中国の北京で4月22日、ウェブ上の有害情報研究(Adversarial Information Retrieval on the Web)に関するカンファレンス「AIRWeb 2008」が開催された。このカンファレンスに関するガルシア博士の記事を見た後で、僕は各論文を読み、そのうちいくつかについてハイレベルな要約を書くつもりだった。
しかし、AIRWeb 2008カンファレンスにおいて、ウェブスパムのコンテストが開催されていたのを知るや、僕の関心は別の方向へと向かっていった。ガルシア博士の怒りを買うのを覚悟の上で(以前に僕は彼を怒らせてしまったことがある)、僕は面白半分に、独自のスパム検出アルゴリズムを開発した。そしたら、そのアルゴリズムが驚くほど良好に機能したんだよ!
僕は自分のプロジェクトの方針を変え、ドメイン名がスパム的かどうかをチェックするツールをテーマにした。だけどこのツールについては、いかなる約束もできない。もし君が上質のドメイン名を欲しいと思っているのなら、あるいは少なくとも、明らかにスパム的でないものが欲しいなら、気の利いたツールになるかもしれない。

更新情報:以前のバージョンにはいくつかバグがあったので、それらを修正した(だが僕がまだ把握していない他のバグに関しては未修正)。したがって、現在は(少なくとも若干は)良くなっているはず!
皆さんは、おそらくスパム検出の基本的な考えについて理解していると思う。
- 検索エンジン(およびウェブサーファー)は、スパムページが嫌いだ。
- 極上のスパム検出モデルを持つ博士号タイプの人材と、巨大なデータセンターを持つ検索エンジンの支援、そして先端的な研究への資金供与、これらがあれば、僕が作ったツールよりもかなり優れたものができる。
これらのことを確かめるために、「真陽性率(true positive rate)」と「偽陽性率(false positive rate)」に注目してみるとおもしろい。完璧なアルゴリズムは、真陽性率が100%(すなわち1.0)(すべてのスパムをスパムとして検出)で、偽陽性率が0%(非スパムページがスパムとして検出されることがゼロ)だ。しかし、カロリーがゼロで、しかも美味しいチョコレートなどというものがないように(そんなことはないと言ってくれ!)、完璧なアルゴリズムもめったに存在しない。したがって、トレードオフというものに直面することになる。
すべてをスパムではないと判定すれば、偽陽性率はゼロになる。これは下のグラフの原点(x=0かつy=0)にあたる。また一方で、すべてをスパムと判別するなら、検索結果にスパムページが顔を出すことはなくなる。しかし当然ながら、(すべてスパムと判断したため)どんな検索を行おうが何もページが出てこないのだから、検索業界の人間は全員新たな職を探す羽目になるだろう。僕の場合、妻のロックバンドでツアーの裏方でもやるのかな。
下のグラフで、このトレードオフの関係を説明してみよう。これは、AIRWeb 2008カンファレンスのコンテスト結果に僕の素敵なアルゴリズムも加えて、新たにプロットし直したものだ。直線「y=x」は、スパム判定を無作為に行った場合(真陽性率と偽陽性率が等しい)で、これが基準となる(グラフがこの直線よりも下にあるスパム検知ツールなんて役立たずだ!)。
AIRWeb 2008カンファレンスにおける実際の結果(PDF)。
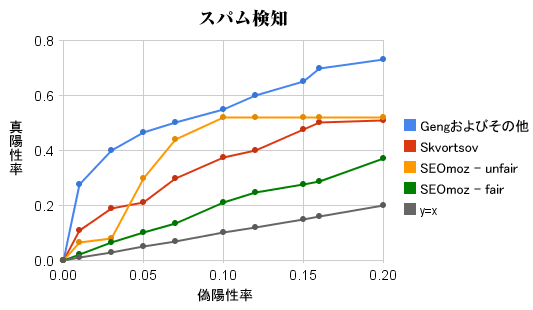
このグラフを見れば、僕のアルゴリズムが優秀なのは一目瞭然だ。
「SEOmoz - fair」のラインは後で触れるので、ここではひとまず置いておこう。
「SEOmoz - unfair」を見ればわかる通り、偽陽性率が10%(0.10)のところで、僕のツールは首尾よくスパムページの50%(真陽性率0.5)以上をスパムと判定できており、カンファレンスで一番成績の悪かったアルゴリズム(Skvortsov:同じ偽陽性率のときに真陽性率39%)よりも優れているばかりか、最高の成績を示したアルゴリズム(Gengおよびその他:同じ偽陽性率の時に真陽性率55%)に迫る成績を示している。
何もかもすばらしい我らがインターン、ダニー・ドーバーと開発チームの秘密兵器ベン・ヘンドリクソンの助力だけで、わずか2日間で開発した僕のアルゴリズムSpamDilettante®(特許申請中!)は、有害情報研究において最も優秀で頭脳明晰な複数の研究者たちを負かしたんだ。
でも実は……fair版の解説
さて、グラフというものは嘘つきだ。そして僕も嘘をつく。一体どういうことなのか説明しよう。
まず嘘のない部分はどこかというと、僕のアルゴリズムは本当にスパムを判別する。それと、リンクグラフを使用したり、複雑なカスタムウェブ機能を採用したり、演算処理に膨大な時間を費やしたりすることなく、本当にわずか2日間でこのアルゴリズムを開発した。
しかしこのアルゴリズムには、これから説明する重大な注意点がいくつかあって、それらはずっと成績の悪い「SEOmoz - fair」のラインが示している。
僕は、Randが書いた大人気のブログ記事には載っていないスパム判別指標から着手した。しかし、Randの記事には優れた項目が実にたくさん掲載されている。僕が実際に上手く計算に織り込めなかった項目も多い。たとえば以下のようなものだ。
- コンテンツに占める広告の割合が高い
- ユニークコンテンツの量が少ない
- 直接的なビジターがほとんどいない
- 信頼の置ける情報源由来のリンクを得られない傾向が強い
- グーグル、ヤフー、MSNのローカル情報サービスに登録できそうにない
- 非常に信頼性の高いウェブサイトと、多くのウェブページを間に介してリンクしている
- ユーザーエージェントまたはIPアドレスに基づくクローキングをしていることが多い
例を挙げればきりがない。こうした項目は、検索エンジンの支援を受けた一部の研究者たちですら把握できるものではない。だから僕は、こういうのを無視したんだ。結局のところ、サイトにトラフィックがあるのか、あるいはクローキングが行われているのかを知ることは、どの程度重要なのだろうか? 優秀な研究者たちも気にしないんじゃはないかな?
