クローキングとは? - ブラックハットSEO大全#03
検索エンジンのロボットをだます悪質で発見しづらいこの手法
2010年10月14日 8:00
ブラックハットSEO(悪質なSEO)を知り、避けるためのこのコーナー。記事を読んで理解した内容は、SEO会社への発注時に具体的に聞いたり、自社サイトの対策状況をチェックしたりといった使い方をしてほしい。

「クローキング」とは
ユーザーに提供しているコンテンツとは別のコンテンツを検索エンジンに認識させる手法。「クローク(cloak)」は「包み隠す」「覆い隠す」ことを意味する単語。
どんな手法か詳しく解説
ユーザー向けの通常のHTMLページとは別に、検索エンジンに認識させるためのHTMLページを用意しておき、Webサーバーでアクセス元を判別して、ユーザーからのアクセスならばユーザー向けHTMLを、検索エンジンのクローラーからのアクセスならば検索エンジン向けのHTMLを読み込ませるようにします。
Webサーバーでアクセス元を判別するには2つの方法があり、そのどちらか、または両方を使って判別します。
- IPアドレス
Webサーバーには、アクセス元のIPアドレス(インターネット上のアドレス情報)がわかります。たとえば、アクセスしてきたのがグーグルのクローラーであれば、そのIPアドレスをDNSで逆引きすると「crawl-66-249-66-1.googlebot.com.」という名前であることがわかるため、それがグーグルのクローラーだと判別することができます(Googlebot の確認)。
- ユーザーエージェント名
Webサーバーには、アクセスしてきたプログラムの
識別子 (ユーザーエージェント名とも言います)がわかります。たとえば、Firefoxを使ってアクセスしたユーザーならば次のようなユーザーエージェント名になります。Mozilla/5.0 (Windows; U; Windows NT 5.1; ja; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 GTB7.1グーグルのウェブ検索のクローラーは次のようなユーザーエージェント名になります。
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)サーバー側でユーザーエージェント名をチェックすれば、検索エンジンのクローラーがページの情報を取りに来ているのか、普通のユーザーがブラウザでページを見ているのか判別できます。
アクセスしているのが検索エンジンのクローラーだとわかったら、次のどちらかの方法で検索エンジン向けのページを読み込ませます。
- リダイレクト
別のURLで表示される検索エンジン向けのページに転送する方法です。ウェブサーバーの設定によってリダイレクトさせる方法と、JavaScriptを使ってブラウザ側でリダイレクトさせる方法があります。
- 動的ページ生成
HTMLページをそのまま表示するのではなく、JavaやPHPなどのプログラムを使って、検索エンジンにだけ特別なページの内容を見せるようにする方法です。
ただし、IPアドレスやユーザーエージェント名によってリダイレクトしたりページの内容を変えること自体が悪いわけではありません。たとえば、IPアドレスからアクセス元の地域を判断し、地域によって異なるページを表示する場合もありますし、ブラウザの性能が悪いIE6にだけ専用ページを見せたりする場合もあります。また、動的ページ生成は多くのサイトで普通に行われています。
ポイントは、「検索エンジンだけに特別なページを見せる」仕組みにしているかどうかです。
ブラックSEO会社はなぜこの手法を使うのか
