「SEOにテクニカルな要素は必要ない」の嘘――なぜ今、SEOに技術的な理解が必要なのか(全6回の1)
SEOにテクニカルな要素は必要ないのか? いや、ウェブの技術が進化するにつれ、テクニカルSEOは今までにないほど複雑になり、その重要性が増している
2017年1月16日 7:00
ウェブの技術は猛烈な勢いで発展し、急速に普及しつつある。また、コンテンツはあらゆるタイプの企業やエージェンシーが参入する分野となり、誰もがその分け前を求めて競い合っている。
そのようななか、テクニカルSEOは今までにないほど複雑になり、その重要性が増している。しかし、SEOに関する議論では、進化を続けるテクニカルな要素の話は避けられ、コンテンツマーケティングがテーマになることがほとんどだ。しかし、じきにSEOの分野でテクニカルな要素がふたたび第一線に立つときが来るだろう。そのときに備えて準備をしておくことが必要だ。
とは言うものの、「現在のSEOはテクニカルではない」と述べているソートリーダーも多い。こうした発言は、新しいテクノロジの背後で次々と生まれている機会や問題を誤って伝えるものだ。また、マーケティング分野としてのSEOで、テクニカルな知識の格差がこれまでになく広がっている状況に手を貸している。彼らは、多くのSEO担当者が新しい問題を解決するのを困難にしているのだ。
ここ数年で知識の格差が広がったことから、筆者は初めて、プレゼンテーションの「ツアー」をしてみようという気になった。筆者が1月からテクニカルSEOの復権についての話をさまざまな形で行っているのは、現実について話を始めることが重要だと考えたからだ。
具体的に言えば、状況は変化しており、この変化に対応しなければ、多くの組織やウェブサイトが手遅れになる可能性があるという現実だ。このプレゼンテーションを始めて以来、筆者の考えが正しいことを証明する出来事がたくさん起こっている。そこで、本記事でもこのテーマを取り上げて議論を続ける価値があると筆者は考えている。では、さっそく始めよう。
SEOの簡単な歴史(筆者の観点から)
この数年間でテクニカルSEOが見向きもされなくなっていることは、実に興味深い。かつてのテクニカルSEOは、なくてはならない存在だった。

個人的な話だが、筆者がウェブの仕事を始めたのは、マイクロソフトでインターンの高校生として働いていた1995年のことだった。そのときの肩書きは、当時ウェブの仕事をしていた他の人たちと同じく、「ウェブマスター」だった。ウェブの仕事が数え切れないほど多くの分野に分かれるずっと前のことだ。
この頃は、フロントエンドとバックエンドの違いなどなかった。DevOps(開発と運用を組み合わせた開発手法)やユーザーエクスペリエンスといった言葉もない。誰もが単なるウェブマスターだったのだ。
当時は、ヤフー、アルタビスタ、ライコス、エキサイト、ウェブクローラーといった検索エンジンが全盛期を迎える前だ。ウェブサイトを探すには、リンクロールをクリックしたり、Gopher、Usenet、IRCを使ったり、雑誌やメールを見たりしていた。また、この時期はInternet Explorer(IE)とNetscapeがブラウザ戦争を繰り広げており、複数のクライアントサイドスクリプトを選択しなければならなかった。フレーム(iframeではなく)が大流行したのもこの頃だ。
次に、検索エンジンが登場した。正直なところ、当時の筆者は、検索エンジンがどのような仕組みで動いているのかよく知らなかった。筆者が知っていたのは、ライコスが自分の質問に対して最も信頼できると思われる検索結果を返してくれることだけだった。当時の筆者は、このようなポータルサイトの裏で人々が命令を実行しているなどとは考えもしなかった。
そして、SEOの時代に入る。

SEOを誕生させたのは、次のような人たちだ。
- ウェブマスター
- 情報検索という当時は知る人も少なかった分野を専門とするコンピュータサイエンティストたち
- 「ネットを利用してすばやくお金持ちになろう」と考えていた人たち
こうしたインターネットの黒幕たちは、外からはほとんど見えないウェブ業界の片隅で、さまざまなテクニックやトリックについて情報を交換し合う手品師のような存在だった。彼らは基本的にオタクであり、キーワードスタッフィング、コンテンツスピニング、クローキングといった手法を用いて、検索エンジンから利益を得ていた。
そして、グーグルがこの集まりに加わった。

