ビッグデータvsグッドデータ: リンク分析ツール、どれが優秀か比較してみた(後編)
ビッグデータが良いとは限らない。「グッドデータ」という観点も必要なのではないか
2015年8月31日 7:00
MozのOpen Site Explorer、Majestic、Ahrefs、SEMrushについて、「どのリンクデータが良いか」を検証するこの記事は、前後編の2回に分けてお届けしている。前回の分析では、インデックスの大きさと相似性が反比例するという、一見不思議な結果が得られた。今回は、その意味を考察していこう。→まず前編を読んでおく
この結果は何を意味しているのか
ウェブ上のコンテンツすべてをクロールすることは現実的に不可能なのだから、リンクインデックスを作成しようとする企業は、どのようなページをどのようにクロールしていくかのルール(優先順位付け戦略)を決めることになる。1回クロールして数百万のリンクを検出したら、どのリンクを次にクロールするか優先順位を決める必要があるのだ。
グーグルにはグーグルのクロール優先順位があり、Moz、Majestic、Ahrefs、SEMrushにも各自の優先順位がある。優先順位を付ける対象は、以下のようにさまざまに異なるかもしれない。
新規リンクの有無を優先 ―― 大規模なインデックスを構築したいなら、これまで新しいリンクを提供してくれているサイトのページを優先的にクロールすればよい。
コンテンツの独自性を優先 ―― 検索エンジンを構築したいなら、過去に見たことがあるページとは異なるページの検出を優先したい。過去に独自のデータを提供していたドメイン名や重複コンテンツがほとんどなかったドメイン名をクロールするのもいい。
コンテンツの新鮮さを優先 ―― 検索エンジンを最新の状態に保っておきたいなら、頻繁に変更されるページのクロールを優先するのがいいだろう。
コンテンツの価値を優先 ―― そのページに張られたリンクの数に基づいて最も重要なURLからクロールする。
クロールの優先順位付けを行う場合は、おそらく、これらの戦略のいくつかを組み合わせることになるだろうが、グーグルとまったく同じようなものを設計することは、現実的には難しい。
ここで、ウェブのクロールの代わりに、木登りを考えてみよう。木に登るためにはその戦略を考えなければならない。
あなたと友人2人は、木登りをすることにした。それぞれ、次のようなルールで上る枝を決めるとする。
- あなたは、枝分かれしている地点に来るたびに、見えている範囲で最も長い枝に登る
- 友人は、最初にたどり着いた新しい枝に登る。枝の長さは考慮しない。
- もう1人の友人も、最初にたどり着いた新しい枝に登る。ただし、その枝からさらに別の枝が出ている場合のみとする。
木登りの戦略は違っても、3人全員が同じ枝を1本目として選び、2本目も同じ枝を選ぶことになる。早い段階では、選択肢が限られるのだ。
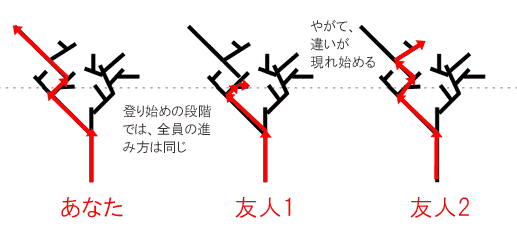
だが、木登りが進むにつれて、それぞれの選択が異なる結果を生むことになる。グーグル、Moz、Majestic、Ahrefs、SEMrushといったウェブをクロールする企業もまったく同じだ。クロールの規模が大きくなるほど、クロールの優先順位付けが大きな相違を生み出す。
これは欠陥だというわけではない。本来こういうものなのだ。
だからといって、まったくお手上げというわけでもない。インデックスの大きさと相違の度合いの関連性がわかれば、クロールの優先順位付けがグーグルにどの程度近づいているかをある程度推測できるようになる。
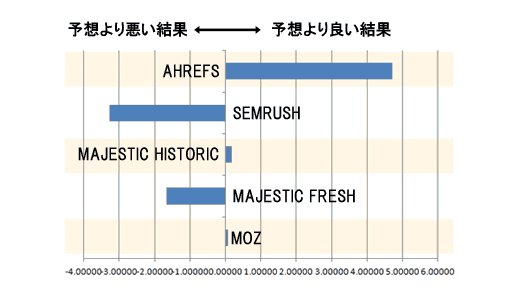
ただし、結論を出す際には注意が必要だ。われわれが扱っているデータポイントはわずかしかないため、この部分の分析結果に確信を持つことはとても難しい。特に、インデックスの大きさの割にMajesticの関連性が高いことは、グーグルが古いデータを保持し続けている(これ自体が重要な発見なのかもしれない)のでない限り奇妙に思える。
