クロールバジェットをどう制御するか(後編) クロールバジェット問題への対処と実践ポイント
この記事は前後編の2回に分けてお届けしている。
後編となる今回は、クロールバジェット対策のうち、残る「リンクレベルのnofollow」「noindex, nofollow」「noindex, follow」「URL正規化タグ」「301リダイレクト」を使う方法について見ていこう。
最後には、サイトマップを使った最新のやり方も紹介する。
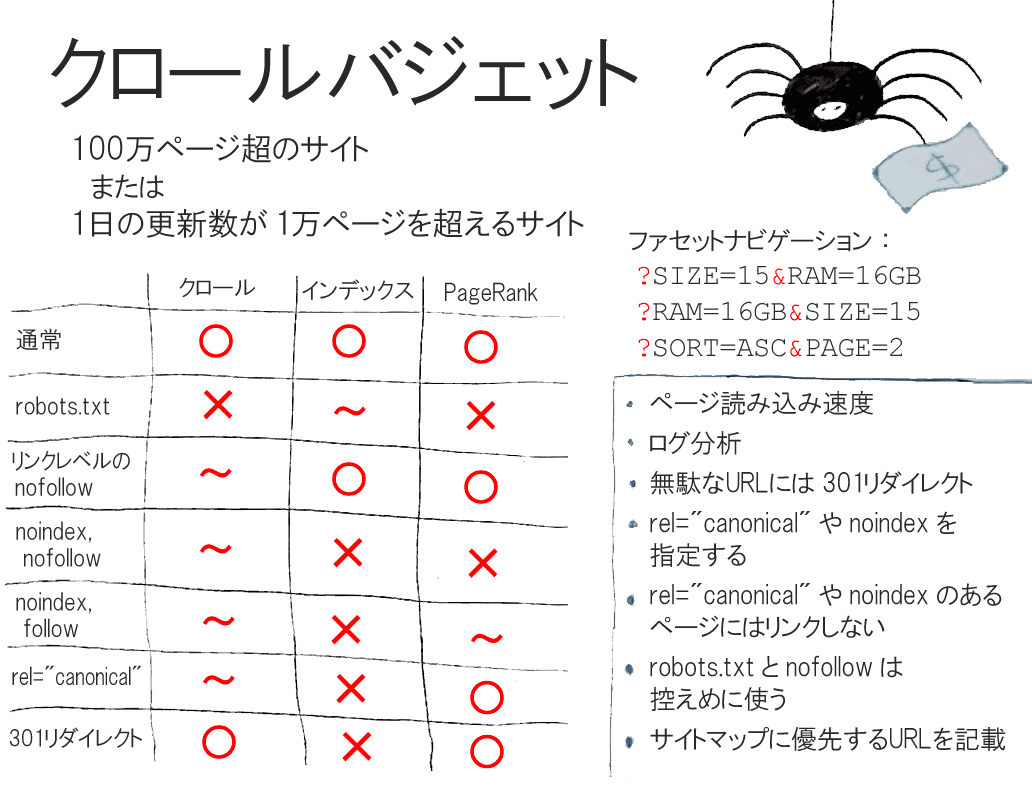
クロールバジェット問題への対処方法(続き)
リンクレベルのnofollow
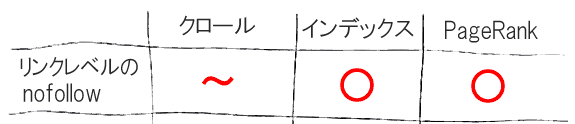
リンクレベルのnofollow、これはページHTMLでリンクのためのa要素にrel="nofollow"属性を指定することだ。
これでわたしが言いたいのは、ノートPCのカテゴリページにリンクがあり、こうしたファセットにリンクが張られている場合、サイト内リンクにnofollowのrel属性を設置すると、メリットとデメリットがあるということだ。
うまく活用できるのは、どちらかというとUGCによるリスティング(投稿)のケースだろう。中古車のウェブサイトを運営していて、膨大な種類の中古車の、個々の製品リストのようなものがあるとしよう。サイトの規模にもよるだろうが、個々のリスティングをクロールするのに時間を浪費するのをグーグルにやめてほしい場合がある。
しかし、時に有名人が所有している車などをアップロードしたり、希少な車がアップロードされたりして、メディアのリンクが集まりはじめることがある。robots.txtによるページのブロックは、外部リンクが無駄になるのでやりたくない。やるとすれば、そうしたページへのサイト内リンクについて、内部のリンクはたどらないようにする。そうすることで、クロールは可能ではあるが、それは見つかってしまった場合だけ、グーグルが外部リンクなどなにかほかの方法で見つけてくれたときだけになる。
だからクロールについては中間だ。技術的には、nofollowはこのところヒントという扱いになっている。経験上、nofollow属性付きのサイト内リンクを通じてしかリンクされていないページをグーグルがクロールすることはない。だが、そのページがほかの方法で見つかると、グーグルは間違いなくクロールする。それでも全般的に、クロールバジェットの効果的な制限方法ではあるし、クロールバジェットのより効率的な使い方だといえる。それでいてページはインデックスできる。
PageRankをちゃんと渡せるのも、望んだ状態だ。とはいえ、nofollowリンクを通じて失われるPageRankはある。リンクと見なされることに変わりはなく、followリンクだったら送り込まれていたPageRankが失われていく。
noindex, nofollow

ページのHTMLのhead要素内でmeta robotsタグに「noindex, nofollow」を指定するのは、Eコマースのページにはおなじみの解決策だ。
この場合、グーグルはページをクロールする。しかし、グーグルはページにたどり着くと、noindexの指定を見つける。すると、noindexのページをクロールしてもあまり意味がないから、長期的にはクロールの頻度が大幅に下がる。つまりこのケースもクロールについては中間だ。
当たり前だがインデックスはされない。noindexなのだから。
またPageRankを引き渡すことはない。PageRankを渡されることはあるが、nofollowを指定しているので受け取ったPageRankを他のURLに渡すことはない。この点はあまり良くない。
このあたりのデメリットは、クロールバジェットを節約するために求められる妥協のポイントだ。
noindex, follow
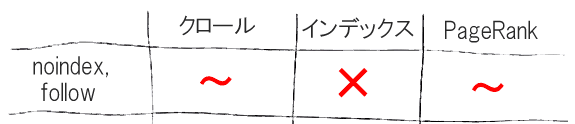