初期のグーグルは、度々アップデートを行い、まとまった休息の時間をなかなか与えてくれない存在だった。検索エンジン15年の歴史を短くまとめると、こんな感じだ。
グーグルはフロリダ、パンダ、ペンギンといったアップデートを実施。コンテンツ汚染とリンク操作に対応して、ゲームのルールを変えていった。特にパンダとペンギン以降のアップデートから、SEO業界の様子は大きく変わることになる。
「どんなものでも検索順位を上げてみせます」といった傲慢なSEO事業者の多くが、ホワイトハットSEOに姿を変えるか、ソフトウェア企業を起ち上げるか、あるいは撤退して別のことを始めた。
これはハッキングやスパムリンクがもはや有効ではなくなったという意味ではない。こうした手法は今も多くの場で使われている。より正確には、グーグルが洗練されたことによって、多くの人々がジェットコースターのような目まぐるしい変化に耐えられなくなり、ついに意欲をなくしてしまったのだ。
同時に、異なる分野の人たちがSEOに参入し始めた。バックグラウンドが非常に異なる人たちがSEO業界にやって来るのは普通のことだったが、次第に「マーケティング」界隈の人々が多く引き寄せられるようになった。SEO業界がコンテンツマーケティングに重心を大きく移している現状を見れば、これは非常に納得できる話だ。その結果、われわれは次のような記事を見かけるようになっている。

この状況は当然のように、マーケターに対してマーケティングを行うマーケターをたくさん生み出した。そして彼らは、こんな風に言うのだ。
最新のSEO施策では、テクニカルな知識はほとんど必要ない
また、筆者がさらに憤りを覚える見出しの中には、「SEOはメイクアップだ」というものもある。

