SEO担当者が知っておきたいJavaScriptの基本 ―― グーグルにサイトを正しく理解させるために(前編)
あなたのサイトは、グーグルに正しくクロール・インデックスされているだろうか。
2017年9月11日 7:00
今のSEO専門家にとって、JavaScriptを理解すること、そしてJavaScriptが検索パフォーマンスに与える潜在的影響を理解することは、きわめて重要なスキルだ。検索エンジンがサイトをクロールできなかったり、サイトの内容を解析して把握できなかったりすれば、ページが適切にインデックス化されず、検索順位を獲得することもない。
SEOにおいて、JavaScriptで最も重要な問題は、検索エンジンがコンテンツを確認したりウェブサイト体験をチェックしたりできるか、そして、もしできないのなら、どのような解決策を用いれば修正できるのかということだ。
基本
JavaScriptとは?
今日のウェブページは、大きく次の3つの要素で作成されている。
HTML(Hypertext Markup Language:ハイパーテキストマークアップランゲージ) ―― サイトにおけるバックボーンであり、コンテンツを構成する役割を果たす。具体的には、ウェブサイトの構造(見出し、段落、リスト要素など)を示し、静的コンテンツを定義する。
CSS(Cascading Style Sheets:カスケーディングスタイルシート) ―― デザイン、装飾、外観、スタイルをウェブサイトに与える。つまり、ページのプレゼンテーションレイヤーとして機能する。
JavaScript(ジャバスクリプト) ―― インタラクティブな動きを可能にする。ダイナミックウェブの中心的なコンポーネントだ。
詳しい情報が必要なら、ウェブページの作成についてはこちらを、JavaScriptの基本的なコーディングについてはこちらを参照してほしい。

JavaScriptは、HTMLドキュメント内に<script>要素を用いて記述する(つまり、HTMLに埋め込む)か、リンクで参照する。現在、JavaScriptのライブラリやフレームワークには、jQuery、Angular、React、Ember.jsなど数多くの種類がある。

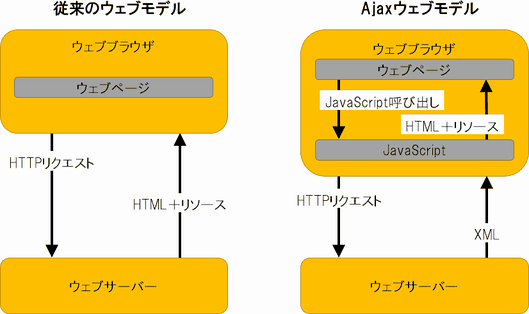
Ajaxとは?
Ajax(Asynchronous JavaScript and XML:エイジャックス)は、JavaScriptとXMLを組み合わせたウェブ開発手法で、ウェブアプリケーションが、表示中のページに干渉することなくバックグラウンドでサーバーとやりとりできるようにするものだ。
「Asynchronous」(非同期)とは、スクリプトの実行中に他の機能やコードを実行できるという意味だ。ブラウザ上では、通常のJavaScriptは1つのコードを実行し終えるまで他のコードを実行できない「同期的」な挙動をするが、Ajaxでは他のコードの実行状況に関係なくコードを実行する「非同期的」な処理が特徴だ。
「XML」はデータを渡すための主要な言語だったが、現在ではXML以外のデータ形式を使うことも多い(それでも「Ajax」という用語が使用される)。たとえば現在はJSON形式でデータの受け渡しをすることが多いが、それでも「Ajaj」(Asynchronous JavaScript and JSON)という表現は使わない。
Ajaxの一般的な用途は、ウェブページをまるごと更新しなくても、そのページの内容やレイアウトを更新できるようにすることだ。
通常、ブラウザが別のページを読み込むときには、そのページのHTMLをサーバーから取得し、さらにページから参照しているすべてのアセット(画像やCSSなど)をサーバーから取得してから、そのページ上に表示する必要がある。
しかし、Ajaxを使えば、ページ上で内容を変更するコンテンツやアセットのみを新たにサーバーから取得して表示すればいいため、ページをまるごと更新する必要がなく、ユーザー体験が向上する。
Ajaxは「小規模なサーバー呼び出し」だと考えることができる。Ajaxの優れた利用例が「Googleマップ」だ。Googleマップでは、ページ全体をリロードすることなくページが更新される(つまり、ユーザーの操作中に小規模なサーバー呼び出しが行われて、コンテンツがロードされる)。
DOM(Document Object Model:ドキュメントオブジェクトモデル)とは?