そこでかつては多くの人がこう考えた。noindexとfollowにすれば、両者のいいとこ取りの解決法になるではないか、と。
ページのHTMLのhead要素内でmeta robotsタグに「noindex, nofollow」を指定すると、クロールの恩恵は同じように手に入るので、だれもが笑顔になる。
インデックスさせたくない新たにできる重複ページなどはインデックスされず、それでいて、PageRankの問題は解消する。
ところが数年前、グーグルが次のように言った:
あのですね、われわれも把握していなかったのですが、こうしたページは、実際にはクロールを徐々に減らしていくんですよ。なので、やがてリンクを見なくなり、最終的にはクロール対象としなくなるんですよ。
つまり、PageRankを渡し続ける方法としてはもう機能せず、いずれnoindex, nofollowのケースと同じ扱いになるとほのめかしたのだ。そのためこの方法もあまりあてにできなくなっている。
rel="canonical"

そうすると、すべての面で本当にベストなのはURL正規化タグということなのかもしれない。各ページのHTMLのhead要素内で、link要素にrel属性でcanonicalを指定して正規化URLを指定するやり方だ。
URL正規化タグを使うと、時間が経ってもクロール頻度が少し減るだけだ。すばらしい。インデックスはしてもらえる。すばらしい。それでいてPageRankは引き渡せる。
すばらしいもののように思える。多くの場面で完璧なようだ。
しかし、これがうまく機能するのは、「グーグルが重複と見なしてURL正規化タグを尊重してくれるほど似通ったページ」のみだ。グーグルが重複と見なしてくれない場合は、noindexの利用に戻る必要があるかもしれない。
また、存在理由すらまるでないと思えるようなURLの場合は、こういったおかしな組み合わせがどのように生み出されたのかは不明だが、まったく無意味に思える。
301リダイレクト
このページにはもうリンクしない。それなのにどうにかしてURLを見つける人がまだいる場合、手軽な方法の1つとして301リダイレクトが利用でき、結果的にかなりよい成果が得られる。要は、そのURLへのアクセスはすべて他のURLへと強制的に転送するわけだ。
グーグルがたまにチェックしにやってきても、とにかく301リダイレクトの指示に従うわけだから、ページを見る必要すらなくなる。だから、クロールバジェットの節約のためならばURL正規化タグやnoindexよりも良いはずだ。
インデックスの問題が解消し、しかもPageRankは渡してくれる。ただもちろんトレードオフはあって、ユーザーもURLにアクセスできなくなるので、この点は了承しておく必要がある。
クロールバジェット対策の実践ポイント
すべての戦術を整理したところで、実際にはどのように使っていけばいいのだろうか。クロールバジェット対策を実践してみようという人に、わたしならどんな対策をおすすめするだろうか。
ざっと、次の7つが思い浮かぶ:
- ページ読み込み速度
- ログ分析
- 無駄なURLには301リダイレクト
- rel="canonical"やnoindexを指定する
- rel="canonical"やnoindexのあるページにはリンクしない
- robots.txtとnofollowは控えめに使う
- 優先するURLをサイトマップに記載
それぞれ解説していこう。
ページ読み込み速度
直感的にはわかりづらい対策の1つがページの読み込み速度の改善だ。すでに述べたように、グーグルがあるサイトに割り当てる、クロールの時間ないしリソースは決まっている。ということは、
- サイトが高である
- サーバーの反応時間が短い
- HTMLが軽い
ならば、同じ時間(リソース)でクロールしてもらえるページ数は単純に増える。
そのため、ページの読み込み速度を改善することは、クロール状況を改善するのにすばらしいアプローチ方法だ。
ログ分析
