重複コンテンツが発生してしまう19の具体的なパターン - 重複コンテンツ対策完全ガイド #3
サイト構成、システム、ドメイン名、商品一覧ページなど、さまざまな側面から具体的に解説。
2012年2月13日 9:00
この記事はパンダ・アップデートによって変化した重複コンテンツの問題を広範に扱った長文の記事で、4回に分けてお届けしている。3回目となる今回は、重複コンテンツの具体例を見ていこう。

パンダ・アップデート対応版
V 重複コンテンツの具体例
ここまでで重複コンテンツを理解して、重複コンテンツを修正するツールを整理した。
では、重複コンテンツとして実際にはどのようなものがあるのだろう? ここでは、現実のウェブサイトで想定される重複コンテンツ問題の典型例を取り上げよう。ここで説明するのは、次のようなものだ。
- 「www」の有無
- ステージングサーバー
- URL末尾のスラッシュ(/)
- セキュア通信のページ(https)
- トップページの重複
- セッションID
- アフィリエイトのトラッキング
- 経路の重複
- 機能的パラメータ
- 国別コンテンツによる重複
- 検索結果のソート(並べ替え)
- 検索フィルタ
- 検索結果のページネーション(ページ分割)
- 製品のバリエーション
- キーワードとなる地名を書き換えただけのページ
- その他の「薄い」コンテンツ
- 配信されたコンテンツ
- 剽窃コンテンツ
- ccTLD間の重複
それぞれについて説明していこう。このセクションでは、セクションIVで取り上げたツールを参照する。たとえば、301リダイレクトに言及する場合は、(IV-2)と記す。
Ⅴ-1 「www」の有無
サイト全体が重複コンテンツとなる場合は、おそらくこれが最大の原因だろう。サイト内リンクで間違えたり、間違ったURLへのリンクや言及をされたりして、「www」ありのURLと、「www」なしのURL(ルートドメイン)が、どちらもインデックス化された場合に起きる問題だ。

多くの場合、この問題に対しては301リダイレクト(IV-2)が最善の策となる。よくある問題であり、グーグルはこういった場合のリダイレクトをうまく処理してくれる。
また、Googleウェブマスターツール(GWT)で使用するドメイン名を設定しておくのもいい。[サイト設定]>[設定]を選ぶと、[使用するドメイン]というセクションがある。
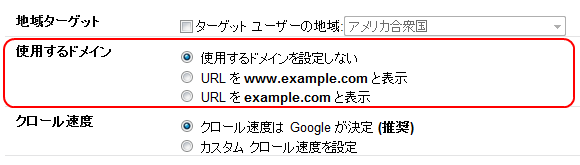
GWTには妙な癖があり、使用するドメイン名を設定するのに、「www」ありと「www」なしの両方についてGWTのプロファイルを作る必要がある場合がある。面倒ではあるが、不都合なことは何もない。URL正規化で大きな問題が生じているなら、これがお勧めだ。
ただし、大きな問題が出ていないのなら、そのままにしておいて、使用するドメイン名の選択をグーグルに任せてもいい。
Ⅴ-2 ステージングサーバー
Ⅴ-1に比べるとそれほどよくある例ではないが、こういった問題はサブドメインが原因で起きることも多い。
典型的シナリオはこうだ。サイトのリニューアルで新しいデザインに取り組んでいて、開発チームがテストサイトをサブドメインで作っていたところ、うっかりクローラーを受け入れる状態のままにしてしまった。この場合は次のように、URLが2種類ずつインデックス化されてしまう。

最善の策は、ステージングサイトをrobots.txt(IV-3)でブロックして、問題の発生を未然に防ぐというものだ。
だが、ステージングサイトがすでにインデックス化されてしまった場合は、301リダイレクト(IV-2)や、meta robotsタグ(IV-4)によるnoindexの指定が必要になるだろう。
Ⅴ-3 URL末尾のスラッシュ(/)
これについては頻繁に質問を受けるが、SEOでは以前ほど問題ではなくなっている。
厳密に言えば、本来のHTTPプロトコルにおいて、末尾にスラッシュがあるURLとないURLは別のURLだ。簡単な例を挙げる。