SEOの専門家であれば、DOMについて理解する必要がある。その理由は、グーグルがDOMを利用してウェブページを分析し、把握するからだ。
簡単に言えば、DOMとは、ブラウザが現在表示しているページの情報と状況だ(DOMの内容は、ブラウザの「要素の検証」機能を使って表示できる)。
ブラウザはまず、HTMLドキュメントを受信する。その後、このドキュメント内のコンテンツの解析を開始し、画像、CSS、JavaScriptファイルといった追加のリソースを取得する。
DOMは、これらの情報とリソースを解析して生成したものだ。ウェブページのHTMLや画像などすべての情報を、ブラウザが処理しやすいように構造化し整理したもの、それがDOMだと考えることができる。
今のDOMは、ダイナミックHTMLと総称される技術のために、初期のHTMLドキュメントとは大きく異なっていることが多い。ダイナミックHTMLでは、HTML、CSS、JavaScriptを使用することで、ユーザー入力や環境条件(時刻など)といった変数に応じてページの内容を変更できる。
以下は、JavaScriptを使って<title>要素の内容を記述した例だ。


ヘッドレスブラウジングとは?
ヘッドレスブラウジングとは、簡単に言えば、ユーザーインターフェイスを使わずにウェブページを取得する行為だ。これを理解することが重要なのは、グーグルが、そして最近ではBaidu(百度)が、ヘッドレスブラウジングを利用して、ユーザーの体験とウェブページのコンテンツをより正確に把握できるようにしているからだ。
PhantomJSとZombie.jsは、スクリプトベースのヘッドレスブラウザで、通常は、テストのためにウェブ上での操作を自動化するときや、(レンダリング前の)最初のリクエストのときに静的なHTMLスナップショットを表示するために使用される。
JavaScriptがSEOにとって厄介な理由は?(そして、問題を修正するには)
サイトでJavaScriptを利用するにあたっては、懸念すべき大きな問題が3つある。
クロールしやすさ: ボットがサイトをクロールできるかどうか。
取得しやすさ: ボットが情報にアクセスし、コンテンツを解析できるかどうか。
ユーザーが認識するサイト表示速度: すなわちクリティカルレンダリングパスの問題。

クロールしやすさ
これは、ボットにURLを見つけてもらい、サイトのアーキテクチャを理解してもらえるかどうかという問題だ。ここでは、次の2つの要素が重要になる。
(偶然にしても)検索エンジンがJavaScriptを取得できないようにブロックしてしまっていないか。
内部リンクは正しく設定されているかどうか。JavaScriptイベントをHTMLタグの代わりに使ったりしていないこと。
JavaScriptのブロックが非常に大きな問題になる理由は
検索エンジンは、JavaScriptをクロールできないと、サイトのすべての体験を受け取れなくなる。つまり、エンドユーザーが見ているのと同じ内容を検索エンジンが見られなくなるのだ。
なぜそれが問題なのか。その場合、検索エンジンが把握する「サイトの内容」は、サイト管理者がイメージしているものと異なるため、結果として訴求力が弱くなるためだ。また、クローキングとみなされる可能性もある(実際に悪意があれば)。
Fetch as Googleや、TechnicalSEO.comのrobots.txtおよびFetch & Renderなどのテストツールを使えば、グーグルボットがブロックされているリソースを見つけ出すのに役立つ。
この問題を解決する最も簡単な方法は、ユーザー体験を理解するのに必要なリソースに検索エンジンがアクセスできるようにすることだ。
重要!検索エンジンがアクセスできるようにすべきファイルとすべきでないファイルを判断する際は、開発チームに協力してもらうこと。
内部リンク
内部リンクでユーザーがサイト内を移動できるようにするには、JavaScriptの関数を使うのではなく、HTMLまたはDOM内で通常のアンカー要素(<a hrefs="www.example.com">という形式のHTMLタグ)を使ってリンクを設定する必要がある。
