Webページを表示するために、ブラウザはHTMLを一生懸命読んでいる!?【第5回】
Webページを表示するために、ブラウザとサーバーとパソコンは一体何をしているのでしょうか? 今回はWebページが表示されるまでの仕組みを紹介します!
2019年3月6日 7:00
皆さんは、何かわからないことがあったらスマホで調べよう! と検索しますか?
スマホを持つことが当たり前になった現在では、ブラウザ(パソコンやスマホ上で使う、Webページを見るためのソフト)で検索することが日常になりました。
でも、一体どういう仕組みでWebページが表示されるのでしょうか?
今回は、パソコンでブラウザを立ち上げてWebページを見るときの仕組みについて解説していくことにしましょう。

リクエスト信号は「自己紹介」情報を持って飛んでいく?
ブラウザはサーバーから飛んできたHTMLを読み込んで解釈し、ブラウザの窓に描画しています。
普通のタグで言えば、<b>と書いてあったらその後ろを太字にする。</b>という印が出てくるまで太字を続ける、というのが解釈と表現の基本です。
では、ブラウザがWebページを表示するまでのステップを見ていきましょう。
まず、私たち人間が「このWebページを見たい」と考えたときは、ブラウザのアドレス欄にURLを記入するか、すでにブラウザに表示されたハイパーリンクをクリックするかの大体どちらかです。
(検索エンジンで検索して、という場合は、検索エンジンが検索結果にリンクを入れてくれるので、それをクリックするだけで良いのです)
記入されたURLや、クリックされたハイパーリンクに指定されたhref(エイチレフ)は、ブラウザからパソコンが準備する環境を通ってインターネットの世界に飛び出していきます。
※私がURLとかhrefとか、ややこしい言葉をあまり説明なく使う場合は、この連載の前の回でご説明した言葉なので、そちらもご覧くださいね。 第4回参照
ホワイトハウスのサイトが見たい場合は、
https://www.whitehouse.gov/
というのがリンクの裏にhrefとして記入されています。
アドレス欄に直接記入する場合は、「whitehouse.gov」とドメインを書くだけでちゃんと「https//www」に飛んで行って、一番上階層の「/」を見に行ってくれます。これはブラウザやサーバーが我々のアクションを補助してくれているのですね。
最後の「/」は、サーバー上の最上位階層を意味するものです。多くの場合、ここには「index.html」というトップページを見たい、という指示が略されています。
index.phpやindex.plなど、実際にはHTMLではないプログラムファイルである場合もあります。でも、「/」で見に行けばサーバーが適切なファイルを選んで送り出してくれるので、私たちは拡張子のことなど忘れていられます。素晴らしい仕組みですね。
さて、ブラウザから出たリクエスト信号は、インターネットの世界に出ていきます。DNSというシステムに聞き合わせながらインターネットを進み、目指すサーバーにたどり着きます。

ただ、リクエスト信号は自己紹介もなくいきなり飛んで行ってサーバーに「このデータを出せ!」と要求するわけではありません。HTTPヘッダー、と言われる自己紹介データを持って飛ぶのです。
そこにはこんなことが書かれています。
GET / HTTP/1.1
HTTPのバージョン1.1のルールで、Getという方法で「/」を見たい。
Mozilla/5.0 (iPhone; CPU iPhone OS 12_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0 Mobile/15E148 Safari/604.1
私はiPhoneのSafariというブラウザなんですけど、怪しい者ではありませんので見せてほしいのですが……。
と、なかなか礼儀正しいリクエスト信号君であります。
先頭に「Mozilla」とあるのは、ネットスケープのことです。なぜサファリなのにネットスケープと名乗っているんでしょう?