最近では、ほぼすべてのブラウザが裏側の処理で自動的に末尾のスラッシュを追加して、両方のURLを同じように扱う。マット・カッツ氏は最近のビデオで、グーグルが「非常に多くの場合」このようなURLを自動的に正規化していることをほのめかしている。
Ⅴ-4 セキュア通信のページ(https)
サイトにセキュア通信を使用しているページ(「https:」プロトコルが指定されている)がある場合、セキュア版(https:)と非セキュア版(http:)が両方ともインデックスされてしまうことがある。
原因の多くは相対パスなのだが、ショッピングカートなどのセキュア通信のページからのナビゲーションリンクに「https:」プロトコルが指定され、次のように異なるURLが生成される。

この問題は、サイトのアーキテクチャそのもので解決するのが望ましい。たいていは、セキュア通信のページをmeta robotsタグ(IV-4)でnoindexに指定しておくのが最善だ。ショッピングカートや会計のページが検索エンジンのインデックスにあっても意味がないからだ。
インデックス化されてしまった場合は、301リダイレクト(IV-2)が最善の選択肢だ。ただし、サイト全体に手を入れる場合は注意が必要だ。たとえば、すべての「https:」ページを対応する「http:」のページに301リダイレクトすると、セキュリティが丸裸になってしまいかねない。扱いが難しい問題なので、慎重に対処すべきだ。
Ⅴ-5 トップページの重複
トップページの重複はⅤ-1~Ⅴ-3が原因で生じる可能性があるが、トップページには特有の問題がいくつかある。
最も一般的なのは、ドメイン名だけ(ファイル名なし)のURLと実際のHTMLドキュメントのファイル名を含んだURLが、どちらもインデックスされるというものだ。例を挙げる。

この問題は301リダイレクト(IV-2)でも解消できるが、トップページにURL正規化タグ(IV-5)を使うとうまく行くことが多い。トップページはほかと比較にならないほど重複で苦労するのだが、あらかじめ正規化タグを使うことで多くの問題を回避できる。
もちろん、サイト内リンクの構造(IV-12)を統一しておくのが大事だ。ドメイン名だけのURLを正規のURLとして扱いたいのに、ナビゲーションの中で「/index.htm」にリンクすると、クローラーが来るたびに混乱したシグナルをグーグルに送ってしまう。
Ⅴ-6 セッションID
一部のサイトでは、訪問者が来るたびに追跡用のパラメータを付与したURLを生成している(特にEコマースサイトなど)。場合によっては、そのパラメータが付いたURLがインデックス化されてしまうことがある。

上の画像ではこの問題の大きさが伝わらないのだが、実際には、異なるセッションIDとページの組み合わせがすべてインデックスされてしまう可能性がある。URLにセッションIDがあると、優に何千もの重複ページがインデックスされかねない。
利用しているCMSやEコマースのシステムにもよるが、セッションIDはURLから外してクッキーに保存しておくのがベストだ。セッションID付きのURLなど作っても役に立つことはほとんどないし、ロボットにクロールさせるのも無意味だ。
クッキーに保存できないなら、サイト全体にURL正規化タグ(IV-5)を置くのがいいだろう。どうにもならなくなった場合は、Googleウェブマスターツール(IV-7)やBing Webmaster Center(IV-9)でパラメータをブロックする手がある。
Ⅴ-7 アフィリエイトのトラッキング
これはⅤ-6のセッションIDとよく似た問題だ。アフィリエイトを利用しているときに、アフィリエイターが張るリンクには、そのアアフィリエイターを追跡するパラメータを使うことが多い。その際に生じるのだ。
アフィリエイター追跡パラメータは一般的に、ランディングページのURLに追加される。

