検索エンジンの仕組み|ロボット型とディレクトリ型の特徴を比較【図解】
Googleだけでなく、Yahoo!やBingなどの検索エンジンの仕組みについて説明します。これらはロボット型とディレクトリ型という2つのタイプがあり、それぞれ情報収集の方法と分類の仕方が異なります。しかし、どちらも収集した情報をデータベースに登録し、絞り込んだ結果を表示するという共通の機能を持っています。さらに、検索エンジンを考慮した効果的なSEOとサイト作成方法についても解説します。
2021年4月21日 7:00
SEOやコンテンツマーケティングのテクニックをいくら覚えても、それだけでは成果は出ません。検索エンジンの情報収集の仕組みを知って、ウェブサイトを構造から強化していきましょう。
Webの成果を高める施策として、SEO(Search Engine Optimization)やコンテンツマーケティングへの関心がますます高まっています。でも、多くの人が1つのキーワードで検索順位を上げるための手法を学んでばかりいて、肝心なことが抜けているので成果が出ていません。
肝心なことは、検索エンジンはただ「どのページにキーワードが書かれているか」を捉えているのではなく、「このサイトはどんな構造をしているか」を学んで、それが検索利用者に役立つものかどうかを判断しようとしていることです。
この仕組みを理解せずに、ただキーワードを含むページをたくさんつくっても、検索エンジンは重視してくれません。検索エンジンがサイトのどこをどのように見ているか、今回はその仕組みを理解していきましょう。

検索エンジンと検索サービスの違いは?
検索エンジンとは、インターネット上でページや画像、動画などを探すのに使うもの。現在はGoogleのシェアが高く、他にはYahoo!、Bingなどが知られています。
こうしたサイトを一般に「検索エンジン」と呼びますが、厳密には「検索サービス」と呼ぶべきものです。検索エンジンは、「検索サービスが使っている検索の仕組み」を指します。つまり、検索環境をサイト上で提供するのが「検索サービス」で、その背後にある、情報を整理蓄積し、検索に応じて情報を紹介する仕組みを「検索エンジン」と呼びます。
たとえばYahoo!。今でもYahoo!の検索窓は多くの人に使われていますが、検索の仕組みはGoogleが提供するものを使っています。検索窓を提供するだけなら、Googleの検索窓を自社サイトに貼り付ければ、誰でも検索サービスを始めることができます。入力されたキーワードはGoogleの検索エンジンに飛んでいき、Googleのデータベースから合致する情報を見つけて帰ってくるのです。
検索エンジンの2つの型。ディレクトリ型とロボット型
検索エンジンには大きく分けて、「ディレクトリ型」と「ロボット型」があります。ロボット型の応用編として、複数のロボット型検索エンジンを同時に検索する仕組みのものがあり、「メタサーチ」と呼んで区別する場合もありますが、まずは「ディレクトリ型」と「ロボット型」について理解しましょう。
ディレクトリ型の検索エンジン
ディレクトリ型はもともと人の手で情報を収集して分類し、データベースに登録する仕組みでした。1994年にアメリカで生まれたYahoo!がその代表です。
最初は検索窓もなく、リンク集と変わらない姿でした。多くのサイトの名前と紹介文を登録し、カテゴリごとに分類して目次から選んでいけば目指すサイトにたどり着ける仕組みです。
たとえば、下記のように
ビジネス
B2B
金属加工
