クローラーとは/検索エンジンの仕組みをおさらい。クローラー対策とステータスコード
検索エンジンの機能の一つであるクローラーは、Webページをステータスコードで振り分けています。万が一、そのコードが意図しないものになっていたら……
2009年3月27日 9:59
スキルセットや共通言語が異なる
エンジニアとWeb担当者をつなぐための手引書

いよいよ今回から、SEOに関する技術的な項目を解説していきます。まずは、SEOを行う上で最も重要となる検索エンジンの全体像をおさらいし、クローラー対策に必要なステータスコードを詳しくみていくことにします。
- エンジニアさんへ
前回の記事では、まずSEOがどんなものかという説明からスタートしました。続いて今回はSEOの相手である、検索エンジンを詳しく解説します。今回の記事の対象者



- Web担当者さんへ
マーケ寄りな担当者さんだと苦戦する内容かもしれませんが、エンジニアさんが日々どんなことを考えながら作業をしているのか把握しておくのも重要です。また、今回紹介するソフトを活用すると、あなたのサイトがどのようになっているのかを確認できます。もしもステータスコードが間違っていたら……一度エンジニアさんと調整をしてみることをオススメします。
検索エンジンの仕組み
SEOを行う上で、検索エンジンの仕組みを理解しておくことは必要不可欠です。なぜなら、やみくもにテクニックだけを追い求めるのではなく、相手(検索エンジン)がどのように自社のサイトのコンテンツを処理しているのかを理解することで、より効率的にサイトを最適化していくことができるからです。
現在の検索エンジンは、自動的に解析するソフトウェアを用いたロボット型が主流です。ロボット型の検索エンジンでは、大きく3つの機能が動作しています。
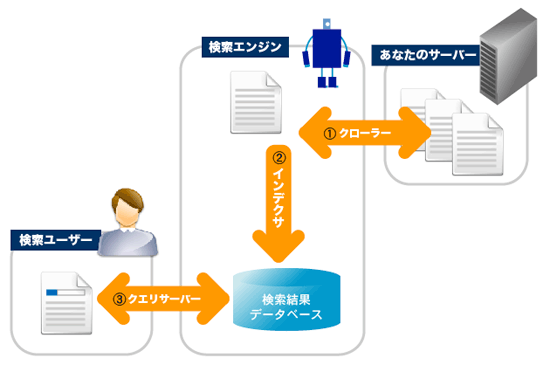
- クローラー:HTTPプロトコルでコンテンツを取得する
あなたの運営しているサーバーを含めた世界中のWebサーバーと通信し、そのサーバー内のコンテンツを取得していきます。通信手段はHTTP/HTTPSプロトコルなので、HTTP/HTTPSで取得できるものは、なんでも持っていきます(テキストファイル、CSSファイル、JavaScriptファイル、画像、Flash、PDFなど)。
- インデクサ:取得したコンテンツを解析し保存する
取得したコンテンツの内容を解析します。ここで取得したコンテンツのキーワードやテーマを分析して読み取り、分析結果とそのファイル自体をデータベースに保存(インデックス)します。
- クエリサーバー:ユーザからの検索クエリ(キーワード)の結果ページを返す
ユーザの検索キーワードに基づき、保存してあった解析結果を検索結果ページとして作成し、表示します。SEOの結果が反映される部分になります。
クローラー対策は、検索結果での順位にはほとんど影響しませんが、SEOでは大きなポイントです。なぜなら、どれだけSEOをしても、検索エンジンのデータベースに登録されなければ検索結果に反映されないからです。では、いかにしてクローラーに適切にサイトのページを処理してもらえばいいのでしょうか。今回は、クローラーがプログラム上どのようなことをしているかに着目していきたいと思います。
クローラーには適切なステータスコードを伝える
あるページに「A HREF=“~~”」でリンクされているURLを見つけると、クローラーはそのURLをHTTPプロトコルで「GET」します。HTTPプロトコルでは、リクエストに対してレスポンスを返します。そのレスポンスにステータスコードと呼ばれるものが含まれていて、クローラーはこのステータスコードで処理を振り分けています。
エンジニアの方々にわかりやすいようにページをGETするプログラムを考えてみました。オブジェクト指向の言語ならば、基本的にHTTPプロトコルを扱うクラスは準備されていると思います。たとえば「C#」なら、以下のようなソースになるでしょう。
HttpWebRequest httpReq =
HttpWebRequest)WebRequest.Create("http://www.example.com");
httpReq.AllowAutoRedirect = false;
HttpWebResponse httpRes =
(HttpWebResponse)httpReq.GetResponse();
// ステータスコード
if ( httpRes.StatusCode==HttpStatusCode.OK)
{
// 200 OKなら?