ただしドメイン名のみから、以下のような事項はアルゴリズム化することができた。
- 長いドメイン名
- .info、.cc、.usなどの、簡単に取得できるTLD
- ドメイン名に、商業価値の高い、一般的なスパムキーワードを使用している
- ドメイン名に複数のハイフンを含む傾向が強い
- .comあるいは.orgなどのTLDでないことが多い
- .mil、.eduまたは.govなどのTLDであることはまずない
したがって、これらの要素を基に直線回帰(非常に単純な統計モデル)を用いて分析すれば、かなりすばらしい結果が短期間で得られるだろうと僕は考えた。そこで、ダニーをはじめとするSEOmozのメンバーを駆り集め、ある程度無作為に選んだ(しかし有効な)ドメイン名を比較的短いリストにまとめてもらった。
ダニーはあらゆる種類の怪しいページを閲覧するのに、とある日の午後を費やした。ダニーがこんなページを見ているのもSEOmozの仕事としてなんだから、指導教授(と家族)には安心していただきたい。最終的に僕らは、収集したドメイン名のうちおよそ3分の1をスパム、そして3分の1を非スパムと判定し、残りの3分の1については「不明」(主に、すばらしいコンテンツを含んでいそうな英語以外のサイト)とした。
みんなの熱心な助けを得て、僕は上記の要素を抽出するスクリプトを(Pythonコード数行で)作成した。僕はスパムまたは非スパムと判定した全体の3分の2のデータについて、その80%を「訓練用セット」、残り20%を「テストセット」に分けた。すべてのデータについて、判定結果がわかっていれば、スパムであるドメイン名とスパムでないドメイン名をコード内に組み込むことができるので、この作業は重要だ。この手を使えば、成功は君のものだ(「完璧な」アルゴリズム云々の話を覚えているかな?)。
とにかく、僕はこの80%のデータで直線回帰分析を行い、独自の分類アルゴリズムをものにしたんだ。
性能を測るために、この分類アルゴリズムを残りの20%にあたるテストセットに適用してみた。このアルゴリズムは、基本的に「0.87655」といった数値を結果として返すのだが、この数値はそのドメイン名がスパムである可能性だと考えてもらっていい。上のグラフの曲線を得るために、スパムと判定する基準値(たとえば、可能性が0.7より大きいならスパム、そうでなければ非スパム)をいろいろと変えて試してみた。こうやって偽陽性(スパムでないのにスパムと識別)と偽陰性(スパムなのにスパムでないと識別)のバランスを調整し、上のような曲線となった。
以上のようにして、僕のツールは研究者たちを上回る成績を上げたというわけだ。
オッケー、少しの間現実に戻ろう。先に触れた注意点だ。
- コンテストの紹介(PDF)を見てもらいたいんだが、僕のデータセットは分類がはるかに容易な問題だ(すべてのドメイン名が判定済みで、種別の偏りがほとんどない)。
- レベッカが言っているように、「.infoや.biz、そして.netドメイン名の多くがスパムだというのは、『SEOの常識』の1つに過ぎない」わけで、僕のデータセットには、こうした「格好の標的」が数多く含まれている。ところが、今回のコンテストで使用したのは、すべて.uk(さらにいうなら主に.co.uk)ドメイン名だった。
- 僕のデータセットは非常に小規模で、サンプリングに関しては、おそらくあらゆる種類の問題を抱えていると思われる。僕のツールが出した結果は、おそらく一般化できない。
しかし、これらは推測に過ぎない。僕が実際には大した成果を出していないという仮説を裏付けることはできるだろうか? それこそが、上のグラフの「SEOmoz - fair」ラインだ。僕はコンテストで実際に使用されたデータセット(URLと種別のみ)をダウンロードし、自分の分類アルゴリズムに通してみた。すると、強力だった僕のシステムが、にわかにそれほど優れたものに見えなくなってしまった。
ある教授が各ツールに評点をつけてくれたんだが、それによると、僕のツールの評点は「とても悪い」よりたった1段階上の「悪い」にとどまっているそうだ。コンテストにおいて僕よりも優秀で、最も近い成績だった人の評点は(もちろん「並」を越えて)「良い」で、最高の成績を示したシステムの評点は「とても良い」のクラスだ。
僕が検出ツールを手がけるきっかけとなった元記事でガルシア博士が述べているように、「振り出しに戻ってやり直すとき」なんだな。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