ブラックSEO会社がクローキングを行うのは、検索エンジンに対して、本来の対策ページでのユーザーへの訴求性をまったく考慮せずに、SEOに特化した内容のページ検索エンジンに認識させられるからです。
SEO会社は通常、順位を上げたいページに対して、対策キーワードや関連するワードをいかに自然に盛り込むかという施策に時間を費やします。
その一方で、ブラックSEO会社は既存のページを気にせず非常に簡単に対策を行いたいがために、キーワードを盛り込んだ検索エンジン向けのページを用意し、クローキングを行うのです。
なぜこの手法が問題なのか
検索エンジンはユーザーと検索エンジンとで異なるコンテンツやURLを表示することを明確に禁止しており、場合によってはインデックスから削除する(検索結果から削除する)ことを明確に示しています。
クローキング、不正な JavaScript リダイレクト、誘導ページ印刷(Googleウェブマスターセントラル)
クローキングとは、ユーザーと検索エンジンとで異なるコンテンツや URL を表示することです。user-agent に基づいて異なる結果を表示するサイトは、偽装の意図があると見なされ、Google インデックスから削除される場合があります。
クローキングには、次のようなものがあります。
- 検索ページには HTML テキストのページを表示し、ユーザーには画像や Flash のページを表示する。
- ユーザー向けとは異なるコンテンツを検索エンジンに表示する。
検索エンジンスパムとは?(Yahoo!検索インフォセンター)
以下は、検索エンジンスパムの例です。
……(中略)……
検索エンジンの検索結果に表示される内容と利用者が目にするウェブページの内容が異なる
NG度+行った場合のリスク
| NG度の表記について | |
|---|---|
| 1 | 無意味な対策です |
| 2 | サイトの評価が下がる場合があります |
| 3 | サイトの順位が下がる場合があります |
| 4 | サイトの順位が大きく下がる場合があります |
| 5 | サイトが検索結果から削除される場合があります |
NG度:5
※サイトが検索結果から削除される場合があります
検索エンジンからクローキングをしているサイトだと認識されると、クローキングを行っているページに限らずサイト全体が検索結果から削除されてしまいます。
過去には独BMWや独リコーのサイトが、クローキングを行っているとして、グーグルの検索結果から削除されてしまった例などがあります(参考リンク)。
どうすれば見つけられるのか
クローキングは「検索エンジンに対して」違うコンテンツを見せる仕組みであるため、それを確実に発見できるのは検索エンジンだけです。
ただし、完全ではありませんが、次のような方法でクローキングを見破れる場合があります。
- ユーザーエージェント名を変更する方法
ユーザーエージェント名を変更する拡張機能(Firefox用、Chrome用)をインストールしたブラウザでページにアクセスして、通常と異なるページが表示されないかチェックします。
その際に、ユーザーエージェント名は次のように設定します(グーグル用)。
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - 検索エンジンの「キャッシュ」を使う方法
検索エンジンはクローラーが取得した内容を「キャッシュ」として保存しています。そのキャッシュをチェックし、通常と異なるページが表示されないかを確認します。
 調査対象ページが表示されるキーワードで検索し、検索結果に表示される「キャッシュ」を確認します。