}
else if (httpRes.StatusCode==HttpStatusCode.NotFound)
{
// 404 NotFoundなら?
}
:
:
httpRes.Close();
参照:http://msdn.microsoft.com/ja-jp/library/system.net.httpstatuscode(VS.71).aspx
あとはサーバーが返したステータスコード別にそれぞれのロジックを考える必要がありますが、もちろん検索エンジンのクローラーも同じことをやっています。ですから、リクエストに対して適切なステータスコードを返すことがSEOの最初の1歩となり、とても重要な要素となります。
| ステータスコード | 内容 | 用途 |
|---|---|---|
| 200 | OK 成功しました | 基本的には、この200という数値を返します。アクセスのあったURLに対して200を返すと、検索エンジンはデータベースに保存(インデックス)し、検索結果に表示されるようになります(逆に200を返さないと、絶対にインデックスされません)。 |
| 301 | Moved Permanently 移動しました(リダイレクトしてください) | もともと存在したページが、違うURLやドメインへ移動したことを示します。「302」も似たような意味がありますが使い方がちょっと違います(301と302の使い方は別の機会に説明します)。 |
| 404 | Not Found ページがないです | そのリクエストしたURLには返すべきページがないという意味です。検索エンジンは404を返すと、そのURLをインデックスから削除しようとします。 |
他にもさまざまなコードがありますが、基本的には200を返し、ページのURLが変更されていたら301、ページが存在しないなら404を返すのが基本です。
SEOの基本として、新しく作ったページをなるべく早く検索結果ページ経由でユーザーに見てもらうためには、検索エンジンにたくさんクロールさせて、該当ページをインデックスしてもらうことが重要です。
存在しないページに「200(OK)」を返していると……
ここで注意したいのが404ページの取り扱い方法です。たとえばECサイトで取り扱いがなくなった商品を表示すると、「この商品はありません」というページが表示されます。しかし、見た目上ではステータスコード「404」を意味するページを表示しているのですが、実際にはステータスコードとして「200」を返しているシステムがあります。
そのような場合、ステータスコードが「OK」を意味する「200」なので、検索エンジンはそのページが「ある」と判断し、「この商品はありません」というページがずっと検索結果に表示され続けてしまいます。検索エンジンに「ない」ことを明示したいのならば、ページの内容だけではなくステータスコードでも正しく「404」を返すようにしましょう。
逆に商品がなくなったページでも意図的に「200」を返すケースがあります。せっかくインデックスされたのなら、「404」を返して検索結果ページから削除させるのはもったいないという戦略です。ただし、たとえそのリンクをクリックしてサイトに来ても商品がない場合は、利用者にとって有益なページとはいえず、おのずと直帰率は高くなるでしょう。サイト内検索ボックスを設けたり、関連商品をうまく見せたりするなどの工夫が必須です。
自分のサイトを確認してみよう