ここで重要なことは、JavaScriptのonClickイベントを内部リンクの代わりに使わないということだ。ジャンプ先のURLを(JavaScriptコード内の文字列やXMLサイトマップ経由で)ボットが見つけてクロールしてくれる可能性はあるが、サイトのグローバルナビゲーションと関連付けられることはない。
内部リンクは、サイトのアーキテクチャとページの重要性を検索エンジンに知らせる強力なシグナルだ。実際、内部リンクは非常に強力であるため、(状況によっては)URL正規化タグなどの「SEO施策」より優先されることがある。
URLの構造
これまで、JavaScriptベースのウェブサイト(「Ajaxサイト」)では、URL内でフラグメント識別子(#)が使用されていた。
しかし、検索エンジンに正しくサイトのコンテンツをクロールしてもらうには、JavaScriptがページの内容を書き換えていく際に、URL構造をどのように用いるかが重要になる。
- 使用を勧められないもの(過去はOKだった場合でも):
単独のハッシュ記号(#)
単独のハッシュ記号はクロールされない。
ハッシュ記号は、アンカーリンク(別名ジャンプリンク)の識別に利用される。アンカーリンクとは、同じページ上のコンテンツに移動するためのリンクだ。URLのハッシュ記号の後に記述した内容はサーバーに送信されず、IDが一致する最初の要素(または、ハッシュ記号の後に記述した情報の名前が書かれた最初の<a>要素)までページが自動的にスクロールされる。
AjaxサイトではURLには「#」を使用しないことをグーグルは推奨している。
ハッシュバン(#!)(および「_escaped_fragment_」形式のURL)
ハッシュバンを付けたURLは、かつてはクロールを可能にするための対策だった。しかし現在グーグルはその利用を推奨しておらず、Bingのみがサポートしている。
かなり前に、グーグルとBingが複雑なAjaxソリューションを開発した結果、サイトで利用するURL構造として、
- ユーザー体験を提供する簡潔なURL(#!)
- ボットにHTMLベースの体験を提供する「_escaped_fragment_」を使ったURL
の2種類が共存していた。しかし、グーグルはこの手法の推奨を撤回し、実際のユーザー体験をチェックするようになっている。
「_escaped_fragment_」では、次の2つのユーザー体験が提供される。
本来の体験(簡潔なURL) ―― このURLは、「#!」(ハッシュバン)をURL内に含めることで、エスケープフラグメントがあることを示すか、メタ要素を含めることで、エスケープフラグメントの存在を示す(
<meta name="fragment" content="!">)必要がある。エスケープフラグメント(冗長なURL、HTMLスナップショット) ―― 検索エンジンのロボットは、ハッシュバン(#!)を「_escaped_fragment_」に置き換えてサーバーにアクセスする。そうしたアクセスに対してはHTMLスナップショットを提供するという仕組みだった。これが冗長なURL(ugly URL)と呼ばれている理由は、文字数が多く、(意図や目的が)まるでハッキングのように見えるからだ。
- 使用を推奨するもの:
pushState History API
pushStateはJavaScriptの命令で、History API(ウェブブラウジング履歴のようなもの)の一部だ。
基本的に、pushStateはアドレスバー内のURLを更新し、そのページで変更が必要なものだけが更新されるようにする。そのため、JavaScriptサイトが「クリーン」なURLを利用できるようになる。
pushStateは現在グーグルでサポートされており、クライアントサイドまたはハイブリッドレンダリングでのブラウザナビゲーションに対応する。
 画像のソース
画像のソースpushStateの優れた利用例が無限スクロールだ(ユーザーがスクロールしていくと新しいコンテンツがAjaxで新たに読み込まれ、ブラウザのアドレスバー上でもURLが更新される)。
理想的なユーザー体験は、ユーザーがページを更新すると、まったく同じ場所が表示されるものだ。ただし、ページの更新をユーザーが行う必要はない。スクロールダウン操作によってコンテンツが更新されると、アドレスバー内でURLが更新されるからだ。
