【プロなら余裕?】SEOがデキる人かどうか見極めるシンプルだけど効果的な質問【SEO情報まとめ】
あなたは検索エンジンとSEOをちゃんと理解できているか? 「クロール」「インデックス」「ランキング」「レンダリング」や「HTMLソース」「DOM」「レンダリング」の違いを説明できるだろうか
2022年7月15日 7:00

あなたは検索エンジンとSEOをちゃんと理解できているか?
「クロール」「インデックス」「ランキング」「レンダリング」や「HTMLソース」「DOM」「レンダリング」の違い ―― これを正しく説明できれば、あなたもSEOの専門家に仲間入り?
今回は、上記テーマの2記事をピックアップ。ほかにも、リッチリザルトとSERPでのCTR、グーグルの細かい挙動、動画SEOなどなど、あなたのSEO力をアップさせる良情報をお届けする!
- ★3つ未満の低評価は構造化データナシにしたら、SERPでクリック率UP⬆?
- 404と410をグーグルは本当に同じように扱うのか? (いやちょっと違う)
- 2022年6月のオフィスアワー+動画コンテンツのベストプラクティス
- 他のウェブサイトからのクチコミを構造化データでマークアップしてはいけない
- 不正リンクを集めた経歴がゼロなら、リンク否認はもう必要なし
- ユーザーが本当に求めているコンテンツはキーワード調査ツールでは見つけられない
- 言語や文字が一致しないページのタイトルリンク生成アルゴリズムをグーグルが改善
- GA4がとっつきにくい5つの理由とその対処法
- Googlebotの15MBクロール制限によくある質問とその回答
- Search Console InsightsがGA4をサポート(関連付け設定が必要)
今週のピックアップ
【プロなら余裕?】SEOがデキる人かどうか見極めるシンプルだけど効果的な質問
クロール・インデックス・ランキング・レンダリングの違いを説明せよ (Danny Sullivan on Twitter) 海外情報
米国の腕利きSEOコンサルタントのリリー・レイ氏は、採用の面接時に応募者がSEOに精通しているかどうかを見極めるために次のような質問を投げかけるそうだ:
次の違いを説明してください:
- クロール
- インデックス
- ランキング
- レンダリング
グーグル検索の広報役として活動しているダニー・サリバン氏も感嘆する質問だ。
Says @lilyraynyc about hiring good SEOs: “We ask them the difference between crawling, indexing, ranking and rendering. You’d be surprised how many get this wrong.” I’m paraphrasing her, and it’s an excellent question #SearchCentralNYCSEOmeetup pic.twitter.com/rlcAVc3wVK
— Danny Sullivan (@dannysullivan) June 27, 2022
筆者も、非常に良い質問だと感じる。これらのプロセスは検索結果ができあがるまでの処理であり、理解しておくことはSEOにおける基盤だ。
レイ氏が質問する4つのプロセスをごく簡潔に説明すると次のようになる。
クロール ―― クローラと呼ばれるプログラム(グーグルでは Googlebot)がウェブ上のコンテンツを取得するプロセス。URLによって新しいコンテンツを発見する。コンテンツにはウェブページだけではなく、画像や動画、音声なども含む。
インデックス ―― クローラが取得したコンテンツを保存するプロセス。そのコンテンツのURLや、titleタグ、ページ内テキストなどのさまざまな情報をデータベースに格納する。
ランキング ―― 検索結果を決定するプロセス。ユーザーのクエリに最も関連性が高いコンテンツを検索結果で提供するために、インデックスから取得していくつものシグナルに基づいて表示順を決定する。
レンダリング ―― ウェブサーバーから取得したソースHTMLのを分析し、JavaScript や CSS などを処理してブラウザでの表示内容に変換するプロセス。現在のグーグルは、この内容をもとにランキングやインデックスを行う。そのため、ページ内容をGooglebotが適切にレンダリングできる状態にしておくことはとても重要だ。
クロールとインデックス、ランキングに関してはグーグル検索の仕組みを解説するサイトに説明がある。レンダリングに関しては、マーティン・スプリット氏が解説する動画を今回紹介した。適切に説明できる自信がなければきっちり理解しておこう。
- すべてのWeb担当者 必見!
技術者じゃなくてもわかる「ソースHTML」「DOM」「レンダリングされたHTML」の違い
グーグル社員が超わかりやすく解説 (Search Central Lightning Talks on YouTube) 海外情報
ウェブサーバーから取得したHTMLをブラウザが処理する仕組みをグーグルのマーティン・スプリット氏が動画で解説した。具体的には次の 3つの技術的要素を説明している:
- ソースHTML
- ドキュメントオブジェクトモデル(DOM)
- レンダリング結果
さらに動画の終盤では「レンダリングされたHTML」についても触れている。
開発者にとってはなんてことのない、馴染みの技術要素だ。しかし一般のウェブ担当者にとっては、言葉は聞いたことがあってもイマイチ理解できていないかもしれない。スプリット氏は非常にわかりやすく説明している。テクニカルSEOの第一歩としてオススメの動画解説だ。
なおスプリット氏は英語で話しているが、日本語字幕を利用できる。自然な日本語になっているので安心して字幕に頼っていい:
- すべてのWeb担当者 必見!