ブラウザが出始めた1994年ごろにはネットスケープというブラウザが90%以上のシェアを持っていました。ネットスケープはのちにMozilla Firefoxとなりますが、当時からコードネームはMozilla。
当時、怪しいアクセスでサーバーの中を覗きに来るようなリクエストがたくさんありました。だから、「Mozillaと名乗っていないリクエストは全部はじく」 と決めているサーバーが世界中にあったのです。
そのため、Mozillaと名乗らないとサーバーが情報を出してくれなかったので、ちょっと後発のマイクロソフト Internet Explorerでさえ、Mozillaと名乗っています。
そして現在、Safariも、Googleの検索ロボットGooglebotも、Bingbotも、みんなMozillaを名乗っています。全員Mozillaを名乗ったらまったく意味がありませんが、いまだにみんなで「私はMozillaです」と言うしきたりになっています。完全に「ウソ」ですが、まさにウソも方便です。
ちなみにMozillaは「モジラ」と読みます。ゴジラみたいな恐竜のイメージです。昔はかわいい緑の恐竜のイラストがあったのですよ。

正常なら「200 OK」、見当たらないと「404」!
丁寧に自己紹介したリクエスト信号に対して、サーバーは「はいはい、そのファイルならここにありますよ」と、「/」の場所にあるファイル(たいていindex.htmlという名前です)のデータを送り出してくれます。
このとき、サーバーはブラウザへの返事をヘッダーという形でつけておき、データを送り出します。
その返事の書き出しはこうなっています。
OK!と言って送り出してくれるサーバーもなかなか気立ての良いやつであります。この「200」がリクエストに対して正常に対応して終了した、ということを表す記号で、ステータス(状態)コードと呼ばれます。
ステータスコードで「200」の他に覚えておきたいのは
- 404 Not Found リクエストされたURLが見当たらない
- 403 Forbidden そのファイルはアクセスが禁止されている!
- 304 Not Modified 前に見た時から変わっていない
などがあります。
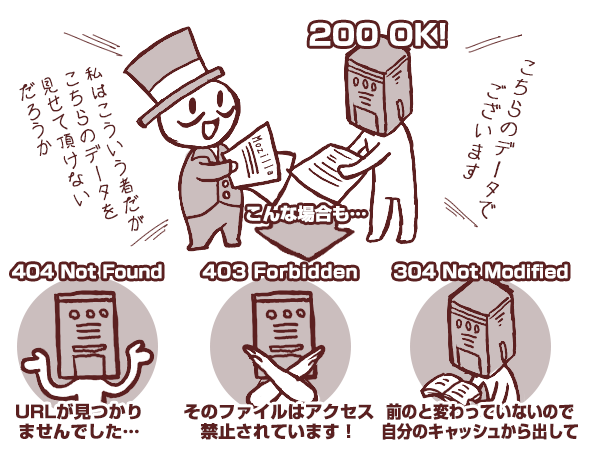
「304」という返事が戻ってきたら、「前にアクセスしたときからページの内容が変わっていないのなら」 とブラウザは自分の覚えているキャッシュから表示を始めます。もう一度サーバーからデータが送られてくるよりも早いので、前に見たことのあるページは素早く表示されるのです。
こうしたブラウザとのやり取りについて、サーバーは全部記録をとっています。この記録のことを「ログ」と言って、これがあったのでアクセス解析という分野が生まれたのですね。
ブラウザとサーバーの無限の会話でページが表示されます!