といった順番に目次を進んで深い階層に入っていくと、目指す「金属加工会社の一覧」にたどり着けます。こうした行き先案内を「ディレクトリ」と言います。ディレクトリは「こんなサイト、会社がありますよ」と教えてくれるものなので、紹介されるページは基本的にトップページです。そのため、Yahoo!ディレクトリ全盛の時代には、企業サイトへのアクセスは70%以上がトップページから始まりました。
ディレクトリ型検索エンジンの情報収集は人間が手間をかけて行っていました。紹介文も登録担当者が書いています。時間がかかるのが難点ですが、「質の悪いサイトは掲載されない」というメリットもありました。
何より、カテゴリをたどれば目指すサイトにたどり着けるので、検索側も楽でした。しかし、自分の目指す情報が何というカテゴリにあるのかわからなければたどり着けないという欠点もありました。
その後、Yahoo!にも検索窓が登場し、登録されたカテゴリやサイト名、紹介文に含まれる言葉でキーワード検索できるようになりました。ただ、サイトの紹介文は短文でした。当時のYahoo!の紹介文は30字以下で、「東京の金属加工会社。金型など」など素っ気ない文章でした。
しかも、すべて人の目で見て登録するので猛烈に時間がかかりました。3ヶ月は待たされるので、後になって登録にお金を払う「ビジネスエクスプレス」というサービスができたほどです。
そして1997年以降、サイトが爆発的に増え始めると、Yahoo!ディレクトリに登録されたサイトも膨大で、目指すカテゴリにたどり着いても、サイトがたくさん掲載されていて、どれが求める会社か選べない状態になりました。
そこで、ディレクトリ型に代わって「ロボット型」の検索エンジンが人気を集めるようになったのです。
ロボット型の検索エンジン
ロボット型検索エンジンは、ロボットと呼ばれる小さなプログラムがインターネット上を自動巡回して情報を収集する仕組みです。プログラムはネット上を泳ぎ回る(クロールする)ので、「クローラー」とも呼ばれます。ロボット型検索エンジンの先駆者「AltaVista(アルタビスタ)」が誕生したのは1995年、王者「Google」の誕生は1998年です。
ロボット型とディレクトリ型は情報収集の仕組みと分類の仕方が違いますが、集めた情報をデータベースに登録し、利用者の検索に応じて絞り込んだ結果を表示する点では同じ仕組みです。
Web担当者の方は、ディレクトリ型とロボット型の違いを以下のように覚えておきましょう。
- ディレクトリ型
登録内容:サイト名や登録担当者が書いた紹介文
リンク先:ほとんどがトップページ - ロボット型
登録情報:サイトに掲載されているテキスト
リンク先:検索キーワードが掲載されているページ(ファイル)
この違いで、ロボット型検索エンジンの利用者はトップ以外のページにやってくることが増えました。現在ではトップからのアクセスは20%未満。8割以上がトップ以外の深い階層のページからアクセスが始まるのです。
そして、決まった紹介文ではなく、サイトのどこに掲載された単語にでもヒットするようになったおかげで、人が決めた「カテゴリ」の枠を超えて、顧客と出会うことができるようになりました。かつてのWeb担当者は、Googleが出てきたときには、「ユーザーが検索する言葉を使えば顧客と出会うことができる」と喜びました。
このように、「ユーザーが検索する言葉」が大切なのですが、いつしか「会社が大事にする言葉」だと誤解されるようになりました。ユーザー側が誰も使わない言葉で検索順位を上げている状態は残念なことです。