当然ながら、筆者はこうしたメッセージに同意しないが、ソートリーダーたちがこうした考え方を示す理由は理解できる。筆者は過去にどちらの側の人たちともある程度仕事をした経験があり、彼らがコンテンツに目を向けがちであることを知っている。
だが、いずれにせよ、彼らが主張する重要なポイントは、最新CMSの多くが、昔からあるSEOのベストプラクティスの多くを含んでいるとする点にある。グーグルは、コンテンツの内容を理解することが非常に得意だ。最終的には、企業は自社のユーザーにとって意味のあるコンテンツを作成し、競争力のあるマーケティングを可能にすることに注力する必要がある。
筆者がSEO分野におけるパラダイムシフトについて明らかにしようとした以前の記事を覚えている読者なら、筆者がそうした考えに基本的に同意していることがわかるだろう。だが、テクニカルな要素が変化しているという事実を無視するつもりはない。テクニカルSEOなしにSEOは始まらない。あるいは、アダム・オデット氏が言うように、「SEOは目に見えないものであるべき」なのだ。メイクアップなどではない。
ウェブテクノロジの変化がテクニカルSEOを復権させる
SEOでは、開発者はいつも最新のものを取り入れたがるとして批判されることが多い。取り組みを進めるにあたっては、その最新のものを理解し、より効果的に取り入れられるようにすることが重要だ。
SEO担当者はいつも、JavaScriptに対してかなりの恐怖感を持っているが、これには正当な理由がある。少なくともこの10年間、検索エンジンのテクノロジは、われわれがブラウザで見ているのと同じようなやり方でウェブをクロールしている。だが、コンテンツが実際にクロールされているか、そして何よりもインデックス化されているかどうかは、予測できないのが常なのだ。
われわれが当初、ヘッドレスブラウジングというアイデアを2011年に考えてみたとき、コンピュータ処理に費用がかかりすぎて、大きな規模で実現するのは無理だというのが大方の反応だった。だが、それが今も本当であったとしても、グーグルは、相当な数のウェブがJavaScriptで表示されているのだからやってみる価値はあると考えているようだ。
時が経つにつれて、このアイデアを試す人は増えていくだろう。最終的には、グーグルの元従業員がハッカーニュースに投稿した以下のコメントからわかるように、グーグルは長い間、この問題を克服する必要があると考えていたのだ。
これは私が2006年から2010年まで、グーグルで取り組んでいたメインの仕事だ。
私の初めてのテストケースの1つは、ある期間におけるウォール・ストリート・ジャーナル(WSJ)の中国語ページのアーカイブだ。これらのページのテキストは、すべてJavaScriptの文字列リテラルだった。
私が変更を実施するまで、グーグルはこのようなページをすべて同一のコンテンツ、つまり、ナビゲーション用の決まったフレーズだとみなしていた。だが、WSJの英語ページではこうした処理が行われていなかった。そのため私は、WSJがコンテンツを検索エンジンから見えないようにしているわけではなく、一部の古いブラウザのバグによって中国語ページが正しく表示されない(あるいはおかしな表示になる)問題を迂回しようとしていたのではと推測した。JavaScriptでテキストをレンダリングすれば、どういうわけかこのバグを回避できたのだ。
ここで実に興味深い取り組みは、次の3つだった。
レンダリングの結果がいつも同じになるようにすること(同じページが常にグーグルから同じように見えるようになり、重複を排除できる)
実際のブラウザの動作から大きく逸脱するのはどういう場合かを知ること(クローラーのために無意味なURLを大量に生成したり、偽のリダイレクトを大量に生成したりすることがなくなった)
エミュレートしたブラウザがIEとFirefox(そして後にはChrome)と同じように表示され、「IEを使用してアクセスしなおしてください」とか「Firefoxをダウンロードしてください」といったページが何度も表示されないようにすること
最終的には、SpiderMonkeyのバイトコードのディスパッチに変更を加え、シミュレートしたブラウザがわけのわからない状態になって意味不明な表示をするタイミングを検知できるようにした。
私は多くのトラブルを経験した末、IE、Firefox、そしてChromeでさまざまなJavaScriptイベントが発生する順序を把握した。その結果、一部のページでは、一から読み込みなおした場合と更新ボタンを押した場合とで、イベントの発生順序が異なることがわかったのだ(私はこのときに、Shiftキーを押しながらブラウザの更新ボタンを押せば、ページを一から読み込みなおしたときと同じようになることを知った)。
あるとき、random()関数が常に0.5を返すことに気付いたSEO担当者がいた。また、JavaScriptが常に日付を2006年夏のある時として参照しているとわかった人がいかもしれない。しかし、その状況は変わったのではないかと私は推測している。
今ではみんな、乱数にはシードと鍵付き暗号ハッシュを使用した日付を指定しているものと期待している。そうであれば、結果は常に決定論的で、ごまかしづらくなる。(……中略……)(これにより、大量のインデックスが一度にすべての日付を切り替えることがなくなるとともに、各ページに異なる日付を設定できる)。
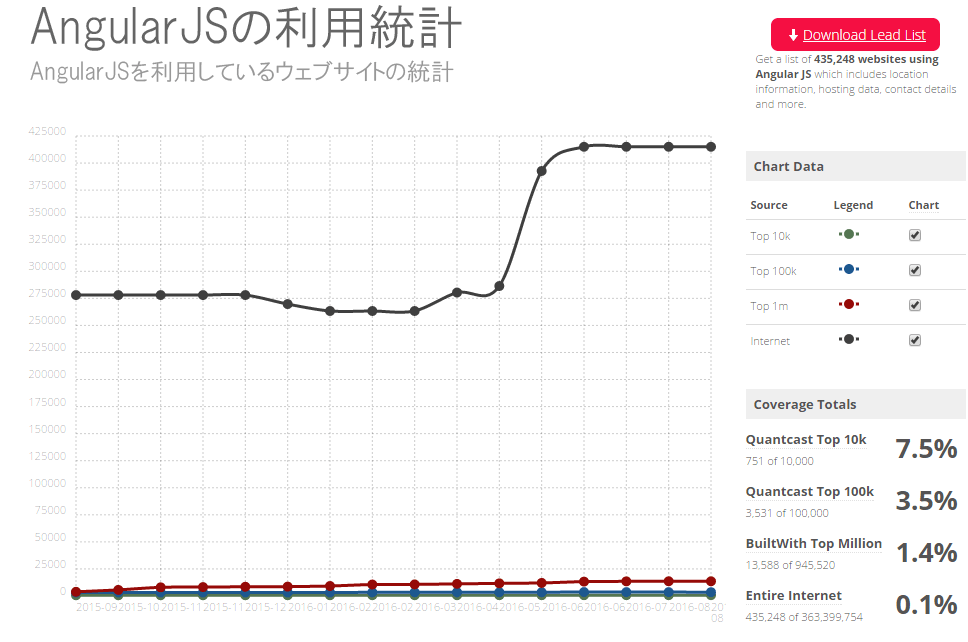
ここで、BuiltWithが公開しているJavaScriptの利用統計データを見てみよう。