グーグル検索SEO情報①
★3つ未満の低評価は構造化データナシにしたら、SERPでクリック率UP⬆?
クリックをためらう要因を排除したためか (Semrush Blog) 海外情報
おもしろい実験のレポートがあった。次のようなものだ:
検索結果に表示されるレビュー(口コミ)のうち、「★」が少ないものを削除すると検索トラフィックが増えた。
レビュー(クチコミ抜粋)の構造化データをマークアップすると、リッチリザルトとして検索結果に「★」の数で評価を表示できる。検索結果でのクリック率向上にリッチリザルトは役立つ。
だが逆に、レビューのリッチリザルトがクリック率を下げてしまうことがあるかもしれない。それは評価が低い(★の数が少ない)場合だ。
そこで、Semrush(エスイーエムラッシュ)は次のようなテストを行った:
5つ星評価で★の数が3よりも低い場合はリッチリザルトを表示させないようにする。
テスト結果は、クリック数(検索トラフィック)が21%増加したとのことだ。
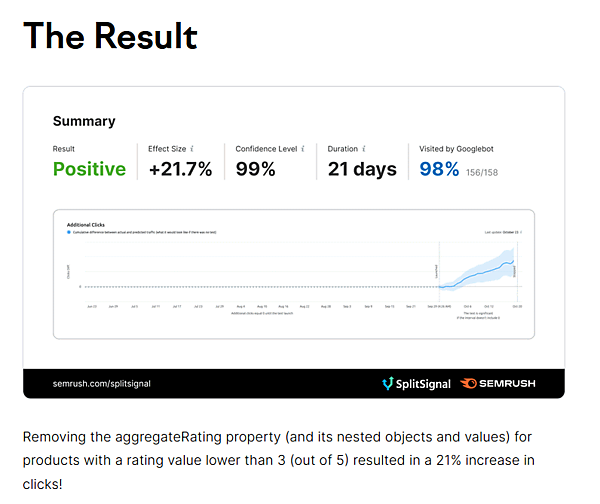
リッチリザルトで見える評価が低いことが、かえってクリックする気を失わせていたのだろう。クリックをためらわせる要因を排除したために検索結果でのクリック率が高まったのだと推測できる。
評価が低い商品やサービスでは、場合によってはレビューリッチリザルトを表示させないようにするのは試す価値があるように思える。
だが、Semrushは慎重になるようにも促している。クリックはたしかに増えたのだが、評価が低い商品のページはもともと検索トラフィックが少なかったため、増えたといっても増加分は微々たるものだったそうだ。サイト全体で見ると著しいトラフィック増加ではなかったとのことである。
そもそも、評価が低いのならば、リッチリザルトを非表示にする前に商品やサービスを改善する動きを先に行うべきだ。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
404と410をグーグルは本当に同じように扱うのか? (いやちょっと違う)
再クロールの頻度に違いがあった (Reboot Online) 海外情報
削除ずみページにアクセスがあった場合、Webサーバーは404または410のHTTPレスポンスステータスコードを返す。そうすればグーグルは、ページがもう存在しないことを認識しインデックスから削除する。
ただし、404と410は技術的には異なる。定義上の違いは次のとおりだ:
| ステータスコード | 意味 |
|---|---|
| 404 | 「Page not found(ページが見つからなかった)」 |
| 410 | 「Gone(ページが削除された、なくなった)」 |
しかし、グーグルは404と410を同じように扱う。もっと正確に言えば、429を除くすべての4xxエラーをグーグルは同じように扱う。
しかし、本当にまったく同じ扱いなのだろうか?