ロボット型検索エンジンで情報を探す人は、なかなか良い解決策が見つからずに苦労しています。だから何度も工夫したキーワードで検索を繰り返します。そして「やっと良いサイトを見つけた!」と喜んでサイトにやってきます。重要なのは、「ユーザーはわからないから検索している」ということです。
私たちが検索エンジンについて考えるとき、まずは検索してサイトを見つけた人の喜んだ顔を思い浮かべるべきです。先に検索エンジンの順位決定ルールを思い浮かべてしまう人は、検索エンジン上の順位は上げられても、人との出会いには失敗します。ではこれからその理由を説明していきましょう。
ロボット型検索エンジンの仕組み
Googleなどのロボット型検索エンジンでは、情報収集にロボットやクローラーと呼ばれるプログラムを使います。
頻繁にロボットが訪れるサイトと、なかなか訪れないサイトの差は何でしょう? 頻繁に訪れるサイトにならなければ、SEOの努力は報われません。
私はサーバーログで分析する際は、ロボットが見たページを、人のアクセスとは別に集計します。企業が力を入れているコンテンツが、いつまでたってもロボットに気づかれていないこともあります。ロボットが気づかないのに、SEOやコンテンツマーケティングと言っていても仕方ありません。
また、企業が重要だと思っていないのにロボットが頻繁に情報を取りに来るページもあります。たとえば月刊の広報誌のページなどは、そのサイトで一番頻繁に情報が更新されているので、Googleのロボットに重視されます。
Googleのロボットがサーバーに来ると、「Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)」といった形で記録が残ります。「エージェント」と呼ばれる情報で、ユーザーが使っているブラウザの情報が記録されます。
「Mozilla compatible」とは、1990年代のNo.1ブラウザ「モザイク」というアプリの名前を引き継いでいます。昔、インターネット上には今より怪しいプログラムが走り回っていました。そこで、「ウェブを見る人のアクセスはだいたいモザイクを使っているので、モザイクのアクセスは通してあげよう」ということになりました。そこで、エージェント情報を見てモザイクならサーバーが通してくれるのです。その結果、ネット上を移動するプログラムが全員「Mozilla compatible」を名乗るようになってしまいました。
ロボットプログラムがブラウザのふりをするのは偶然ではありません。ロボットはページの内容を読むのが仕事です。やっていることは「テキストブラウザ」と同じなのです。ブラウザはページの内容を読んでパソコン上にページを表示しようとしますが、検索ロボットは検索エンジンのデータベース側に情報を送るのが仕事なのです。
エージェントの中に見られる「Googlebot(グーグルボット)」というのがこのロボットの名前です。ボットはたくさんあって、小さなボットがわーっとサイトに集まってきて、あっちこっちのページ情報を持って行ってくれるようなイメージです。
各ボットはそれぞれのIPアドレスを使って訪れるので、各ボットが何をやっているか、「個性」を調べることができます。
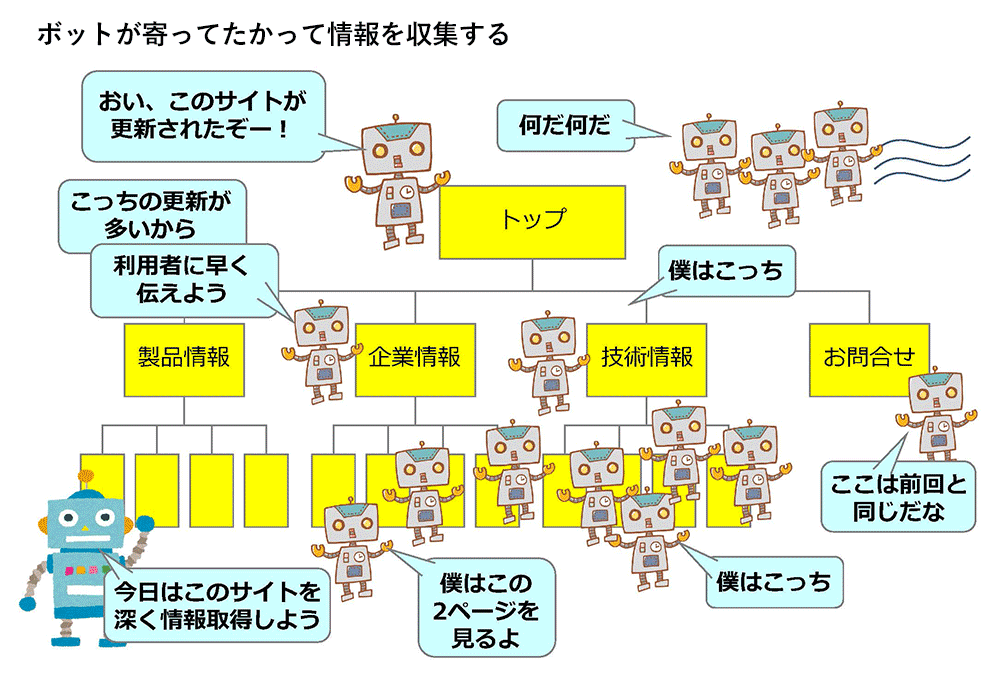
ボットはすべてのページをクロールするわけではないので、目次を作ろう
次に、ボットはどのようにやってくるのか説明します。最初に、見張り役のようなボットがやってきます。このボットは一種の更新チェッカーです。
