AI時代のコンテンツマーケティング手法は「盗むに値するコンテンツを作る」だ(前編)
人工知能(AI)や大規模言語モデル(LLM)の利用増加に伴い、コンテンツの作成はより複雑になっているように見える。SEO担当者はどう動けばいいのだろうか?
2024年12月2日 7:00
今回のホワイトボード・フライデーでは、
- 検索がどのように変化してきたか
- 私たちはマーケターとしてその変化にどう対応すれば質の高いコンテンツを生み出せるか
について、ロス・シモンズ氏が解説する。人工知能(AI)や大規模言語モデル(LLM)の利用増加に伴い、コンテンツの作成はより複雑になっているように見えるかもしれない。しかし、コンテンツ作りの基盤は僕たちが日々利用している基本原理のまま変わっていない。
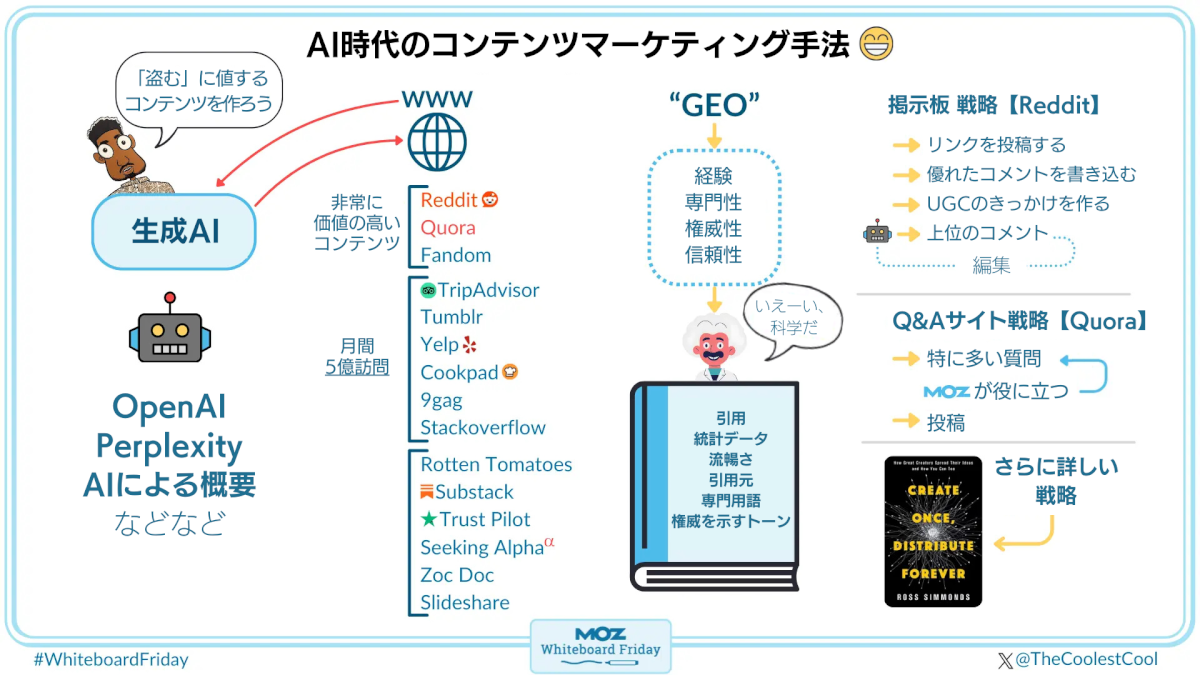
Mozファンのみんな、こんにちは。こうしてホワイトボード・フライデーにまた出られて、とてもうれしい。今回のセッションでは、
- AI
- コンテンツ
- SEO
- GEO(生成エンジン最適化)
などなどの、すばらしい世界を深く掘り下げてみたい。
さあ、心して見てほしい。僕は、これまでのキャリアで学んできたことのほぼすべてをこの1本の動画で紹介するつもりだ。これを君のビジネスに活用することで、AIというすばらしいロボットが登場するまで実質的に不可能だった機会を引き出せるようになることを願っている。では早速始めよう。
盗むに値するコンテンツを作成する

この新しいコンテンツの時代、新しい検索の時代を生き抜くために、まず僕たち全員が認識すべきことがある。それは、検索マーケターとして、僕たちは人類全体に大きな変化が起こっていることを理解する必要があるということだ。人々はもはやグーグルで検索するだけでなく、BingやAsk Jeevesなど、何年も前から検索をめぐって果敢に闘ってきた他のあらゆる検索エンジンにクエリを投げかけるようになった。しかし、検索は今やさらに断片化している。
検索はもう、グーグルで行うだけのものではない。検索は今やTikTokでも行われているし、Redditでも、Quoraでも、Instagramでも、Facebookでも、Metaのあらゆるサービス、WhatsAppでも行われている。検索は進化しており、それを支えているのが大規模言語モデル(LLM)だ。LLMとは何か? 基本的には、ChatGPTのようなAIボットからユーザーが回答を得られるようにするための一連のデータの背後にある技術のことだ。みんなに理解してほしいのは、次のことだ:
OpenAIのChatGPTにアクセスして質問したときに返ってくるコンテンツにどのような影響を与えられるか
ビジネスプロフェッショナルとして、クリエイター、マーケター、起業家として欲しい回答を得るために、どのような影響を与えられるか
では、どうすればいいのだろうか。どうすれば、OpenAI、Perplexity、グーグルの「AIによる概要」に、君が望むストーリーを返してもらえるだろうか。
まず理解すべきは、重要なのはもはやブログ記事ではないということだ。ランディングページでもないし、用語集やハウツー記事を作ればいいわけでもない。最初に理解する必要があるのは「大規模言語モデルのエンジンの基盤となっているのは、何十年も前からインターネット上で作成されてきたコンテンツである」という事実だ。
そして、これらのコンテンツを作成したのは、すべて君のような人たちだ。おめでとう、よくやった。君たちは盗むに値する多くのコンテンツを提供し、そして実際、盗まれた。検索エンジンはコンテンツを盗み、自社のシステムに取り込んだ。君が望むか望まないかに関係なく、検索エンジンはコンテンツを使って質問への回答を提供している。それらの回答にバイアスがかかっているかどうかは別として、とにかく提供している。そういうことだ。
確かに、僕たちは苦情を言ったり、動揺したり、腹を立てたりすることもできるが、世界は回り続ける。君の場合はどうか知らないが、僕は世界が回り続ける間も収入を得たいので、次にビジネスの側面について詳しく見ていこう。
コンテンツが盗まれている場所にコンテンツを埋め込む
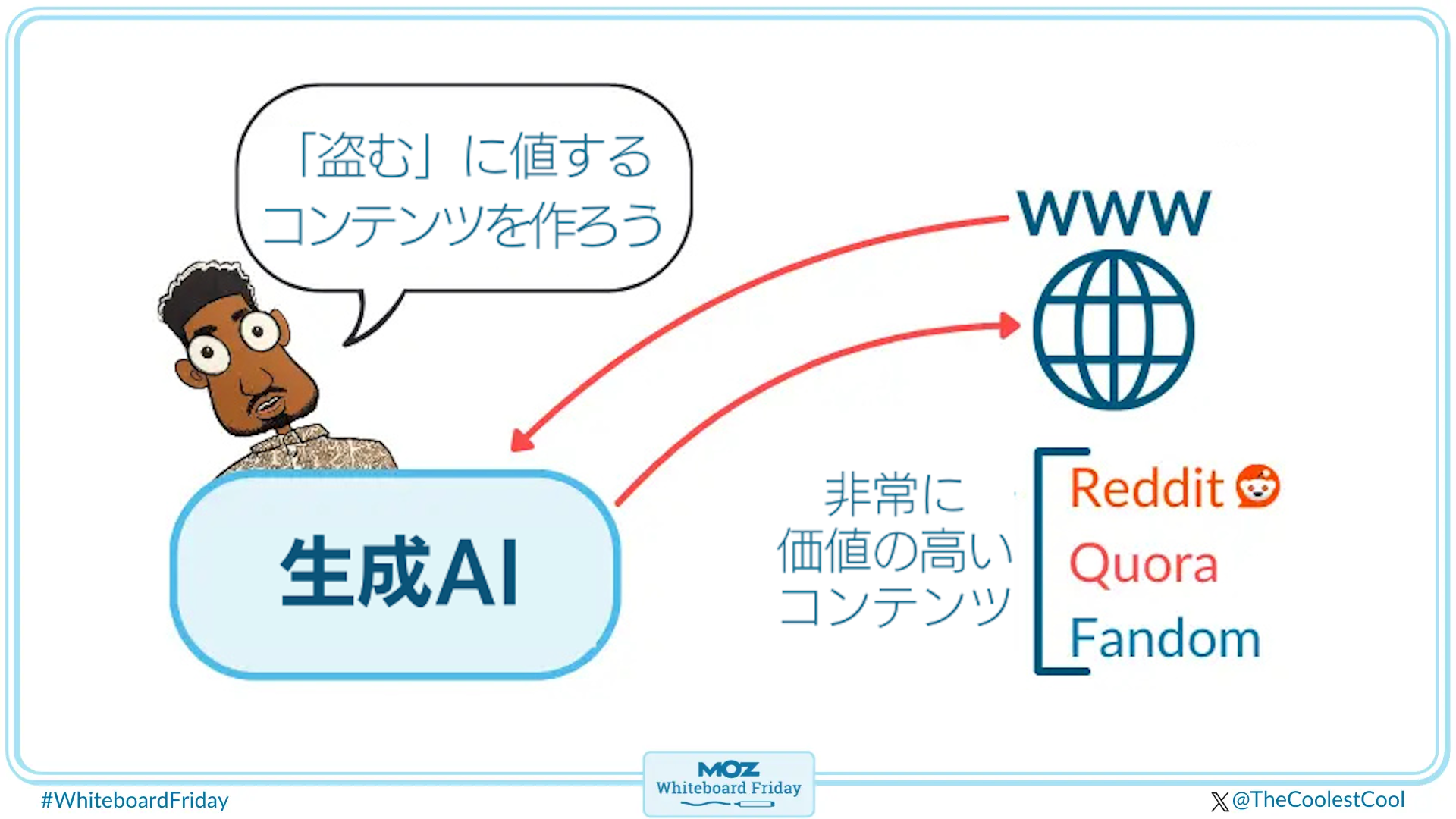
いずれにせよ、コンテンツは盗まれている。それなら、勝手に盗ませておこう。
では、彼らがユーザーの質問に対応するためにコンテンツを盗んでいるという事実に対しては、どのように介入できるだろうか。それには、情報が盗み取られている場所に行かなければならない――そのコンテンツがスクレイピングされている場所だ。こう言うと、何か強盗のように聞こえることはわかっているが、それはすでに行われているのだ。
では、どうすればいいのだろうか。あらかじめ、自分のユーザーがしそうな質問に答えられるだけの十分なストーリーやコンテンツを事前に作成し、スクレイピングされる場所に仕込んでおく必要がある。そうした準備は、次のようなタイミングですでに完了してなければいけない:
- アップデートが実施されるとき
- コンテンツが実際にスクレイピングされるとき
- 各エンジンがRedditやQuoraとの提携を発表するとき
そうしておくことで、ユーザーが実際にPerplexityやOpenAI、グーグルにその質問をした時点で、君の回答がLLMを通じて提供されることになる。君がユーザーに対してグーグルに質問してほしいと思っていた質問とその回答を通じて、ユーザーは君のウェブサイトにアクセスし、君が作成したブログ記事を読んでくれるといった具合だ。
コンテンツをさまざまな場所にばらまく

それを実現するにはどうすればいいだろうか。コンテンツをさまざまな場所にばらまこう。コンテンツに対してこんな風に考えていないだろうか?
ブログ記事を作って公開する。それが大切。
そんな風に考えるのは、もうやめにしよう。記事を公開したからといって浮かれてはいけない。仕事が始まるのはそこからだ。なぜなら次には、LLMがこの質問やこのクエリ、この問題について役立つ情報を得るには、他にどこへ向かうだろうかと、考える必要があるからだ。
ビジネスコンテンツについて考えるなら、Seeking Alphaのようなところに行き着くかもしれない。これは、金融関連企業の幹部や、株式や金融取引などについて学ぼうとしている人を対象としたウェブサイトだ。毎日数十万人がアクセスしている。ここで君に今できることは、これまで独自のサイトで公開していたかもしれない記事を、このサイトに直接公開して、ここで共有してみることだ。
前出の図で挙げたのは、ユーザー生成コンテンツやブランド作成コンテンツを制作したり、着想を得たりできるサイトやプラットフォームの一覧だ。これらのコンテンツは最終的にはLLMに取り込まれていく。現時点でここに挙げたサイトがすべてLLMに取り込まれているのかといえば、それはまだだ。しかし、1つ予測するとしたら、今後2年の間に、LLMはこれらのサイトで独自の情報を得てシステムに取り込んでいくだろう ―― そうすることで、より質の高い回答をユーザーに提供できるようになっていくのだ。
したがって、グーグルが傍観し、これらのサイトにユーザーを送り込んでいる間に、これらのサイトではLLMが学習を重ねることになる。LLMは、トリップアドバイザーのようなサイトとの取引を確保しようとしている。たとえば、ChatGPTにアクセスして、こんな風に質問したとする:
1か月ローマに行く予定です。他に世界のどこに行ったらいいですか?