JavaScriptが普及していることは明らかだ。ほとんどのウェブサイトが、JavaScriptを使用して、さまざまな形でコンテンツをレンダリングしている。そのため、JavaScriptでレンダリングされたページにどのようなコンテンツがあるのかをグーグルが把握できていなければ、時間が過ぎるにつれて検索の品質が急激に下がる可能性がある。
また、最近になって、グーグルのJavaScript MVWフレームワークであるAngularJSの採用が非常に増えている。筆者が数か月前にグーグルのI/Oカンファレンスに参加したとき、スピードと柔軟性がウェブにもたらしてくれることから、プログレッシブウェブアプリとFirebaseの最近の進化に関する話を何度も聞かされた。したがって、開発者による採用は増えるにちがいないと予想される。
残念なことに、BuiltVisibleがこの分野で素晴らしい貢献をしているにもかかわらず、
- プログレッシブウェブアプリ
- シングルページアプリケーション
- JavaScriptのフレームワーク
といった技術についてSEOの業界では十分な議論がなされていない。行われている議論は、301と302のリダイレクトの違いといったことがテーマだ。
だが、ウェブアプリ、シングルページアプリケーション、そしてJavaScriptのフレームワークは、最近になって採用が急増し、複数の業界で普及が進んでいることから、おそらく状況は変わるだろう。われわれiPullRankは、Angularへの切り替えを実施した多くの企業と仕事をした経験があるため、このことについて議論する価値は大いにある。
さらに、Facebookが貢献しているJavaScript MVWフレームワークのReactも、採用が同じようなペースで進み、開発プロセスに柔軟性をもたらしている。

ただし、SEOに関しては、AngularとReactに大きな違いがある。それは、Reactには最初からrenderToString関数があり、コンテンツをサーバーサイドで適切にレンダリングできることだ。そのため、Reactのページでは、インデックス化に関して大した問題は起こらない。
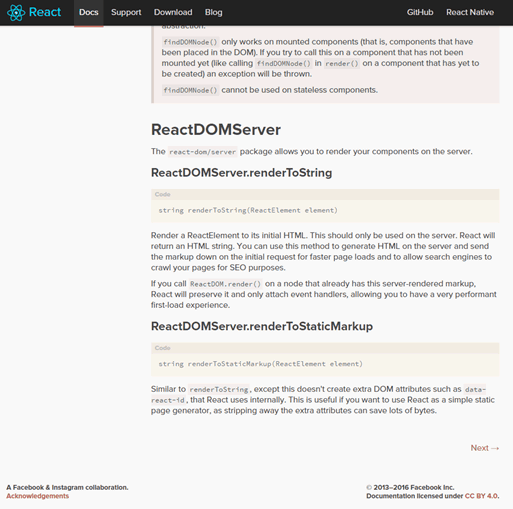
これに対し、AngularJS 1.xからは、Prerender.ioやBromboneのような、ヘッドレスブラウザベースのスナップショットアプライアンスを使って、あらかじめページをレンダリングするというSEOのベストプラクティスが生まれた。Angularはグーグル自身が開発しているスクリプトであることを考えると、これはやや皮肉な話だ(後で詳しく取り上げよう)。
ソースの表示はもはや無意味
前述のようなJavaScriptフレームワークが採用されるようになった結果、ソースを表示してウェブサイトのコードを調べるという方法は時代遅れとなった。
昔ながらのHTMLで書かれたページならば、ソースを表示すればコンテンツを把握できた。
しかし、こうした技術が使われているページでソースを表示して確認できるものは、ブラウザによって処理される前のコードであって、レンダリングに一対一対応するDocument Object Model(DOM)ではない。
もしあなたが、ここで述べているようにページのコードをこれまでとは異なったやり方で確認する必要があるという理由がわからないのならば、ウェブの動作に関するテクニカルな要素についてもっと理解を深めるべきだということを意味している。
ページのコードによっては、実際のコンテンツの場所に変数が表示されることもあれば、ページが完全に読み込まれたときに表示される完全なDOMツリーが表示されないこともある。
SEOではできるだけすぐにすべてのコンテンツをJavaScriptなしで表示できるようにすることが推奨されているのは、これが大きな理由だ。
この点を詳しく説明するために、下に示したSeamless.comのソースを見てもらいたい。このページのmeta descriptionタグまたはrel="canonical"タグを見ると、実際のテキストが入る場所に変数があることがわかる。