ここでは、Fiddler2というフリーソフトを利用し、自分のサイトのステータスコードを簡単に確認する方法をご紹介します。日本語化はされていませんが、ブラウザの挙動と連動しているため、他のヘッダービューアと比べて使いやすいソフトといえるでしょう。また、通常HTTPSのアクセスは暗号化された状態で通信するのでどんな内容がやり取りされているのかを確認することが難しいですが、このFiddler2はHTTPSも復号して表示するのでデバッグ作業などにも使えます。
参照:http://www.fiddlertool.com/fiddler2/version.asp(インストールには.NET2.0ランタイムが必要)
※他に、横取り丸、IBM Page Detailer、LiveHTTPHeaders(FireFox用アドオン)といったソフトもあります。
Fiddler2をインストールして起動すると、自分のパソコン上にHTTPのプロキシサーバー(デフォルトでlocalhost:8888)として設定されます。自分が利用するブラウザのプロキシサーバーの設定を変えると、Fiddler2上をHTTPプロトコルが流れ、どのような情報が流れているかを目で確認することができます。
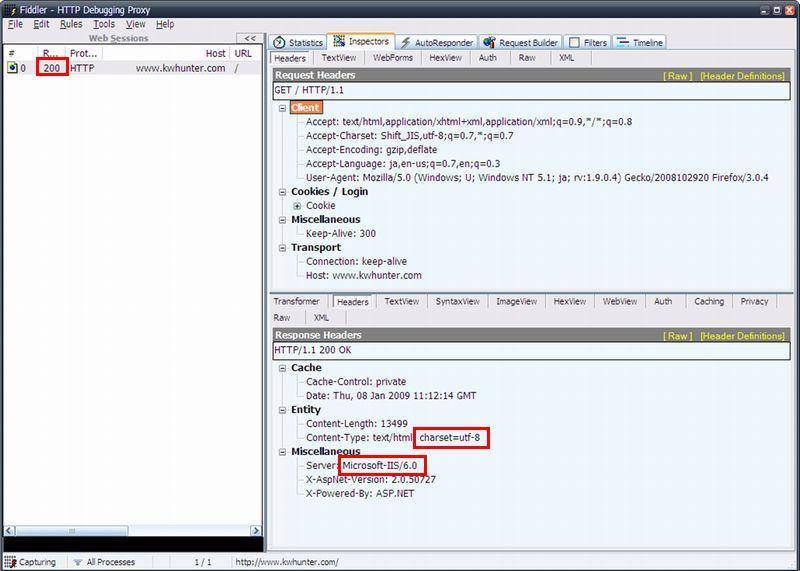
キーワードハンターはWebサーバーがIISで文字コードがUTF-8ということが確認できる
プロキシサーバーの設定が終わったら、ブラウザからアクセスしてみてください。左側のペインにアクセスの流れが表示され、「Result」のカラムにそのアクセスの応答コードが表示されます。また、右側のペインにはいくつかのタブがありますが、「Inspectors」タブをクリックすると上下に分割されます。さらに上下とも「Raw」タブを選択してください。そうすると上側は生のHTTPのリクエスト、下側は生のHTTPのレスポンスが表示されます。
このソフトを利用して、今一度自分のサイトを確認してみてはいかがでしょうか? 思わぬ404や301コードを見つけられるかもしれません。
またクローラーは、ステータスコード以外にもサーバーからの返事(レスポンスヘッダー)を見ています。レスポンスヘッダーは基本的にWebサーバー(ApacheやIISなど)が自動的に生成しているので、あまり意識することがありませんが、ここで代表的なヘッダーをいくつかご紹介します。HTTPヘッダーとしてRFCで規定されています。詳細は以下を参照してください。
| ヘッダー | 値の例 | 意味 |
|---|---|---|
| Date | Wed, 14 Jan 2009 07:27:27 GMT | メッセージが生成された日付時刻 |
| Server | Apache | リクエストを処理するサーバが使っているソフトウェア |
| Last-Modified | Wed, 14 Jan 2009 06:38:18 GMT | コンテンツの最終更新時刻 |
| Content-Length | 172219 | サーバーが送るデータ本体の大きさ |
| Expires | Wed, 14 Jan 2009 07:27:28 GMT | コンテンツの有効期限 |
参照:http://www.ietf.org/rfc/rfc2616.txt(英語)
参照:http://www.studyinghttp.net/rfc_ja/rfc2616(日本語参考訳)
レスポンスヘッダーはSEO効果を左右させるものではないのですが、こういう部分もクローラーは参照しているということを知っておいてほしいと思います。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事




