グーグルをも脅かしつつある垂直検索を掘り下げる——iMedix経営陣とのインタビュー(前編)
2008年4月8日 9:00
僕はこれまで、検索エンジンの将来についてさまざまな可能性を述べてきたし、「グーグルの市場支配を脅かす4つの大きな問題というテーマで記事を書いたこともある。
※Web担編注 「グーグルの市場支配を脅かす4つの大きな問題」という記事では、以下の5つの可能性を論じている。
- 他の検索エンジンがより良い検索結果を提供することでシェアを得る
- 新しいベンチャー企業が検索で台頭する
- ウェブ検索の中心が垂直検索に移る
- ウェブ検索が他の種類の情報探索モデルで置き換えられる
- スパムがあふれて使い物にならなくなる
そこで今日は、そのテーマをさらに進めて「垂直検索による細分化」の可能性について考察してみようと思う。
iMedixは、現在市場に出ている中でもとりわけ刺激的な垂直検索エンジンだ。crunchiesの最優秀新規ベンチャー企業賞を受賞しただけではなく、市場でも優秀な専門家の多くから非常に高い評価を得ている。気に入らないという人もいるようだが、ビジネスチャンスに恵まれた市場で、開発の面でもマーケティングの面でも実にうまくやっている。
iMedixは「健康」というテーマに絞った検索サービスを提供しているのだが、そのサービスにおける最大の「売り」は、検索結果と連携するソーシャルネットワークを組み込んでいることだ。
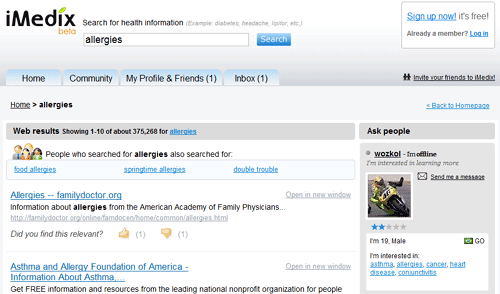
上図は僕が「allergies(アレルギー)」で検索した結果だが、同じテーマに興味をもっている人、その話題について話したいと思っている人のリストがサイドバーに表示されている。これは、健康に関する人間の心理をうまくとらえている。つまり、こと健康問題に関しては「自分だけじゃないんだ」と思いたいものだからね。iMedixのコミュニティは他の大半のコミュニティより強い絆で結びつけられていて、もしかすると、そのことがこのサービスを際立たせているんじゃないかと思う。
最近、僕はiMedixの最高マーケティング責任者(CMO)イリ・アリマブ氏と最高経営責任者(CEO)のアミール・ライタースドルフ氏に、iMedixのこれまでの歩みと同社の検索技術についてインタビューする機会を得た。
よく知らない人のために、iMedixの基本的な成り立ちを教えてもらえますか。設立の経緯と、企業としての目標は? また、ビジネスモデルはどのようなものでしょう?
iMedixを始めたのは、健康について私たち2人に個人的なニーズがあったからです。2人ともウェブを高く評価しているので、健康に関してはより適切な判断を行いたいと望んでいる人のためのリソースとして、ウェブを利用する余地が大いにあると考えました。
しかし、一般的な水平型(horizontal)検索エンジンしか使わないのは、健康関連の情報を検索して共有する方法としては不十分だと感じていました。多くの場合、無関係な結果が提示されるだけでなく、何の助けにもならず、強い不安ばかりが残ります。オンラインには優れた情報があることはわかっていました。しかし、それが十分に整理されていないのです。
それに、健康に関して貴重な経験や知識を持つ人がいても、手早く連絡を取り合うことは困難でした。そこで、患者自らが原動力となり、患者自身に恩恵をもたらすような、健康に特化した検索エンジンを開発しようと決めたのです。私たちはまず試作版を作りました。それをアルファ版に改良して、そして現在皆さんがiMedixのサイトでご覧になっているベータ版にアップグレードしたのです。
垂直検索という観点から見て、iMedixにはグーグル、ヤフー、Live.comから検索トラフィックのマインドシェアを奪う能力があると思いますか? 人々がウェブにアクセスするとき、「健康・医療の問題について検索する必要があるから、グーグルではなくiMedixを使おう」と考えるようになると思いますか? それとも御社の戦略は、iMedixをむしろWebMDに近いポータルとして構築し、主要検索エンジンの検索トラフィックを引きつけるというものなのでしょうか?
