検索エンジン視点のWebやリンクの統計データを紹介しよう(前編)
まずは現在のWWWのページやドメイン名、そしてリンクの統計データを紹介しよう。
2009年5月25日 9:00
先週、僕はSMX Munichで「WWW(ワールド・ワイド・ウェブ)のインデックス作成から得た教訓」と題した基調講演を行った。講演では、僕らがウェブインデックス作成で得た豊富なデータを発表したほか、検索エンジンがやっている多くの処理(クロール、インデックス化、リンクグラフの作成、重複除外、正規化など)を自分たちでやってみて得た経験に基づき、SEOに役立つヒントをいくつか紹介した。
今回の記事では、まず、Linkscapeのインデックスを、3月下旬から4月上旬までのクロールデータを用いて更新したことについてお知らせし(後で紹介するデータポイントは、このクロールデータを基に計算された)、次に、基調講演で披露した図表、グラフ、そしてSEOに役立つヒントをご紹介したいと思う。
Linkscapeのインデックス
まずは、Linkscapeのインデックスについて基本的なことを述べておこう。
何をクロールし、インデックス化するかについては、主な検索エンジンに倣っている。主要エンジンでインデックス作成に従事している多くの人から聞いた話では、クロールする数百億~数千億ページのうち、「メインインデックスに残す価値があるのは50億ないし100億ページ程度」に過ぎないという。
Linkscapeはクローラー型インデックスで、シードセットを利用し、リンクを辿ってクロール範囲を広げることで新規URLを見つけ出している。
インデックスは今のところ外部リンクを持つページに偏る傾向にある。つまり、主要検索エンジンほど深い階層までクロールしてないってことだけど、僕らもかなり広範囲にクロールしようと試みてはいる(相互リンクの豊富なページやユニークドメインをできるだけ多く見つけられるように)。
現在採用しているクローラーとデータソースはすべてrobots.txtによる指示を尊重する。
ウェブの構造
クロールを行っていると、よく知られたウェブの構成要素がいくつか見えてくる。
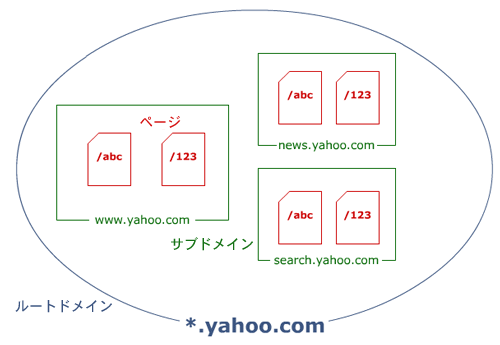
Linkscapeでは、多くの学術的研究で(それと、まず間違いなく主要検索エンジンでも)行われているように、上に挙げた3つの構成要素(ページ、サブドメイン、ルートドメイン)についてのデータを収集/蓄積している。リンクとコンテンツに関する指標は、クロールパラメータやクエリ非依存型の順位決定要素とともに、3つの構成要素についてそれぞれ蓄積している。
またLinkscapeからは、下のようなウェブのリンク構造も見えてくる。IR(情報検索)を学ぶ学生にはお馴染みのはずだ。
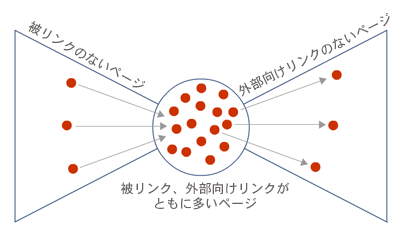
以前から指摘されているとおり、ウェブのリンク構造はどこか蝶ネクタイに似ている。中央の部分には、他ページとのリンクが豊富で結びつきの強いページがたくさんあり、その両翼に被リンクや外部向けリンクの少ないページが存在する、という形だ。Linkscapeは中央部にあるページと被リンクしかない(外部向けリンクがない、またはほとんどない)ページについては割合うまく拾えているけれど、被リンクのないページについては苦戦している(こういうページは発見しにくく、またインデックスに入れておく価値がないことも多いからだ)。
インデックスの統計
これから紹介するデータポイントは、とてもすばらしいもので、その多くをここで初公開できることを嬉しく思う。Linkscapeはヤフーやグーグルほど広い範囲をクロールしてはいないけど、それでも標本数からいえば、統計的な標本集団というよりは、ずっと実際のウェブの姿に近いものだ。Linkscapeの最新インデックスに含まれているデータは次の通りだ。
- ページ数:44,410,893,857(440億)
- サブドメイン数:230,211,915(2億3000万)
- ルートドメイン数:54,712,427(5400万)
- リンク数:474,779,069,489(4740億)
このインデックスから、次のようなデータが導き出される。

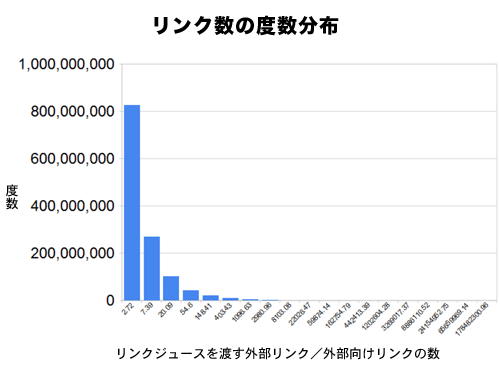