こうしたやり取りの末にブラウザにデータが飛んできました。ここからブラウザはまずHTMLのヘッダーを読み込みます。
HTMLという文書は便せんのように「ヘッダー」と「ボディ(本文)」からできていて、書式としては
<html>
<head>
</head>
<body>
</body>
</html>
のようになっています。
実際にブラウザの窓に表示されるのは「ボディ」の部分だけで、「ヘッダー」部分はブラウザに大切な指示を与えるために使われます。
だから、HTMLが飛んできたら、まずブラウザは落ち着いてヘッダーを読み込み、それから本文部分の読み込みを始めます。長いHTMLを上から順番に読んでいくので、Webの表示にはまあまあ時間がかかるのですね。
上から順番に読んでいくと、HTMLには描画に必要な別ファイルの指定がいろいろ書かれています。※1CSS(Cascading Style Sheets)や※2JavaScriptのようにレイアウトや動作を決めるファイルもあれば、画像や動画のようにそれ自体を表示しないといけないものもあります。
※1 カスケーディング・スタイル・シート。ウェブページのスタイルを指定するための言語。
※2 Webサイトに動きをつけるプログラミング言語。
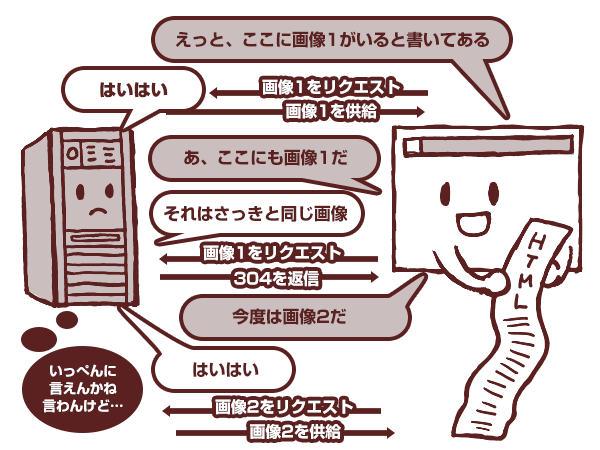
読んでいくうちに「あ、ここに画像の指定が書いてある」と気が付いたブラウザは、サーバーにまたリクエストを送ります。サーバーは「はいはい、その画像はここにありますよ」と送り出します。
何しろブラウザは上から順番に読んでいくので、「また画像があった!」とそのたびにリクエストをサーバーに送ります。
サーバーも「いっぺんに言ってもらえませんか」と文句も言わず、律義に順番にデータを返してくれます。
1997年ごろはWebページがシンプルで、1つのHTMLに画像が平均5点指定されているだけでした。
今ではCSS、JavaScriptが3つずつ、画像が平均47点、その他にGoogleアナリティクスの計測タグ、Webフォント、ソーシャルメディアのガジェットなどなど、無数の関連情報がぶら下がっています。
こうしてブラウザとサーバーの無数の会話の末にようやく1つのページが表示されます。
これらを読み込まなければ表示が完了しないので、ものすごく待たされるケースが発生してしまうのですね。特に、HTMLとは別のサーバーにデータをとりに行くWebサービスには待たされることが多いです。ブラウザの左下の窓枠を見ていると「これを呼び出しています」「待っています」なんてブラウザの愚痴が表示されることがあります。
これは笑い事ではなく、表示が遅いと離脱率が高まります。きれいなサイトをつくったのに、お客さんがみんな帰ってしまうのでは意味がないですよね。回線が早くなったから、と油断せず、できるだけ表示の早いWebにするようにWeb担当者の皆さんは心がけていただければ幸いです。
こうしたリンクファイルについては次回から詳しく解説していきます。
ブラウザの歴史とブラウザ戦争
先日、我が家の屋根裏部屋を片付けていたら、「InfoMosaic」(インフォモザイク)と「Netscape Navigator 1.11」(ネットスケープ・ナビゲーター)という、昔のブラウザソフトが出てきました。
今ではパソコンを買ったら最初から入っていたり、サイトからダウンロードすることが当たり前になりましたが、1995年ごろには、お店でパッケージで買ってくるものだったのです。

まずブラウザの歴史をざっくりと追っていきましょう。最初のブラウザが作られてから数年、1991年に公開された「WorldWideWeb」というブラウザが、私たちが知るブラウザの最初のものと言われています。
1993年に「NCSA Mosaic」(エヌシーエスエー モザイク)、翌年1994年には後継とも言われる「Netscape Navigator」(ネットスケープ ナビゲーター)が作られ、日本にもWebの時代が訪れようとしていました。
まずはネットスケープが独り勝ちで、90%以上のシェアがあると言われるようになります。
そして、1995年にはマイクロソフト社が「Internet Explorer」(インターネットエクスプローラー)で参入し、ブラウザ戦争に突入します。
この戦争は、長らくIEが苦労しますが、パソコンを押さえているマイクロソフトが地力を発揮して、逆転勝ち。ネットスケープの方はやがて「Mozilla Firefox」(モジラ ファイアーフォックス)となって再浮上してきます。昔はブラウザ専用のタグがあった!?
