パンダ・アップデート後の重複コンテンツを知る - 重複コンテンツ対策完全ガイド #1
重複コンテンツの問題とその対策を広範かつ詳細に解説していく(全4回のうち第1回)
2012年1月30日 9:00

パンダ・アップデート対応版
この記事の内容はすべて筆者自身の見解であり(ありそうもないことだが、筆者が催眠状態にある場合を除く)、SEOmozの見解を反映しているとは限らない。
もしかしたら、僕らはパンダ・アップデートに関して少しばかり感傷的になり始めているのかもしれない。確かにパンダ・アップデートでSEOのすべてが変わったわけではないけれど、あまりに長いこと皆が無視してきたSEOの諸問題に注意を喚起するきっかけになったのではないだろうか。
そういった問題の1つが「重複コンテンツ」だ。重複コンテンツはもう何年もSEOにおける問題になっているが、グーグルの対処方法は劇的に進化してきて、アップデートのたびにどんどん複雑化しているようだ。そして、パンダ・アップデートでまた一段と飛躍した。
そんなわけで僕は、2011年の現状を踏まえて、重複コンテンツの話題を掘り下げるのにふさわしい時だと考えた。今回の記事で目指すのは包括的なリソースであり、重複コンテンツとは何なのか、いかにして生じるのか、どうやって診断するのか、そしてどのように修正すればいいのかを、網羅して論じるものだ。
うまくいけば、途中で不良パンダを何匹かつかまえられるかもね。
I 重複コンテンツとは何か?
基本から始めよう。重複コンテンツとは、同じコンテンツのページが2つ以上ある状態のことだ。視覚的に理解したければ、下のイラストを見てもらいたい。

簡単なことだ。それでは、これほど簡単なものがなぜ大変な苦労の原因になっているのだろう?
1つの問題は、「ページ」とはウェブサーバに置かれているファイルや書類のことだという誤解が多いことだ。Googlebotなどのクローラーにとって、ページとはサイトからサイトへ、あるいはサイト内で張られたリンクをたどる中で出くわすそれぞれのURLを意味する。規模が大きい動的なサイトでは特に、結果的に同じコンテンツとなる2つのURLが(意図せず)驚くほど易々と生まれてしまう。
II 重複コンテンツが問題になるのはなぜか?
SEO上の問題としての重複コンテンツは、パンダ・アップデートのずっと以前からあった。しかし、アルゴリズムの変更に伴ってその形態はさまざまに変化してきた。長年にわたる重複コンテンツの主要な問題を手短に振り返ってみよう。
II-1 補足インデックス
グーグルの草創期、ウェブのインデックス化はコンピュータ処理においての大きな難問だった。この難問に取り組むため、重複コンテンツや、品質が低いと見なされたページの一部は、「補足」インデックスと呼ばれる副次的なインデックスに入れられた。SEO的観点から見ると、そこに入ったページは自動的に2級市民となり、検索で上位を狙える競争力を失った。
補足インデックスは2006年ごろにメインインデックスと統合されたが、検索結果からはこのようなページがしばしば除外されている。ご存じのように、グーグルの検索結果の最後に次のような警告があれば、除外されたページが存在する。