タイミングが良ければ、更新したとたんにやってきて最新情報を取得してくれます。逆に悪ければしばらく待たされることもあります。見張り役がどれくらいのペースで訪れているか、調べることは重要です。
見張り役が見に来るのはトップページなどの重要ページです。重要かどうかは以下の項目などで判断されます。
- ページが多くのページへの目次になっているか
- 更新情報が掲載されているか
- このページ自体が頻繁に更新されているか
- 他の多くのページからこのページへリンクが貼られているか
サイトによっては見張り役が見に来るページは「ニュース一覧」だったり、「広報誌バックナンバー一覧」だったり、だいたいはコンスタントに更新されるコーナーの目次ページが多いです。
次に、見張り役ボットがこのページの更新に気が付くと、「このサイトが更新したぞー」と他のボットを呼び寄せます。他のボットが集まってきて、「自分はニュース専門です」「私は広く浅く見ていきますね」「今回はたくさんのページを見ていこうかな」とそれぞれ個性的な動きで情報を収集していくというイメージです。
ボットがページからページへ移動できるのは、ページ内容の中にリンクの記述を見つけるからです。あるページの内容を読んでいる途中でリンクに気付いたらそちらのページに移動していきます。だから、ニュースに気づきやすいようにしてやれば、最新情報がすばやく取得されます。検索エンジンはこうして、ウェブサイトのページとページの関係、サイトの構造を学習していきます。
しかし、ボットはすべてのページを見ていくわけではありません。たくさんのページを見てくれる「ディープクロール」が月に1度程度ありますが、たいていのボットは1、2ページ見たら帰るので、見てくれないページがあります。
- 平均1、2ページしか見ない
- ページの下の方の情報をなかなか持って行かない
以上のようなボットの問題を回避して、検索エンジンにサイトの構成を教え、ボットが効率よく回ってくれるようにするのがXMLファイルの「sitemap.xml」(サイトマップファイル)です。SEOノウハウサイトでは「これをサーバーに置いて、検索エンジンにその存在を伝えれば、ボットがそれを元にサイトの構造を踏まえて巡回してくれる」と教えていますが、実際にはそうは簡単ではありません。
本当は、サーバーログからボットが見ているページを集計して実態に応じて調整すると良いです。ボットが良く見ているページの上部に、伝えたいページへのリンクをはるというのが調整の基本です。ただ、今どきこの集計をするのは大変です。
ロボット型検索エンジンは、「重要ページ更新監視ボット」が「部分情報収集ボット」を呼び寄せるという仕組みです。これはつまり、「Googleは『サイトの構造』を学ぼうとしている」と言えます。「どのページが目次になって、検索者に役立つ情報がそこに属しているか」を見ているのです。そこで、Web担当者は目次を作って、その存在をGoogleに教える必要があります。ボットがサイト内に頻繁に訪れるようにするには、以下のようなことが重要です。
- ある分野の情報が網羅的に掲載されている
- さらに最新情報が頻繁に掲載される
- 新しい情報が各目次の上部に掲載されている
こうした目次にあたるページにはボットが頻繁に訪れて、いち早く最新情報を持って行ってくれます。たとえば、「月刊の広報誌のページ」はこの条件をおおむね満たしています。定期的に情報が追加され、独自のテーマで順番に内容が充実していきます。さらに、目次ページがはっきりと存在し、一番上に最新号へのリンクと内容紹介が載っています。これはGoogleにはとても理解しやすい「役立つサイト構造」です。