被害の大きさはⅤ-6ほどではないが、それでも大規模な重複が生じる可能性がある。
解決法はセッションIDのケースと似ている。アフィリエイトのIDはクッキーに保存し、正規URLに301リダイレクト(IV-3)するといい。無理な場合は、URL正規化タグ(IV-5)を使うか、アフィリエイトURLのパラメータをブロックすることが必要になるだろう。
Ⅴ-8 経路の重複
ページへの経路が複数あるのはまったく問題ないが、複数の経路によって複数のURLが生成されるのは問題だ。たとえば、以下の3つのいずれでも製品ページにたどり着けるとする。

この例にあるiPad2の製品ページへは、2つのカテゴリとユーザーが作った1つのタグから到達できる。ユーザーが「家電」カテゴリからiPad2を選ぶと「/electronics/ipad2」というURLで表示され、「アップル」カテゴリからiPad2を選ぶと「/apple/ipad2」というURLで表示されるといったようにしているときに生じる問題だ。
ユーザーによるタグはとりわけ問題がある。理論的には、同じコンテンツに対してさまざまなタグによるさまざまなURLが無制限に生成される可能性があるからだ。
経路に基づくURLは、一切作らないのが望ましい。どこを経由してページたどり着く場合も、SEO的には1つのURLにするべきだ。経路がURLに含まれているのは、サイトの訪問者にとってメリットだという意見もあるだろうが、ユーザビリティに関わった経験から言っても、ほぼすべての場合にデメリットがメリットを上回ると思う。
すでに何通りかのURLがインデックス化されている場合は、301リダイレクト(IV-2)かURL正規化タグ(IV-5)を使うのがおそらく最善の選択肢だろう。ただし多くの場合、リダイレクトで簡単に処理できないほど何通りものURLができているかもしれないので、正規化タグを組み込むほうが簡単だろう。
とはいえ、長期的には、サイトのアーキテクチャを再検討することが必要になる。
Ⅴ-9 機能的パラメータ
機能的パラメータとは、わずかに異なるページを生成するURLパラメータのことだが、検索的には価値がなく、本質的には重複だ。
たとえば、すべての製品ページに印刷用のバージョンが用意してあり、独自のURLが振られているとしよう。次のようなURLになるだろう。

ここで、「print=1」というURLのパラメータは、印刷用のバージョンであることを示している。印刷用のページは普通、印刷向けのテンプレートが使われているだけで、内容は同じだ。meta robotsタグ(IV-4)によるnoindexの指定などを使ってインデックス化を一切しないのがベストだが、URL正規化タグ(IV-5)を使ってこういったページを整理する方法もある。
Ⅴ-10 国別コンテンツによる重複
同じ言語を使っている複数の国に向けたコンテンツを、同じドメイン名に置いてある場合(サブフォルダだったり、サブドメインだったりする)、この重複が問題になる。
たとえば、米国、英国、そしてオーストラリア向けに、英語版の製品ページがそれぞれ次のように存在するかもしれない。

残念ながら、この重複は少々手ごわい。グーグル側が見事に処理して、適切なコンテンツを適切な国でランキングに入れてくれる場合もある。一方で、きちんとジオターゲティングをしているのにうまく処理してくれないケースもある。国よりも言語でターゲティングするほうがよい場合が多いのだが、価格などのように、国ごとにコンテンツを分けるべき正当な理由もある。
国別に分けたコンテンツが重複コンテンツとして扱われた場合、簡単な解決法はない。301リダイレクトを行うと、訪問者がページに行けなくなる。URL正規化タグを使うと、1つのバージョンしか検索結果に表示されなくなる。「正しい」解決法は状況によって大きく異なり、現実には、リスクとリターンのバランス(そしてフィルタリング/ペナルティの危険が及ぶ範囲)に応じて判断することになる。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




