URL正規化のポイントと重複を診断する4つのツール- 重複コンテンツ対策完全ガイド #4
正規のURLを決定する上で注意すべき点と、重複を診断するツール類について説明。
2012年2月20日 9:00
この記事はパンダ・アップデートによって変化した重複コンテンツの問題を広範に扱った長文の記事で、4回に分けてお届けしている。最終回となる今回は、正規のURLを決定する上で注意すべき点と、重複を診断するツール類について説明していこう。

パンダ・アップデート対応版
VI 正規のURLはどれか?
ここで少し回り道をして、ある重要な問題を議論してみたい。次のようなものだ。
301リダイレクトを使うにせよURL正規化タグを使うにせよ、本当に正しい正規URLはどれかを判断するにはどうすればいいのだろうか?
しばしば見られる間違いとしては、「多くのページから不適切なURLに正規化してしまう」というものがある。たとえば次のようなものだ。

本来ならば「product.php?id=1234」のような製品個別のページに正規化しなければいけないのに、間違って「product.php」という単なるテンプレートページに正規化してしまっている例だ。
これでは、たった1つの(おそらくは製品を表示さえしていない)ページがすべての製品を代表してしまうことになる。
正規のページは、最もシンプルな形のURLだとは限らない。他とは違うコンテンツを生成する最もシンプルな形のURLだ。たとえば、下の3つのURLが同じ製品ページを生成するとしよう。