サイトの内容を更新せずに業者に頼んで検索順位を上げるという考え方はやめましょう。そんなサイトが上位に表示されても検索者のためにならず、Googleもそれに気づいて順位が下がるという繰り返しになります。
きちんと基本的な情報が網羅され、しかも常に最新の情報が発信されているサイトであれば、ボットはどんどん頻繁に訪れるようになります。これは検索エンジンのためではなく、お客様や見込み客のためになります。
また、Googleがページの品質評価で重視するポイントとして言われているのは「E-A-T」と呼ばれる以下の3項目です。
- 専門性(Expertise)
- 権威性(Authoritativeness)
- 信頼性(Trustworthiness)
これは、すべての会社にあるそれぞれの専門性や権威性、信頼性がサイトに載っていますか?ということです。
また、更新運営という言葉を聞くと、嫌がる会社もいます。「うちは毎年新製品が出る会社じゃないし、最新情報などありません」。本当でしょうか? 製品は向上を続けています。せっかくのマイナーチェンジで採り入れられた機能がサイトで紹介されていますか? お客様相談室が行った電話対応は「よくあるご質問」に反映されていますか? そうしたことが御社の専門性であり、権威性であり、信頼性につながるはずです。
ボットが見つけた情報は「インデクサ」に送られる
次に、サイトを訪れたボットはページの情報を読み取ると、「インデクサ」と呼ばれるプログラムに情報を送ります。インデクサは、インデックス(目次づけ)する人という意味です。受け取った情報を整理して、以下のような情報をデータベースに登録していきます。
- どんな単語がページのどの位置にあるか
- どのページからどのページにリンクがあるか
- リンクテキストにはどんな言葉が含まれているか
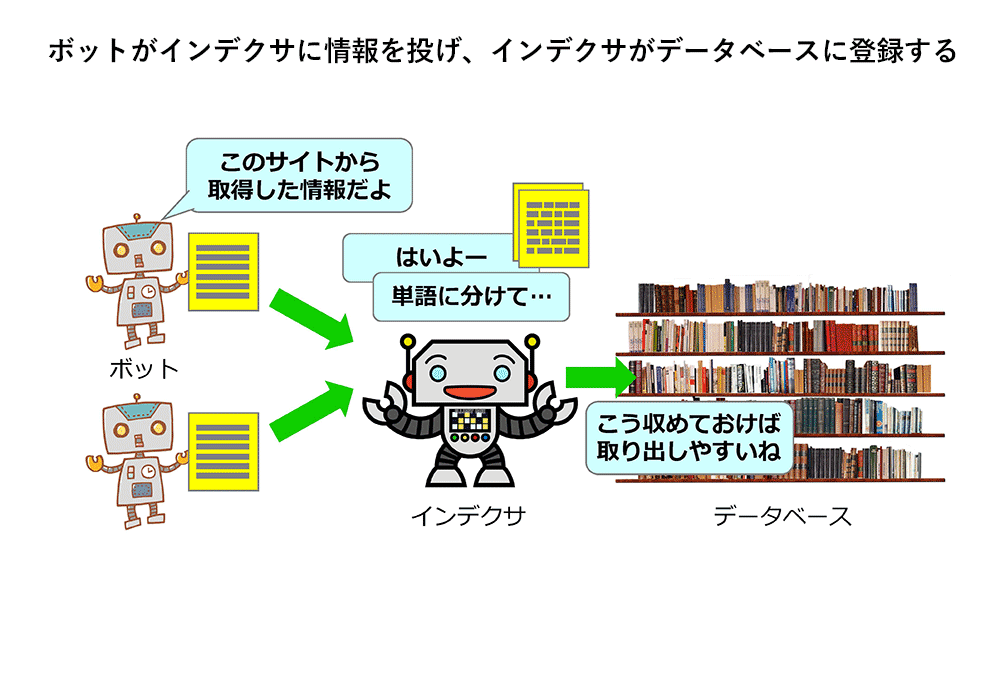
この整理のおかげで、検索に対して合致するページをどんな順番で紹介すれば良いかが決まります。この順番を決めるルールのことを「アルゴリズム」と呼ぶことがあります。「アルゴリズム」は検索に限らず、プログラムで「計算の手順や処理の流れ」を指す言葉です。
Web担当者はGoogleのアルゴリズム(ここでは順位決定ルールのことだと思ってください)を覚えようと一生懸命です。ときには「またアルゴリズムが変わった」と大騒ぎになることもあります。しかし、それを追いかけても何ひとつ良いことはありません。専門家に任せておきましょう。
それよりは自社の専門性ある内容をサイトに書くことです。社内にアンテナを張り巡らせて、顧客の役に立つ最新情報を追加・更新してください。無理にページを増やさなくても、同じページを内容調整し続ければ良いのです。
その結果、重要な目次になるページは頻繁に更新され、その上部には更新されたページへのリンクが掲載されるでしょう。そうすればボットは頻繁にやってきて、更新されたページにすぐ移動し、情報をインデクサに送るようになるのです。
SEOと検索エンジンの関係
ここまで検索エンジンの仕組みを解説してきましたが、ここからはSEOとの関係について説明します。アルゴリズムをいくら追いかけても、更新もしないサイトにはボットはそもそも来ないので、sitemap.xmlを置こうが、タイトルタグを作文しようが、あまり意味がありません。
