係にあることが判明した。
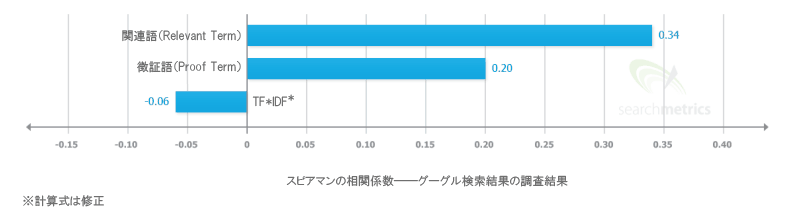
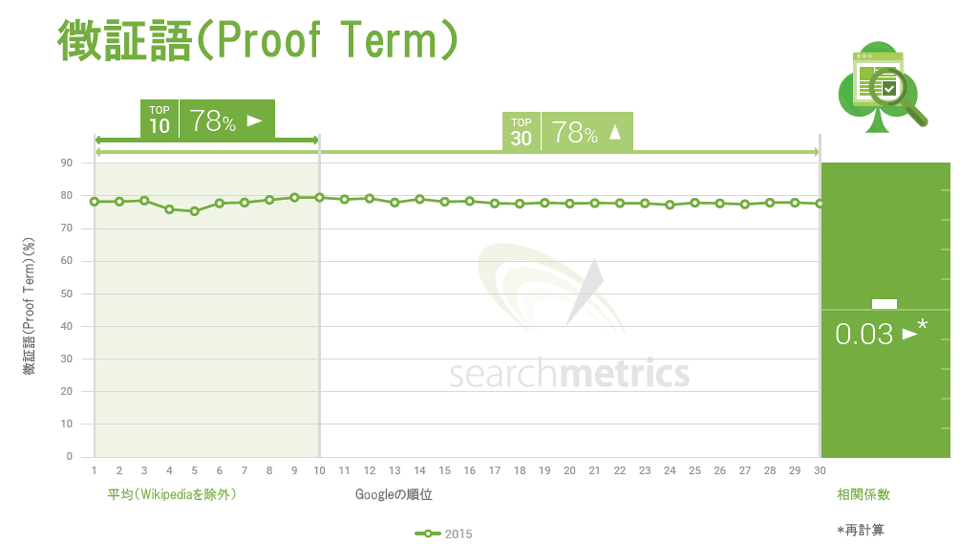
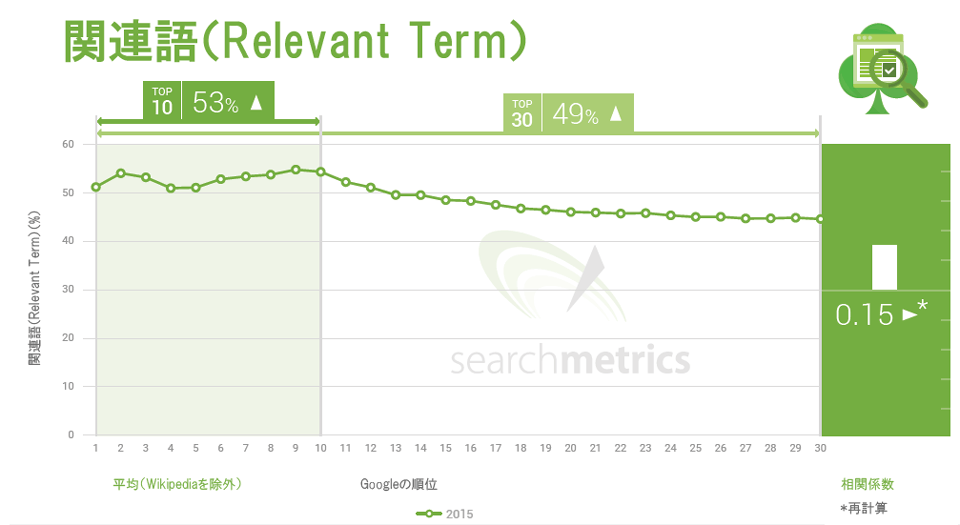
Searchmetricsはこれらの要因を調査した結果に基づき、2015年は徴証語と関連語を優先し、分析からTF*IDFを完全に外す決断をした。この正の相関関係は、前年より若干弱まって入るものの、ほぼ変化がない。
Mozが調査した2015年の検索順位決定要因では、オンページコンテンテンツ要因のうち、LDAとTF*IDFに関連する項目が引き続き上位に挙げられている。

実際は、どのモデルに目を向けるにせよ、メインターゲットとするキーワードで高い順位を獲得するため、文章中に関連するキーワードを使うという考え方は共通している。それでうまくいくからだ。
われわれがTF*IDFを用いた戦術だけを取り出して調査したとは言えない。しかし、TF*IDFを使って最適化したページは、そうしなかったページよりも順位が大きく上がったと言うことはできる。うちではOnPage.orgのTF*IDFツールを活用しているが、厳密な計算ルールを採用して従っているわけではない。関連するキーワードがアイデアの創出に影響を及ぼせるにしたうえで、それを合理的な範囲で活用している。
少なくとも、コンテンツのこのような技術的な最適化は再検討する必要がある。それと同時に、コンテンツマーケティングの取り組みをもっと有効活用するためにサイラス・シェパード氏が提唱しているその他の戦術も検討するべきだろう。
この記事は、6回に分けてお届けしている。5回目となる次回は、「リダイレクト」と「構造化データ」について考察する。 →第5回を読む
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