リンク数の度数分布図は「リンクジュースを渡す外部向けリンク」のみを集計対象としていて、同じサブドメイン名からのサイト内リンクや、メタタグ(meta要素)で「nofollow」を指定しているページにあるリンク、「nofollow」属性付きのリンクは除外してある。
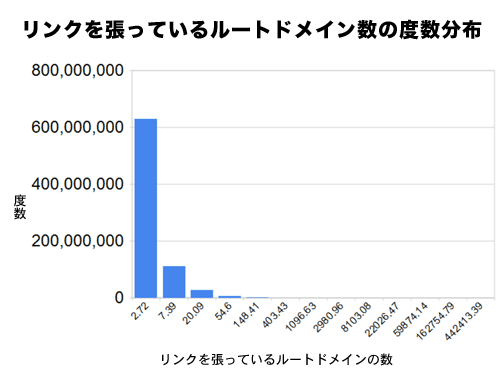
リンクを張っているルートドメインの度数分布図は、異なるルートドメインからリンクを張られているページやサイトのみを集計対象としている。たとえば、「www.seomoz.org」が「searchengineland.com」上にあるいろんなページから2000本のリンクが張られていたとしても、リンクを張っている「searchengineland.com」というルートドメインを1つと数える。同様に、「about.com」からのリンクは、「about.com」が持っている多数のサブドメインからリンクを張られていたとしても、すべて「about.com」という「一意のルートドメイン」から受け取ったものとして、1つとしか数えない。
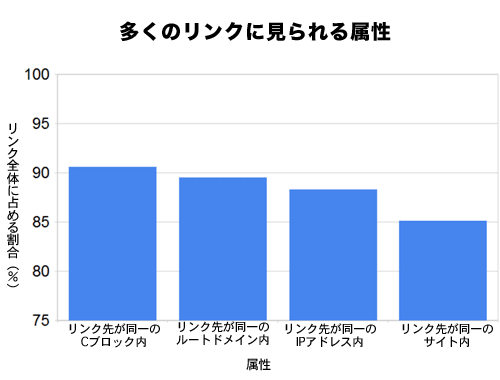
意外なことではないけれど、ウェブ上にあるリンクの大半は内輪で取り交わされる傾向にあり、リンク先は、同一のサイト内(同じサブドメイン内のページにリンクしている)か、同一のIPアドレス内(そこで同じサイトオーナーが複数のサイトをホスティングしている)、同一のルートドメイン内、あるいは、同じクラスCのIPアドレスブロック内にある。Linkscapeでこのような関係を見出せるのだから、当然、検索エンジンには簡単にわかるはずだ。このようなリンクからは、異なるルートドメインやIPアドレス、Cブロックなどから来る外部リンクと同等の価値はまず得られない。
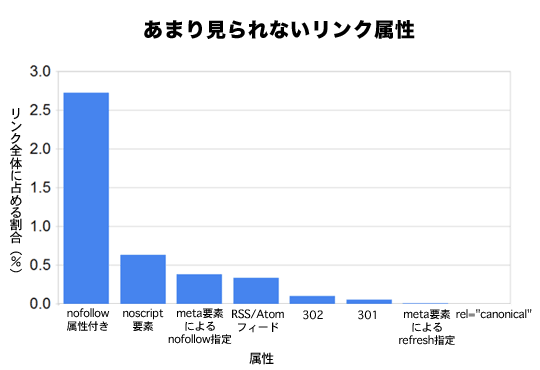
上のグラフから、いくつか興味深いデータポイントが得られる。
ウェブ上にある全リンクの2.7%には「nofollow」属性が付いている。
ウェブ上にある全リンクの73%はサイト内リンクだ(つまり、nofollowは実際にはスパム防止ツールとしてより、PageRankスカルプティングのツールとして人気があるということだ)。
4750億件のリンクのうち30億件(0.6%未満)はnoscript要素内で使われていた。検索エンジンはこのような使い方を推奨せず、スパム的手法の1つと見なしているが、僕らは、実際にはその多くが適正な使い方をされていると考えており、おそらくは(コンテンツの発見に役立つため)リンクとしてカウントされているはずだ。
165,638,731件(0.034%)のリンクはページ上に表示されない(CSSなどの手法で隠されている)。これについても、その数を考えると、すべてがスパムで検索エンジンに無視されているのかどうか疑問だ。
これはlink rel="canonical"によるURL正規化タグに対応した初めてのインデックスで、今のところこのパラメータを採用しているページは1600万余りしか見つかっていない。ウェブ全体から見ればほんのわずかだが、これが今後の数か月間にどれくらいの支持を集めるか注目していきたい。
この記事は前後編の2回に分けてお届けする。後編では、Linkscape独自の指標について説明し、さまざまな指標と検索順位との相関関係について考察する。→後編を読む
- この記事のキーワード
関連記事
「SEOの意外な裏技」その10:robots.txtでリンクジュースの受け渡しをうっかりブロックしないために
2009年6月12日 9:00
ロボット排除プロトコル(REP)とは?――メタタグやrobots.txtの基礎
2008年2月27日 9:00
検索エンジン視点のWebやリンクの統計データを紹介しよう(後編+SEO的分析)
2009年5月26日 9:00
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
ロボットのアクセスやインデックスを制御するテクニック: 基本のおさらい(前編)
2011年10月3日 9:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