例:検索エンジンフレンドリーな無限スクロールを実装した優れた例が、グーグルのジョン・ミューラー氏が作成したもので、こちらから見ることができる。技術的に言えば、ミューラー氏はreplaceState()を利用しており、pushStateと同じようなバックボタン機能は搭載していない。
詳しくは、MozillaのpushState History APIのドキュメントを参照してほしい。

取得しやすさ
検索エンジンは、ユーザー体験とページ上のコンテンツをより正確に把握できるようにするため、ヘッドレスブラウジングを利用してDOMをレンダリングすることがわかっている。つまり、グーグルは一部のJavaScriptを処理でき、インデックスする内容の理解に(HTMLドキュメントではなく)DOMを使用しているというわけだ。
しかし同時に、検索エンジンがJavaScriptの理解に苦労しているような状況も見られる。自分のサイトやクライアントのサイトがHuluのような状況に陥ることは誰も望んでいないだろう。ボットがどのようにサイト上のコンテンツとやりとりするのかを理解しておくことは、きわめて重要だ。わからなければ、テストしよう。
検索エンジンボットがJavaScriptを実行できるものとして、検索エンジンがコンテンツを取得できるようにするための重要な要素は次のとおりだ。
ユーザーが操作を行わったら表示されるというコンテンツがあっても、検索エンジンはおそらくそのコンテンツを確認できない。
googlebotは面倒くさがりのユーザーなのだ。クリックもスクロールもログインも行わない。完全なユーザー体験を提供するのにユーザーの操作を求める場合は、ロボットも同等の体験ができるように細心の注意を払ってほしい。
JavaScriptのロードイベントが開始されてから実行されるまでに5秒以上かかると、検索エンジンはそのコンテンツを見ない可能性がある。
この「5秒」の根拠は次のとおりだ。
ジョン・ミューラー氏が述べているように、タイムアウト値が指定されているわけではないが、サイトが5秒以内にロードされるようすることを目指すべきだ。
Screaming Frogのテストによれば、Googlebotはコンテンツのレンダリングまでに待つ時間は5秒程度だということだ。
ロードイベントの開始から5秒以内という基準は、グーグルのPageSpeed Insightsやモバイルフレンドリーテスト、Fetch as Googleでも使われている。マックス・プリン氏のテストタイマーをチェックしてほしい。
JavaScript内にエラーがある場合、コード全体が実行されなければ、ブラウザと検索エンジンのどちらも動作を完了できず、ページの一部が欠けてしまうおそれがある。
SEOとJavaScriptの関係について解説するこの記事は、前後編の2回に分けてお届けする。後編となる次回は、検索エンジンにコンテンツを確実に取得してもらうための方法と、サイト表示の遅延について説明する。→後編を読む
- この記事のキーワード
関連記事
JSフレームワーク時代に必要なGooglebot分析とスクレイピングの技術(テクニカルSEOの復権全6回の3)
2017年1月30日 7:00
ページを1秒以内に表示するための最新技術、そしてSEOの未来(テクニカルSEOの復権 最終回)
2017年2月20日 7:00
イマドキのSEOでJavaScriptに関して最低限知っておきたい調査テクニック(後編)
2018年8月27日 7:00
【Google公式】英語版SEOオフィスアワーの最新TIPS特集: ページ分割・サイトマップ・title・リダイレクトなどなど【SEO情報まとめ】
2023年1月20日 7:00
グーグルに「低品質コンテンツ」評価をくらう6つのダメなUX などSEO記事まとめ10+4本
2016年1月8日 7:00
【プロなら余裕?】SEOがデキる人かどうか見極めるシンプルだけど効果的な質問【SEO情報まとめ】
2022年7月15日 7:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