ChatGPTは、「トリップアドバイザーのコンテンツや掲示板の書き込みから得た情報」に基づいてこうした質問に答えてくれるようになる。現時点で、OpenAIにはそれができない。なぜなら、OpenAIはライセンス契約を結んでいないからだ。そのため、今後結ぶようになっていくだろうと思う。
将来成功するために、今何ができるか? コンテンツのばらまきはすでに始めているだろう。すでに多くの価値あるコンテンツを作成しているだろうし、それが無駄だったとは思ってほしくない。そうしたコンテンツに盗まれるほどの価値があるなら、公開する価値もあることを認識してほしい。宣伝する価値があり、拡散する価値があり、取り上げる価値があり、Reddit、Quora、Yelp、クックパッドで共有する価値があるコンテンツだ。9GAGは避けるほうがいいかもしれないが、それはまったく別の問題だ。Stack Overflowでもいい。
オーディエンスがいる場所に行く

オーディエンスがいる場所、自分のユーザーがいる場所を探して、そのコンテンツを見てみよう。ここに挙げている、
- Reddit(大規模掲示板)
- Quora(Q&Aサイト)
- Fandom(Wikiサイト)
といったサイトには毎月、文字通り数十億件のアクセスがある。これらのサイト、特にRedditとQuoraはOpenAIと提携しているので、僕ならこうしたサイトを使う機会が多くなるだろう(なお、グーグルとも提携している)。
さまざまな事情はあるが、とにかく僕ならここから始める。だが、もしリソースと時間があるなら、よりニッチな下の方のチャネルに表示されるようにするにはどうすればいいかを考えてみよう。Rotten Tomatoesに表示されるようにするにはどうすればいいか、Substackに表示されるようにするにはどうすればいいか、といった具合だ。Substackは基本的に、クリエイターが自分やオーディエンスにとって興味深い特定のトピックについて、ニュースレターのコンテンツや長文のコンテンツを作成できるようにするためのサイトだ。
こうしたコンテンツが定期的に公開され、そこに影響を与えられるとしたら、LLMは今度は何について学習することになるだろうか。それは、君が影響を与えたコンテンツだ。盗むに値するコンテンツを作成することでコンテンツに影響を与え、古いコンテンツをシステムに送り込めば、成果が得られる。
この記事は、前後編の2回に分けてお届けする。後編となる次回は、生成エンジン最適化(GEO)について考え、掲示板やQ&Aサイトを使って「コンテンツを盗みやすくする」戦術について説明する。→後編を読む
- この記事のキーワード
関連記事
GEO/生成エンジン最適化とは? LLMが「盗みやすい」ようにコンテンツをばらまくべし(後編)
2024年12月9日 7:00
ChatGPTなどの生成AIでSEOのコンテンツ制作はどう進化するのか? 今までのワークフローを振り返る(前編)
2023年6月26日 7:00
Webサイト外でもできるSEO施策とは ―― マーケティングエコシステムがSEOに与える影響
2025年1月6日 7:00
AI検索時代の2026年を勝ち抜くサイトの条件とは? SEO専門家リリー・レイ氏が13のQ&Aで指導(前編)
4月6日 7:05
AIでクリックは減った? いま狙うべき「質の高いコンテンツ」とは? 今すぐ学ぶべき事柄は? 10個のQ&Aで理解するAI+SEO【2026年版】
5月11日 7:05
「ChatGPT」「検索依存の低減」「CTR」「未来の検索」 ~将来のSEOに備える17のヒント(後編)
2025年3月10日 7:00
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「Navigating Content Marketing Amidst the Rise of AI — Whiteboard Friday」 by Ross Simmonds (2024/09/27)
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