3つのうちの2つは本質的に重複ページであり、「print」や「session」というパラメータは、正規ページとすべきメインの製品ページのバリエーションを表している。ただし、「id」パラメータは、そのコンテンツにとって不可欠なものだ。どの製品が実際に表示されるかは、このパラメータが決めるからだ。
重複コンテンツの乱造と同じくらい、適切でないURL正規化がさらなるダメージを招くケースもある。慎重に計画を練り、正しい正規URLを選んでいることを入念に確認した上で、正規化を進めよう。
VII 重複を診断するツール類
重複コンテンツがどういうものかを理解したところで、自分のサイトに重複があるかどうかを調べるにはどうしたらいいだろう? 手始めに、以下のツールを見てみよう。
- Googleウェブマスターツール
- グーグル検索の「site:」コマンド
- SEOmozのCampaign Manager
- 自分の頭を使う
それぞれについて説明していく。これが完璧なリストだなどと言うつもりはないが、基本的なものは押さえてある。
VII-1 Googleウェブマスターツール
Googleウェブマスターツール(GWT)では、ロボットがクロールしたtitle要素とmeta descriptionタグの重複リストを取り出せる。できることはこれだけだが、出発点としてはなかなかだ。
URLをベースとした重複の多くは、メタデータが同じになっている。GWTのアカウントから[診断]>[HTMLの候補]を選ぶと、下のような表が出てくるはずだ。
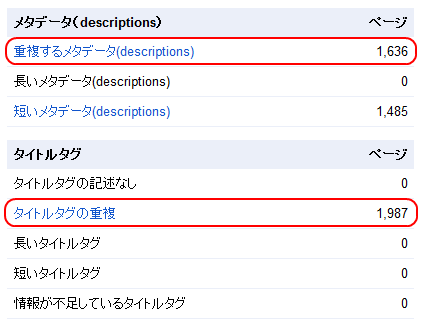
「重複するメタデータ」や「タイトルタグの重複」をクリックすると、重複のリストを取り出せる。これは問題のある箇所を見つけ出すのに素晴らしい足がかりとなる。
VII-2 グーグル検索の「site:」コマンド
どこに問題があるかがすでに分かっていて、もっと突っ込んだ対策を講じる必要がある時は、グーグルの「site:」コマンドが非常に強力かつ柔軟なツールになる。「site:」コマンドが強力なツールになる理由は、他の検索演算子と組み合わせて使用できる点にある。
たとえば、トップページの重複が気になっているとしよう。グーグルがトップページの重複ページをインデックス化しているかどうかを調べるためには、下の例のように「site:」と「intitle:」を一緒に使うといい
ひとまとまりのフレーズとして検索するためにタイトルを半角の二重引用符で囲んで指定する。重複コンテンツを全部はき出させるには、必ず(wwwを除いた)ドメイン名をsite:に指定しよう。これでwww付きバージョンとwwwなしバージョンの両方が見つかるだろう。
もう1つの強力な演算子の組み合わせは「site:」と「inurl:」だ。「inurl:」は指定したキーワードがページのコンテンツではなくURLの文字列に含まれるものを探す検索オプションだ。これをうまく使うと、先述した検索結果のソートから生じる問題などでパラメータを見つけ出せるだろう。
「inurl:」という演算子は、使われたプロトコルを検知することもできる。セキュア通信のページ(https:)がインデックス化されているかどうかを調べるのに便利だ。
また、「site:」と通常の検索キーワードを組み合わせて、不完全重複(繰り返し使われているコンテンツの塊など)を見つけることもできる。サイト全体でコンテンツの塊を探すには、探したい部分を引用符でくくったものを追加するだけでいい。
オリジナルなコンテンツの塊を引用符で囲んで検索するやり方は、自分のサイトが盗用されていないかどうかを調べる安上がりで手軽な方法だということも言い添えておくべきだろう。「site:」演算子を外して、長文の、あるいはオリジナルなコンテンツの塊を引用符でくくって検索してみるといい。
VII-3 SEOmozのCampaign Manager
SEOmozのPro会員なら、キャンペーン内の重複コンテンツを見つけ出すツールも利用できる。
Campaign Managerは、ページタイトルの重複に加え、ページの内容自体に含まれる重複コンテンツを検出する。「Campaign Overview」(キャンペーンの概要)の画面から、検出した重複ページを見ることができる。
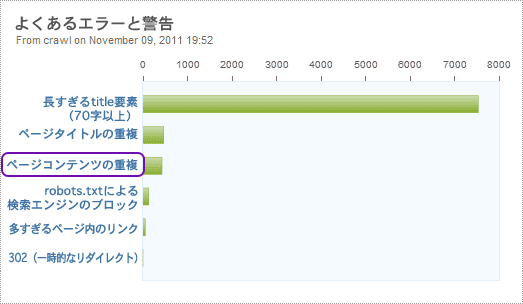
「ページコンテンツの重複」(Duplicate Page Content)というリンクをクリックすると、重複している可能性があるもののリストと、重複コンテンツの数が時間とともにどう変化しているかのグラフまで得られる。
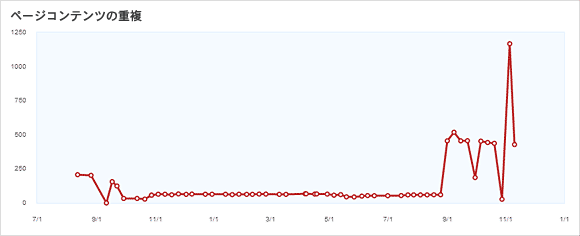
時間ごとの変化を追うグラフは、最近サイトに加えた変更によって重複コンテンツの問題が発生した(あるいは解決した)かどうかを判断する上で、大いに役立つ。
Q&Aでたびたび質問される技術情報を少々。SEOmozのシステムは現在、コンテンツが重複しているかどうかを判断するために、95%というしきい値を使っている。しきい値は(表示される文章ではなく)ソースコードをベースにしているので、実際の重複コンテンツの数は、コードとコンテンツの比率によって変動するかもしれない。
VII-4 自分の頭を使う
最後に、自分の頭を使うことを覚えておくのが重要だ。
重複コンテンツを見つけるには、往々にして探偵のような作業が必要となる。ツールに頼りすぎると、自分が実際に見つけたものとの間にギャップが残る可能性がある。
1つの重要なステップは、自分のサイトを体系的に見て回り、重複コンテンツが作られている場所を見つけることだ。たとえば、サイト内検索はソートやフィルタに対応しているだろうか? そうしたソートやフィルタは、URLのパラメータに変換されクロールされる状態になっているだろうか? もしそうなら、「site:」コマンドを使ってさらに深く掘り下げるといい。
僕の経験では、自分の探偵スキルを活用してほんの一握りの問題箇所が見つかれば、それが数千もの重複ページの発見につながることだってある。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