調査対象ページが表示されるキーワードで検索し、検索結果に表示される「キャッシュ」を確認します。ただし、対象ページで検索エンジンに対してキャッシュを取得させないように指定している場合もあります。HTMLページの<head>部分に、
<meta name="robots" content="noarchive">と入っている場合はキャッシュを禁止しているため、「キャッシュ」リンクは表示されません。逆に言うと、検索結果ページで「キャッシュ」リンクが表示されない場合は、クローキングしていることを第三者に発見されないようにするために禁止している可能性があります。
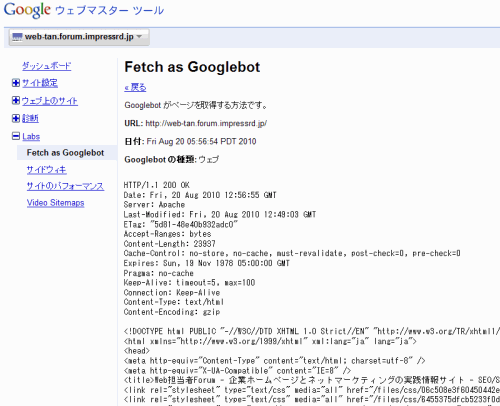
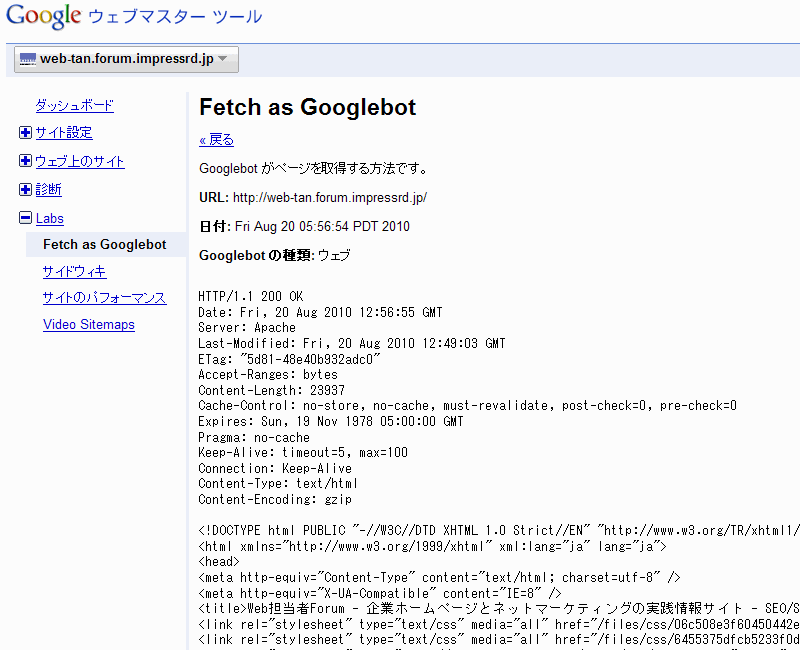
- ウェブマスターツールの「Fetch as Googlebot」を使う方法
ウェブマスターツールに登録している自分の管理サイトであれば、ウェブマスターツールの機能を利用して、グーグルのクローラーからページがどう見えているかを確認できます。
ウェブマスターツールにログインして対象サイトを選び、左のメニューで[Labs]>[Fetch as Googlebot]を選びます。右側に対象ページのURLを指定して[取得]ボタンをクリックします。取得が完了すると、その下に「成功しました」と出て、そのリンクからクローラーが見ているサイトの内容を確認できます。
- Google翻訳を使う方法
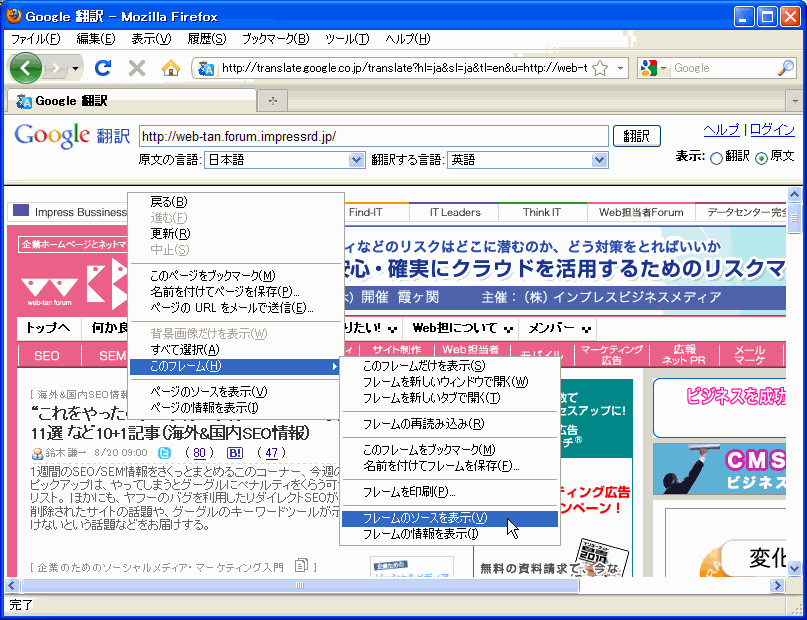
ウェブマスターツールの「Fetch as Googlebot」を使えず、キャッシュの確認もできない場合は、Google翻訳を使います。
Google翻訳で対象ページのURLを指定し、[原文の言語]を「日本語」に、[翻訳する言語]を「英語」に指定して[翻訳]ボタンをクリックします。翻訳結果が表示されるので、上部右端にある[表示]で「原文」を選ぶと、グーグルのシステムが取得したHTMLが表示されます。
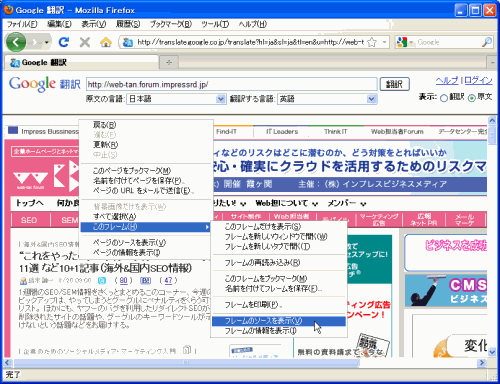 フレームのソースを表示して確認します。
フレームのソースを表示して確認します。ただしこの場合、IPアドレスはグーグルのものになりますが、ユーザーエージェント名はGooglebotとは異なるものになります。
もしやってしまっていたら
もしクローキングを行ってしまっていた場合、ただちにその仕組みを削除しましょう。
すぐに仕組みを変えられない場合は、サイト全体がペナルティを受けないように、クローキング対象ページの<head>部分に次のようなタグを入れることで、検索エンジンのインデックス対象から除外しましょう。
<meta name="robots" content="noindex">すでにクローキングが原因でサイトが検索エンジンから削除されてしまっている場合、上記のように該当している部分を削除したうえで、グーグルではウェブマスターツールに登録し、サイトの再審査依頼をしましょう。
ヤフーでは、インデックスの更新などのタイミングで順位が戻るのを待つ必要があります。
まずは自分が取り組みやすい発見方法を用いて、自分で管理しているサイトのチェックをしてみてください。
- この記事のキーワード
バックナンバー
この記事の筆者
株式会社イトクロ+Web担編集部
株式会社イトクロは、高度なSEO・SEMノウハウを社内に蓄積し、それを活用して多くのお客様に、より正確で価値のある情報を提供しているウェブコンサルティング会社。
大手企業からベンチャー企業まで現在数百社を対策中のSEOサービス「とにかくあがるくん」は、検索エンジンからペナルティを受ける可能性のある危険なSEOは行わず、安定して上位を目指すサービス。