サーチコンソールというGoogleのサービスから、インデックスの要望をGoogleに伝えることも可能ですし、それでボットが1回は来てくれるかもしれませんが、それで「このサイトは重要だ」とGoogleに理解させられるわけではありません。
また、コンテンツマーケティングでは「順番にページを作成して各ページからお問い合わせにリンクする」という作業をしている会社が多いですが、「全体を網羅する」コンテンツになっていきません。さらに、増えていくページを束ねるテーマがその会社独自のものになっていませんので、いくらページを増やしても、専門性や権威性、信頼性を感じるものになっていきません。
ウェブは辞書をつくっているようなものです。自社の得意分野で独自のテーマを決めてページを増やすことは重複ではなく「網羅」です。キーワードを含むページを増やしたいからといって重複する内容のページばかりつくっているサイトでは、役立つものになるとは言えませんので、Googleがより上位にすることもないわけです。
まずは少なくとも「全体の目次」をつくってから、ページづくりを始めましょう。業者が持ってくる目次は見積りに合わせたページ数ですから、必ずしも「網羅的」とは限りません。別にページ数が多いから偉いのではありませんが、抜け漏れが多い目次では困ります。
SEOの核心は、サイトのどのページを教えればユーザーの役に立つのか
SEOの核心の部分とは、「あるキーワードで検索した人に、どのページを教えてあげれば一番喜ぶか、役に立つか」です。
SEO業者さんは、サイト全体を変更するリニューアル業者ではないので、サイト全体に影響を与えないようにしながら、検索に有利になるようにサイトを調整してくれています。これもとても手のかかる仕事で、正直頭の下がる仕事なのですが、順位決定ルールを「ページ単位」で考えがちです。これでは核心の部分が見えなくなってしまいます。
また、検索順位だけを気にして、特定のキーワードで毎日検索して順位チェックしている人もいます。検索して自社サイトが出てきたら、クリックして、どんなページが紹介されているか確認してください。このときに、ちゃんとクリックしてページを表示してください。「なんでこんなページが出てくるんだ」とがっかりする検索者の気持ちを理解するためです。
的外れなページが紹介されていたら、検索で訪れた人が95%直帰します。技術系の会社ではPDFが紹介されることも多いです。会社名で検索しているのにプライバシーポリシーが紹介される悲しいサイトもあります。
たとえば、下図を見てください。全体の目次があって、カテゴリにわかれているブログのような構成です。
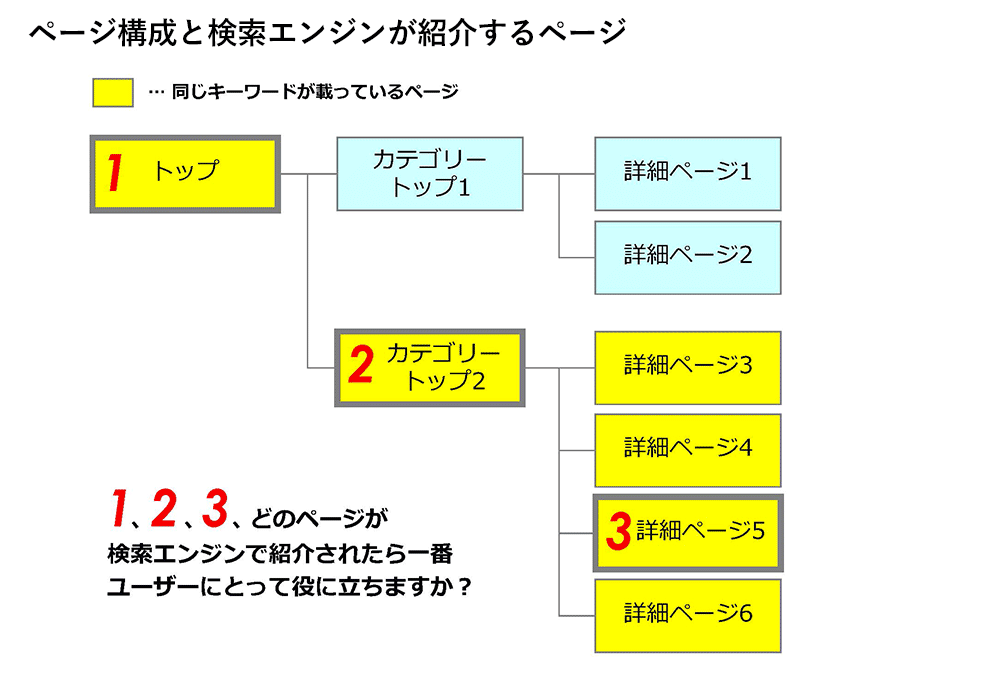
図のような構成だと、ユーザーはカテゴリ内の目次を見て、記事を選びます。黄色い色のページが、検索されたキーワードが載っているページです。さて、どのページが検索エンジンで紹介されたら、一番ユーザーの役に立つでしょうか?
正解は2です。
2の「カテゴリの目次」ページが検索結果で紹介されたとき、検索者はそこで自分が関心のあるページがたくさんあることに気付いて、その中から目的のページに進みます。
1の「全体の目次」ページが検索結果で紹介されても、今検索した
では、3の「個別ページ」の1つが紹介されたとしたらどうでしょうか。このページ自体は検索者の関心にフィットしていて、興味深く読めるかもしれません。しかし、同じキーワードについて関連するページがたくさんあることに気が付くことはできないし、次に進むページを選ぶのも難しいでしょう。
このように、カテゴリ(重視するキーワード)の目次があることで
SEOに効果的なサイトの作り方は?