インデックスが統合されても検索結果は依然として「除外」されていたので、SEOへの影響は明確だった。
とはいうものの、こうして除外されたページの多くは重複コンテンツだったり検索としての価値がほとんどないものだったりで、SEO上の現実的な影響はごくわずかだったが、常にそうだとは限らなかった。
II-2 クロール・バジェット
グーグルなどの検索エンジンがサイトを訪問した際にクロールするページ数のこと。
グーグルに関して限界を話題にするのはいつだって難しい。というのも、皆が絶対的な数字を知りたがるからだ。クロール・バジェットについて、絶対的な数値というものは存在しないのが実情だ。
とはいえ、グーグルが君のサイトのクロールをしばらく放棄してしまうかもしれないポイントはある。特に君のサイトが、効率よくページにたどりつけないような、曲がりくねった経路にスパイダーをいつも追い込んでいるなら要注意だ。
特定のサイトを考えたところで、クロール・バジェットの絶対的な値は決まらないが、自分のサイトへのクロールの割り当ては、Googleウェブマスターツールの[診断] > [クロールの統計情報]で感じをつかむことができる。
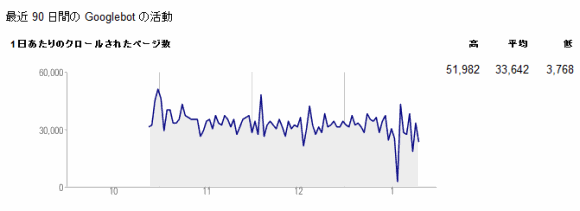
それでは、グーグルが大量の重複パスや重複ページを見つけて、その日のクロールをやめてしまうとどうなるのだろう? 実際の話、インデックス化してほしいページがクロールされなくなるかもしれない。クロールの頻度が低くなる程度で済めば、おそらく運がいいほうだ。
II-3 インデックス化の「上限」
グーグルが1つのサイトでインデックス化するページ数に固定の「上限」がないのは、クロール・バジェットの絶対値がないのと同様だ。
しかし、動的な限度はあるようで、その限度はサイトのオーソリティに関係している。インデックスが役に立たない重複ページで埋まると、より重要な、より深い階層のページが押し出されてしまう可能性がある。たとえば、サイト内検索の結果を何千ページも置いていると、グーグルがインデックス化してくれない製品ページが出てくるかもしれない。
「単にインデックス化されたページが多いほど良い」というのは、たくさんの人が犯している勘違いだ。僕はその逆が正しい状況を多すぎるほど見てきた。他の条件がすべて等しいなら、肥大化したインデックスは検索順位獲得能力を薄めてしまう。
II-4 ペナルティをめぐる議論
パンダ・アップデートよりずっと以前、重複コンテンツにペナルティがあるのかをめぐり、数か月ごとに議論が起きていた。議論の論点は妥当なもので、しばしば意味論が中心になった。つまり、重複コンテンツで極刑に処されるか、つまりインデックスから抹殺されるかということだ。
ペナルティとフィルタリングの概念上の違いは重要だとは思うが、サイトのオーナーからすると、多くの場合、結果は同じだ。重複コンテンツが原因でページが検索結果に表示されない(あるいは、インデックス化されない)なら、どう呼ぶかにかかわらず問題に直面することになる。
II-5 パンダ・アップデート
(2011年2月に始まった)パンダ・アップデート以後、重複コンテンツの影響は一部で深刻さを増している。それまで重複コンテンツによる損害は、その重複コンテンツ自体に限られていた。重複コンテンツがあると、それが補足インデックスに入れられるか、フィルタリングで除外される程度で、通常は問題なかった。極端な例では、大量の重複コンテンツがインデックスを埋めつくしたり、クロールの問題を招いたりして、他のページに影響し始めることもあったけれど。
しかし、パンダ・アップデートによって、重複コンテンツは品質を算出するより大きな計算式の一部に組み込まれ、サイト全体に影響する可能性が出てきた。パンダに直撃されると、重複コンテンツではないページが順位獲得能力を失い、検索結果に表示されなくなったり、あるいはインデックスから外されたりすることさえ起こり得る。重複コンテンツはもはやそれのみの問題ではなくなったわけだ。
III 3種類の重複コンテンツ
重複コンテンツの例やそれに対処するためのツール類を具体的に紹介する前に、重複コンテンツを次の3種類に大別して説明しておきたい。
- 完全重複
- 不完全重複
- ドメイン名間重複
記事の後半では、これら3タイプの重複を、具体例を挙げながら解説していこう。
(1)完全重複
完全重複とは、2つのページの内容が100%同じ状態を言う。違いはURLだけだ。

(2)不完全重複
不完全重複とは、2つのページの内容がほんの少しだけ異なる状態を言う。違っているのはテキストの一部や画像、あるいは単にコンテンツの順序だけということもある。

どれだけ違っていれば「少しだけ」なのかを厳密に定義するのは難しいが、後でいくつか例を挙げて詳しく説明しよう。
(3)ドメイン名間重複
ドメイン名間重複は、2つのウェブサイトが同じコンテンツを持っている場合に起こる。

ドメイン名間重複は、「完全重複」の場合もあれば「不完全重複」の場合もある。通信社などから正式に配信されたコンテンツでさえ、ドメイン名間重複が問題となり得ることは、意外に知られていない。
この記事は、パンダ・アップデートによって変化した重複コンテンツの問題を広範に扱った長文の記事であり、全部で4回に分けてお届けする。次回は、重複コンテンツを防ぐ方法について紹介する。
- この記事のキーワード
関連記事
URL正規化のポイントと重複を診断する4つのツール- 重複コンテンツ対策完全ガイド #4
2012年2月20日 9:00
重複コンテンツ問題を解決する12の手段 - 重複コンテンツ対策完全ガイド #2
2012年2月6日 9:00
検索エンジンが提供しているウェブマスター向けツール - 『検索エンジン最適化の初心者ガイド』改訂版#8-2
2009年1月30日 9:00
マット・カッツ氏「ブラックハットSEO対策とウェブマスター支援に力を注ぐ」 など10+4記事(海外&国内SEO情報)
2012年10月26日 9:00
ダメコンテンツを量産するより“ビッグコンテンツ”に挑戦するべき理由とその方法(後編)
2012年11月12日 9:00
クロールされているけどインデックス化されていないページの謎
2009年9月29日 9:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