ヘルスケア情報をウェブで見つけて共有するという体験は、間もなく劇的に変わると考えています。大いに差別化された価値ある体験なら、既存のウェブサイトからトラフィックのマインドシェアを奪えるでしょう。
というのも、iMedixが消費者に提供する体験は、グーグルともヤフーともLive.comとも大きく異なっています。今の人たちは、お互いにコミュニケーションをとり、さまざまな方法で関わり合うことに魅力を感じています。人は、単なる検索と閲覧を超えるものを求めているのです。その好例として、ソーシャルネットワークがこの3年で従来のポータルからかなりのトラフィックを奪って大きく成長したことが挙げられます。
私たちは現在、革新的なマーケティングアプローチを実験していますが、まさに将来有望という感じですね。私たちが相次いで導入している数々の新機能の目的は、健康に関する貴重なユーザー作成コンテンツ(UGC)の作成を可能にすることと、特に重要なのが、急速に成長しているコミュニティのニーズに応えることです。だれかが価値を創造し豊かな体験を生み出してくれたら、ほかの人たちもついてくると考えています。
iMedixも主要検索エンジンと同じく、ウェブサイトをクロールしてインデックス化しているようですが、ウェブ全体をインデックス化するのではなく、健康関連のドメインのみに検索範囲を限定していますね。その対象範囲は人が選別しているのですか? もしそうだとしたら、情報範囲が狭められるという心配はありませんか? それとも、より権威のあるソースの情報が集められていて、ブログやスクレーパー(コンテンツ盗用者)が少ないことによって検索利用者は満足すると思いますか?
iMedixは、ウェブから最も有益で関連性の高い健康記事だけを選んでクロールし、インデックス化しています。iMedixの特許技術を使って、膨大な数のウェブディレクトリおよび医療データベースをクロールし、インデックス化していますが、英語で書かれた著名な医療関連サイトのほとんどがその中に含まれています。この方法で私たちは、医学界に知られているすべての症状、疾病、処置をカバーすることができているのです。
検索エンジンのクローラを開発する際、自力で作り上げたのですか? それとも、オープンソースの検索エンジン「Nutch」のような技術を利用したのでしょうか? iMedixは、そうした転置インデックスのデータベースをすべて管理しているのですか? それとも、サードパーティの技術を使用しているのでしょうか? また、インデックスには何ページぐらい入っているのですか?
iMedixのクローラは、社内で開発したマルチスレッドの分散コンピューティング技術で、数百のウェブサイトを同時にクロールできます。このクローラは広帯域ネットワークを利用しており、使用するデータベースは1つですが、クロール対象サイトのパフォーマンスを低下させることなく、1時間に平均50万ページをクロールすることができます。
クローラは、ページ間の類似性を検知して「過剰クロール」しないようにしています。また、わが社のクローラは、サイトのコンテンツの変更頻度も検知できるので、その情報をもとに、各クロールセッションで最大限のデータを更新できるように、クロールのスケジューリングを最適化しているのです。
文書をベクトル空間モデルで記述するのにはオープンソースのプロジェクトを利用していますが、インデクサは社内で開発しました。それから、分割統治アルゴリズムをベースにしたグリッドコンピューティングアプリケーションも開発しました。これによって、1秒間に何百という文書をインデックス化して、バックグラウンドでインデックス化の作業を継続しつつ、すぐに検索できるバイナリファイルへの変換が可能になったのです。
iMedixがインデックス化しているページの数は、大きく変動します。というのも、私たちは絶えずクロールするサイトの数を増やしていますが、その一方で、不適切と判断されたページの削除が、自動的な方法(クローラまたはインデクサによるヒューリスティック評価)とスタッフによる手作業の両方で行われているからです。そうした要素により変動がありますが、iMedixの最新版では1000万~2000万の健康関連ページのインデックスを使用しています。
今回は、iMedixについて、技術的な側面を中心に話を伺った。後半では、ランキングアルゴリズムに関する技術的な話とともに、同社のビジネス戦略についてお届けする。→「垂直検索におけるコミュニティの役割——iMedix経営陣とのインタビュー(後編)」を読む
- この記事のキーワード
関連記事
垂直検索におけるコミュニティの役割——iMedix経営陣とのインタビュー(後編)
2008年4月9日 9:00
「SEOマニフェスト」で考えるSEO担当者の「べし」「べからず」(後半)
2008年4月21日 9:00
検索エンジンのアルゴリズムとは? 過去6年の変遷にみる順位決定の仕組み
2008年3月25日 9:00
[必見インタビュー]NYTimesのマーシャル・シモンズ氏が語る大規模メディアサイトの戦略とSEO
2007年10月29日 8:00
リンク獲得で良質のディレクトリを判断する10のポイント
2007年8月10日 10:10
SEO業界の10年を振り返る(後編) - アフィリエイト, UGC, ソーシャルメディア, アクセス解析
2009年5月14日 9:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