今の段階では、われわれにはこのレベルの結論を下すことはできないと考えた方が良さそうだ。
ではどうするか
ドメイン名またはURLのリストがあり、その相対的価値を知りたい場合、プロセスは次のようになるだろう。
Open Site Explorerで、すべてのURLがインデックス内に存在するかどうかを調べる。存在するなら、その指標は、グーグルのリンクグラフと比率が一致している可能性が高い。
インデックス内でリンクがまったく発生していない場合、PageRankのような単一の指標が必要なだけなら、Ahrefsに切り替えて、Ahrefsの順位付けを使用する。
どのリンクもAhrefsのインデックスにない場合、または信頼性に関するものを必要としている場合は、Majestic Freshに切り替える。
最後に、(桁違いに)大きな規模を求めるなら、Majestic Historicを使用する。
指標の正確性が低いインデックスほど、チェックしたいURLがそのインデックスにすべて含まれる可能性が高くなることは、指摘しておく必要がある。Majesticのデータの規模を考えれば、そのデータを無視することはできない。他と比べて、データから値が返されない可能性は少ないと思われるからだ。
要するにここでもまた、できる限り多くのソースからデータを収集するのが理にかなっているということが言えよう。
最も相似性の高いデータを得るならMozが欠かせないし、最も規模が大きいデータがほしいならMajesticが欠かせない。また、相似性も規模もほどほどのデータが必要なら、Ahrefsだろう。
SEMrushについてはどうだろうか。進歩しつつはあるものの、この記事で取り上げたケースに役立つような相対的統計データは公開していない。ただし、その将来性の高さがうかがわれるインデックスを見ると、近いうちにもっと期待できるようになるだろう。
リンクグラフ業界への提言
最近耳にするのはビッグデータ(規模の大きいデータセット)の話ばかりで、グッドデータ(質の高いデータセット)について聞くことはほとんどない。
Moz、Majestic、Ahrefs、SEMrushなどは、グーグルを真似ることに関心があるようだが、データの規模を大きくする誘惑に負けることなく、データの質を高め、よりグーグルのデータに近づけようとするサービスの登場を期待したい。そうなれば、さまざまなクロール戦略をテストして、Google Search Consoleで公開されているデータにより近い結果が得られるかどうかを確認できる。
最もグーグルに近いデータを持つことが、勝ち取る価値のある栄冠だということは間違いない。
謝辞
データの入手に協力してくれたAngularのダイアナ・カーター氏、それに統計分析に協力してくれたアンドリュー・クロン氏に感謝したい。また、Moz、Majestic、Ahrefs、SEMrushの担当者には、インデックスに関する質問に回答をいただいたことを感謝する。
- この記事のキーワード
関連記事
SEO向けリンク分析ツール、どれが優秀か比較してみた(前編)
2015年8月24日 7:00
グーグルのMFI(モバイルファーストインデックス)はWebのリンク構造に激変をもたらす(後編)
2018年5月28日 7:00
「SEOにテクニカルな要素は必要ない」の嘘――なぜ今、SEOに技術的な理解が必要なのか(全6回の1)
2017年1月16日 7:00
SEO担当者が知っておきたいJavaScriptの基本 ―― グーグルにサイトを正しく理解させるために(後編)
2017年9月25日 7:00
Webサイトのドメイン名移転: SEOmozが経験した作業フローと注意点
2013年11月18日 9:00
チームで目標を達成するSEO戦略の概要と10のステップ ~無料のテンプレートも紹介~(前編)
2023年6月12日 7:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