Reboot Online Marketing(リブート オンライン マーケティング)が、404と410の扱いに違いがあるかどうかを実験で検証した。すると次のような相違が見られたそうだ:
404を返すURLは、410を返すURLよりも平均して49.6%頻繁に再クロールされた。
具体的な調査結果は次のようなものだ:
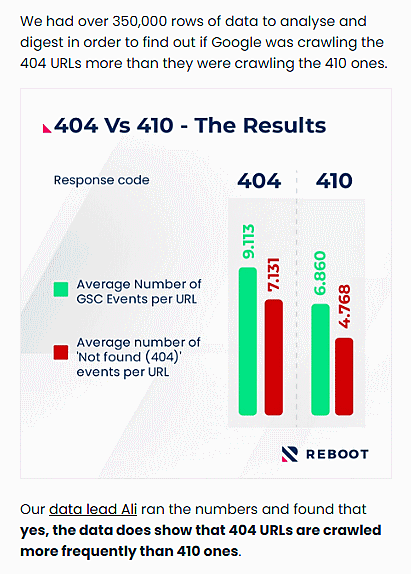
このデータは、「404を返すようにしたページ」と「410を返すようにしたページ」で、Google Search Consoleに記録されるイベント(レポート)がどう異なるかを調査したもの。
緑がSearch Consoleのイベント(レポート)数、赤がそのうち「見つかりませんでした(404)」のイベント数(どちらもURLあたりの平均数)を示している。
404を返すページのほうが、「見つかりませんでした(404)」イベント数が、410を返すページよりもページあたり平均で49.6%多かったことがわかる。
この傾向は、URLに対するサイト内リンク数で分けてみても同様だったという。
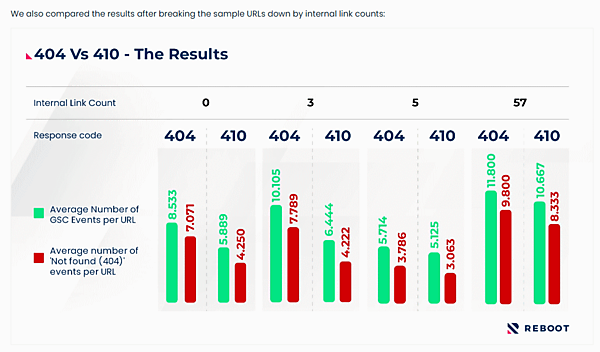
内部リンク数(最上行)ごとのデータ
404であろうが410であろうがそのほかの400番台のURLであろうが、グーグルはときおり再クロールする。URLに依然としてアクセスできないことを確かめるのが目的だ(ひょっとしたらページが復活しているかもしれないからだ)。
ところが検証により、再クロールの頻度は410の方が低いという結果が出た。この結果はあながち間違ってはいないのかもしれない。もう10年も前の話になるが、ジョン・ミューラーが調べたところ、グーグル検索では、410を返すURLの方が404を返すURLよりも再クロールの頻度が低い仕様になっているとのことだった。今でもその仕様が有効であるなら、実験結果は正しいということになる。
もっとも、404と410の違いを実運用で意識する必要はないだろう。404の方が再クロール頻度が高いからといって、通常のURLよりはずっと低いのだから、サーバーに過度な負荷をかけるとは考えづらい。存在しないURLは、404または410(もしくは、429以外の4xx)のステータスコードを返しておけば問題ない。
※429は、特定ユーザーが単位時間ないにリクエストを多く送信し、Rate Limitingを超えたため失敗したことを意味するHTTPレスポンスコード。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
- 技術がわかる人に伝えましょう
2022年6月のオフィスアワー+動画コンテンツのベストプラクティス
いつものQ&Aとは別枠のスペシャルセッションあり (Google ポリシー オフィスアワー on YouTube) 国内情報
2022年6月のオフィスアワーをグーグルの金谷氏と小川氏が開催した。
今回はいつもと体裁が異なっている。Q&Aに入る前に、スペシャルセッションとしてライトニングトークがある。テーマは「動画コンテンツのベストプラクティス」だ。ゲストとして登場したゆきこ氏が、グーグル検索で動画コンテンツを目立たせる施策を説明している。主力コンテンツとして動画を配信しているなら非常に役立つ内容だ。視聴してほしい。
ライトニングトークの後に、金谷氏と小川氏がいつものように回答した質問は次のとおりだ:
- 動画のベスト プラクティス(15:30)
- サイト内多くのページがインデックスされない(18:18)
- リダイレクトの挙動(23:01)
- 大規模サイトのフロントエンド(25:19)
- 正規 URL が適切に選択されない ①(28:19)
- 正規 URL が適切に選択されない ②(30:58)
- 手動による対策の対象となる得るサイトを発見(32:30)
- タイトルの書き換え(37:50)
- Google による意図しない正規化(40:34)
- CLS の原因要素が特定できない(43:10)
- 商品ページのマークアップに誤表記(46:35)
- ハッキングされているサイトの通報方法(49:19)
- 新機能のローンチ予定(54:05)
- 有罪判決を受けたサービスに個別処置があるか(56:21)
- 動画SEOがんばってる人 必見!
- この記事のキーワード
関連記事
グーグル重鎮「上位表示したいならSEOブログは読むな」発言で業界を敵にまわす!?【SEO情報まとめ】
2022年8月19日 7:00
ChatGPTでSEOは終わった? そんな軽いコンテンツじゃ昔から上位表示は難しかった気がする【SEO情報まとめ】
2023年5月26日 7:00
あなたも同じミスをするかも? robots.txtのミスで予想外のページをクロール禁止していた悲劇【SEO情報まとめ】
2022年11月4日 7:00
音声検索は、女性より男性、高学歴ほどよく使う!? 利用実態1000人調査データ【SEO記事11本まとめ】
2018年2月2日 7:00
【Google公式】英語版SEOオフィスアワーの最新TIPS特集: ページ分割・サイトマップ・title・リダイレクトなどなど【SEO情報まとめ】
2023年1月20日 7:00
検索エンジンは短いtitleタグ・長いdescriptionがお好き――Etsy独自調査【SEO記事12本まとめ】
2017年2月3日 7:00
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00