次がログ分析だ(昔ながらの方法だ)。クロールバジェットを実際に奪っているのがサイトのどのページなのか、どのパラメーターなのかは、なかなか直感的にわかりにくい。大きなサイトはログを分析すると驚くような結果が得られることが多いので、検討をおすすめする。
ここで言う「ログ分析」は、Googleアナリティクスなどを使ったアクセス解析のことではない。Googlebotのアクセスが記録されている「Webサーバーログファイル」の分析だ。
そうしたログファイルの分析を通じて状況を把握し、この記事で紹介したような対策を実際に適用していくのだ。
無駄なURLには301リダイレクト
ユーザーが見る必要すらないと思われる無駄なURLには、301リダイレクトが使える。これは効果的な対策だ。
rel="canonical"やnoindexを指定する
ユーザーに見てもらう必要があるバリエーションには、301リダイレクトは使えない。そのため、
- URL正規化タグ(rel="canonical")
- noindex
といった手法を検討する。
rel="canonical"やnoindexのあるページにはリンクしない
しかし、rel="canonical"やnoindexの指定があるページに引き渡されたPageRankが希薄化や行き止まりによって少しでも失われることがないように、そもそもリンク自体を回避するほうがいいかもしれない。
robots.txtとnofollowは控えめに使う
robots.txtとnofollowの戦術は、極めて控えめに使っていくべきだ。
なぜなら、(紹介時にもちょっと触れたが)PageRankの行き止まりが生じてしまうからだ。
優先するURLをサイトマップに記載
最後に、少し前にオリバー・H・G・メーソン氏のブログ記事で知った最新の興味深い情報がある。同氏よると、サイトのサイトマップに、
- 新しいURL
- 最近のURL
- 最近変更したURL
だけを記載しておくと、グーグルがサイトマップを頻繁にクロールするようになるというのだ(Googlebotはすでに述べたようにそのような新鮮なコンテンツに飢えている)。
この戦術を使えば、クロールバジェットを新しいURLに割り当てられて、みんなが笑顔になれる。Googlebotはとにかく新鮮なURLを求めている。みなさんもおそらくGooglebotにはとにかく新鮮なURLを見てほしいはずだ。だとすると、そういった目的に限定したサイトマップを設置するのは、だれにとっても有効であり、手軽に実践できるうれしいやり方だろう。
今回は以上だ。みなさんに有益な話になっただろうか。新しい情報や問題点があれば、ぜひTwitterで知らせてほしい。このテーマにほかの人たちがどのように取り組んでいるのか、とても興味がある。
 クロールバジェットの基本と問題の原因")
")






必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。
デジタルマーケティングの即戦力を2日間で育てます! 第24期「企業Web担当者 初級講座」6/13・6/14【2024年6月度】
 4,867 いいね!
4,867 いいね!「第6回 Googleアナリティクス4実践講座~GA4を使いこなす! 計測設定からレポート・分析活用まで」オンライン開催
1,164 いいね!Web担 編集後記 2024年3月
441 いいね!ライオンでアドビのCMSを導入! 導入の背景や活用方法を聞いた
432 いいね!【満員御礼】「GA4祭り」をテーマにアクセス解析の専門家が集結! 3月21日(木)@渋谷【Web担当者Forum Meet UP #2】
88 いいね!生成AI「Copilot」でMicrosoft 広告はどう変わる? ―Web担編集長・四谷が根掘り葉掘り聞いてきた!
85 いいね!STUDIO導入・内製化で運用コストが40分の1に! パシフィコ横浜のWebサイトフルリニューアルの成果
82 いいね!

ソーシャルもやってます!