Chromeのデベロッパーツールか他のブラウザの「要素を検証」でElementsセクションのコードを見れば、完全に変換されたDOMが見つかる。変数が実際のテキストで置き換えられていることがわかるだろう。meta descriptionタグでもrel="canonical"タグでも、変数ではなく説明文やURLがタグに入っている。

検索エンジンはこのような形でクロールを行うため、ソースを表示してサイトのコードを調べることしかしていなければ、実際にはどのような内容が表示されるのかを完全に把握できない可能性がある。
HTTP/2の時代はすぐそこに
グーグルが大きな力を入れていることの1つがページの速度だ。ネットワークがページの速度に与える影響について理解することが、効果的なSEO施策にとって欠かせないのは間違いない。
HTTP/2が公開されるまで、HyperText Transfer Protocol(HTTP)の仕様は長い間更新されないままだった。実際、HTTP/1.1は1999年から使われ続けている。HTTP/2はHTTP/1.1と大きく異なっているため、この資料をよく読んでおくことをお勧めする。HTTP/2は、ウェブの速度を大きく向上させるはずだ。
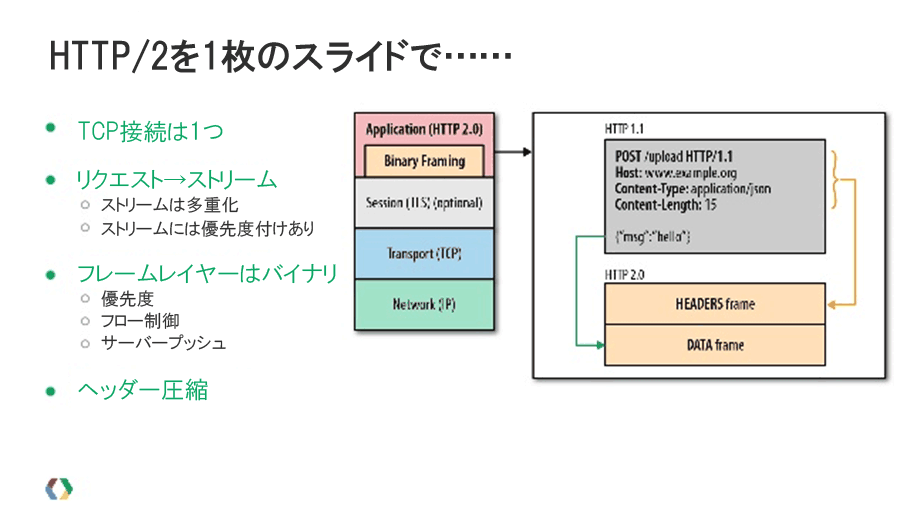
簡単に言うと、最も大きな違いの1つは、HTTP/2では1つのソースに対して1つのTCP接続を使用し、ストリームを「多重化」することだ。
グーグルのPageSpeed Insightsで取り上げられている問題を見たことがあれば、いつも話題になっていた最も重要なテーマが「HTTP同時接続数の制限」であるのがわかるだろう。この問題の解決に役立つのが多重化だ。HTTP/2は、1台のサーバーに対して1つの接続を開始し、その接続のなかで複数のリソースを同時に送受信する。必要なリソースはたいてい最初のリソースに基づいて判断される。
グーグルが近い将来、Transport Layer Security(TLS)でHTTP/2を利用することを義務付けているブラウザを利用して、ウェブサイトでHTTP/2が採用されるようにする取り組みに力を入れる可能性は非常に高い。結局のところ、この5年間で一貫して追求されているのは、速度とセキュリティなのだ。

最近では、HTTP/2を利用できることを売りにしているホスティングプロバイダが増えてきた。2016年にHTTP/2の利用が大きく増えているのは、おそらくこのことが理由だ。HTTP/2のいいところは、ほとんどのブラウザがすでにサポートしており、HTTPSさえ使っていれば、HTTP/2を利用するために必要な手間がそれほど多くない点だ。

HTTP/2はグーグルが最も力を入れて取り組んでいると思われるテーマだ。したがって、日頃からHTTP/2に注目しておくことが欠かせない。
テクニカルSEOについて述べられたこの長文記事は、6回に分けてお届けする。2回目となる次回は、「SEOツール」「検索順位」「クローキング」を巡る問題について見ていく。 →第2回を読む
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