たとえば、リニューアル時に、サイト全体に同じようなキーワードを含んだサイトをつくったとしましょう。
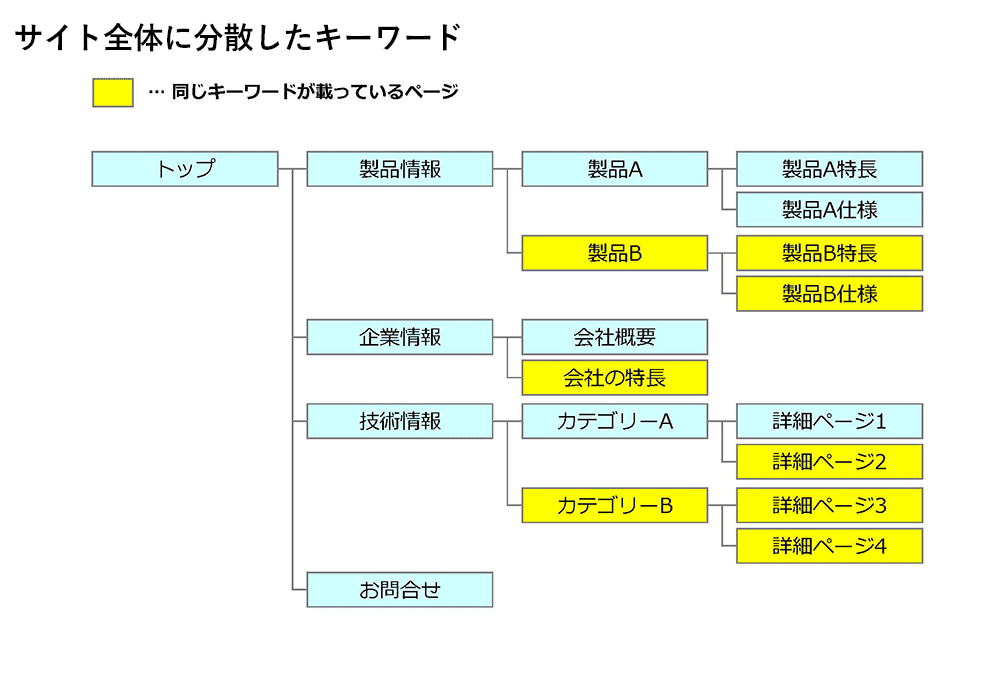
キーワードは各製品のページにも企業情報にも、技術情報にも存在します。しかし、こうなってしまうと、このキーワードを含むページを一覧する目次ページは存在しません。
全体のトップページが目次ページの役割を担ったとしても、トップページは「製品情報」や「企業情報」へのリンクしかありません。すると、このキーワードで検索した人には紹介されません。ブログで同じようなキーワードを含むページを次々に増やすサイトでは、このような「どこを紹介すれば良いのか検索エンジンが分からなくなる」現象が起こりがちです。
ロボット型検索エンジンの仕組みを知っておけば、多くのボットが訪れ、サイトの構造を学んでページの情報を取得していくので、サイトの中を横断する目次をつくって構造化することが必要だと理解できるでしょう。
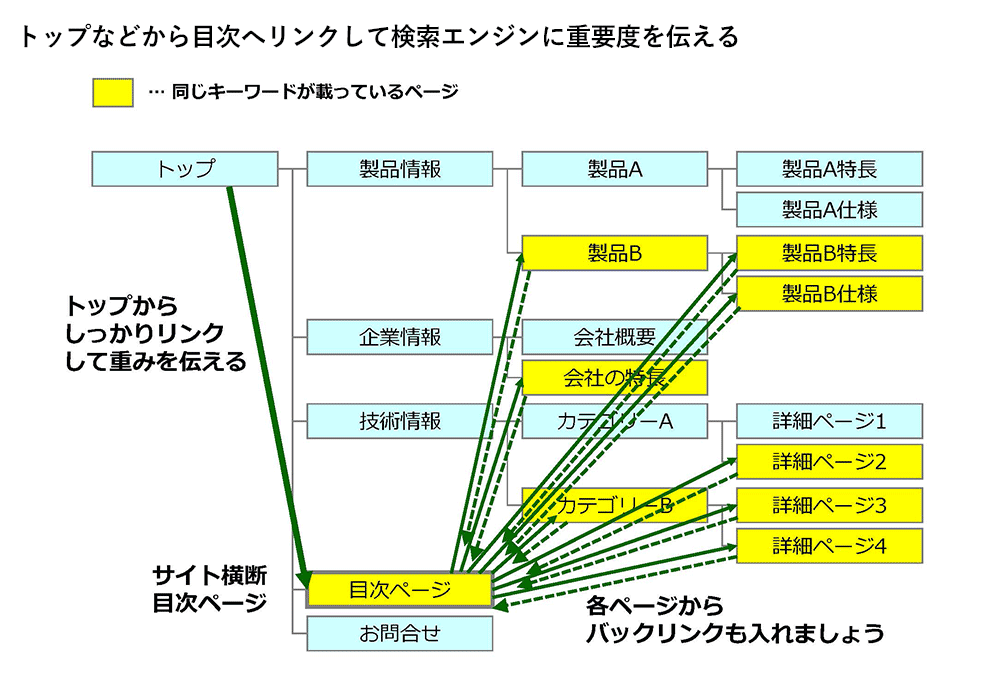
それでは、ユーザーが知りたい情報を届け、SEOで有利なサイトにするには、どうすればいいのでしょうか? まず、次の図のように、全体を俯瞰する目次ページをつくり、各ページにリンクをはっていきます。

この目次ページが検索エンジンで紹介されれば、検索者は多くのコンテンツに気が付き、見たいページを選べます。「情報豊富な良いサイトを見つけた!」と感じるでしょう。さらに、この目次ページを作ることによって、このキーワードについて、中心性を持ったページがどれか、検索エンジンが学べるようになります。
この目次ページはトップページやサイトマップのページの上部からリンクすることで、検索エンジンがクロールしやすく重要性を理解しやすくなります。また、分散した各ページのキーワードから、この目次ページに対して、テキストでリンクしましょう。このように、サイト内に分散した情報を目次ページで構造化することで、紹介すべきページを検索エンジンに教えていくのです。
さらに、目次ページには最新情報へのリンクがあると良いでしょう。ページの上部に、「NEW!」といったマークをつけて、最新情報を紹介し、リンクするエリアをつくります。情報を追加するたびにこの目次ページが更新されるので、Googleボットはこのページを頻繁に訪れるようになり、素早く最新情報に気付いてインデクサに渡すようになるのです。
このように、細かなアルゴリズムを覚えるより、検索エンジンがどのページを紹介すれば、検索者が「関連情報がたくさんあるサイトを見つけた」と気付くか、ということを考えてください。
おまけ「メタ・キーワードはGoogleの順位決定に使われないけど重要」
たとえば、Googleは順位決定に「メタ・キーワード」を使わない、と言われるようになって、メタ・キーワードというHTML要素を使わなくなったサイトもあるようです。メタ・キーワードとは、以下のような書式のタグです。「メタ・キーワード」は、そのページに関連のあるキーワードを列記するようになっています。