ブラウザ戦争では、ブラウザが個性を発揮するために、特別なHTMLタグをつくっていきました。
たとえばInternet Explorerが独自につくったタグで、「marquee(マーキー)」というのがありました。このタグではさまれた文字は、画面を右から左に、電光掲示板のように流れていきます。
Netscape Navigator側の独自タグで人気があったのは「blink(ブリンク)」!
このタグではさまれた文字はぴかぴか点滅しました。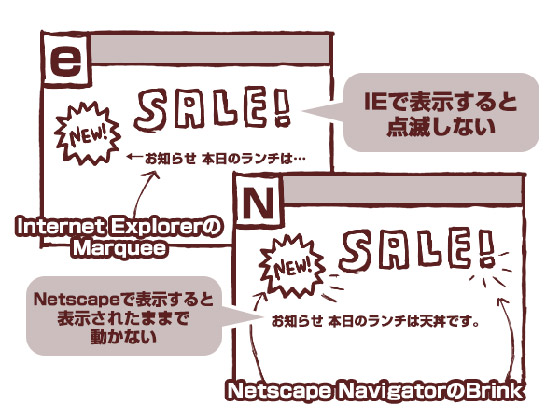
このときは個人が作ったWebサイトの大半は文字がマーキーしていたり、やたらぴかぴか点滅していたものです。今でも「NEW!」とかのマークがブリンクしているサイトはありますね。
こうしたブラウザによる独自拡張はHTMLタグの世界に混乱を招きました。企業のWeb担当者で「とにかく点滅させたい」「文字を電光掲示板みたいにしたい」と望む人が多くて、困ったのを覚えています。
回線が弱くてまだ動画などの使いにくい時代でしたから、サイトがちょっとでも動くというのはとても魅力的なものだったのです。
しかし、マーキーやブリンクといったブラウザ拡張は、そのブラウザが自分だけ解釈し表現できる方言のようなものでした。対応するブラウザを使っていないと独自拡張した部分が見られないのでは、「世界中の情報をつなぎ合わせて誰もが利用できるようにする」というWebの理想が制限されてしまいます。
こうしたブラウザの独自拡張が招いた混乱を収拾するために、「Web標準」という考え方が生まれた、と言ってもいいでしょう。現在のようにHTMLでは決められたことだけをやって、面白い部分はスタイルシートやスクリプトで何とかしてちょうだい、という考え方に落ち着いてきたのです。
「直帰率」という言葉の生みの親として知られるこの記事の筆者・石井研二氏がWeb改善の基本を解説する時間の講座を受けてみませんか?
- この記事のキーワード
関連記事
JavaScriptとは? Webサイトで何ができるの? 初心者向け解説【第8回】
2019年8月7日 7:00
HTMLの編集・修正をFTPで! 書き換え更新時に先祖返りを防ぐ方法
2021年1月27日 7:00
Webはなんで「ウェブ」なの? 結局ハイパーテキストって何のこと?【第3回】
2019年1月9日 7:00
検索エンジンの仕組み|ロボット型とディレクトリ型の特徴を比較【図解】
2021年4月21日 7:00
ページを1秒以内に表示するための最新技術、そしてSEOの未来(テクニカルSEOの復権 最終回)
2017年2月20日 7:00
必ず覚えておきたいHTML5の特徴と新機能/HTML5完全読本#1-1
2014年4月24日 8:00
バックナンバー
この記事の筆者

筆者の人気記事
平均閲覧ページビューから見えてくるウェブサイトの「目標」
2007年2月1日 7:59
階層構造を考えたホームページ構成とは サイト構造やツリーの作り方のヒント【第9回】
2019年11月13日 7:00
JavaScriptとは? Webサイトで何ができるの? 初心者向け解説【第8回】
2019年8月7日 7:00
KPIづくり実践術 徹底解説(1) - ゴールが明確でないサイトでも大丈夫!
2010年5月12日 9:00
Webサイトの画像読み込みが遅い原因とは? HTMLイメージタグの基本
2019年4月3日 7:00
サイトの「行き止まり」から見えてくる訪問者を逃がさない導線づくり
2007年3月13日 8:00