<meta name="keywords" content="keyrowd1,keyword2,keyword3..." />
このタグが自社サイトに記述されているかどうかは、一度確認しておきましょう。手順は以下の通りです。
- ブラウザで自社サイトのトップページを表示し、カーソルをページのどこかに置いて右クリック。
- 選択肢から「ページのソースを表示」を選択する。
- ctrl+Fキーを押して、「meta」もしくは「keyword」と入力して検索。
Googleは確かにこのメタ・キーワードのタグを順位決定に利用しなくなりましたが、Googleはこのタグを読んでいます。また、他のたくさんの検索サービスがこれを活用しています。
メタ・キーワードに、そのページに掲載している自社製品の品番を記入しておけば、サイト内検索で活用することもできるでしょう。廃番になったらメタ・キーワードの中を検索して、掲載箇所をすぐに特定できます。Googleが順位決定に使わなくなったといっても、メタ・キーワードは他にもいろいろと管理に使える、Web担当者の味方と言えるタグなのです。
「直帰率」という言葉の生みの親として知られるこの記事の筆者・石井研二氏がWeb改善の基本を解説する時間の講座を受けてみませんか?
- この記事のキーワード
関連記事
Webページを表示するために、ブラウザはHTMLを一生懸命読んでいる!?【第5回】
2019年3月6日 7:00
Googleアナリティクスでアクセス解析する方法【計測の仕組みとは】
2022年4月12日 7:00
サイト構成表の作り方 ~Excel&Googleアナリティクスと成績表の作り方【図解つき】~
2020年11月25日 8:00
HTMLの編集・修正をFTPで! 書き換え更新時に先祖返りを防ぐ方法
2021年1月27日 7:00
Webはなんで「ウェブ」なの? 結局ハイパーテキストって何のこと?【第3回】
2019年1月9日 7:00
企業ホームページの良いコンテンツに共通する7つの条件とは?
2014年11月11日 8:00
バックナンバー
この記事の筆者

筆者の人気記事
平均閲覧ページビューから見えてくるウェブサイトの「目標」
2007年2月1日 7:59
階層構造を考えたホームページ構成とは サイト構造やツリーの作り方のヒント【第9回】
2019年11月13日 7:00
JavaScriptとは? Webサイトで何ができるの? 初心者向け解説【第8回】
2019年8月7日 7:00
KPIづくり実践術 徹底解説(1) - ゴールが明確でないサイトでも大丈夫!
2010年5月12日 9:00
Webサイトの画像読み込みが遅い原因とは? HTMLイメージタグの基本
2019年4月3日 7:00
サイトの「行き止まり」から見えてくる訪問者を逃がさない導線づくり
2007年3月13日 8:00




