HTTP混在コンテンツはHTTPSページとして評価されなくなるかも
海外のSEO/SEM情報を日本語でピックアップ
HTTP混在コンテンツはHTTPSページとして評価されなくなるかも
ユーザー体験にはマイナスに響きそう (Google Webmaster Central office-hours)
HTTPSページの評価を上げるアルゴリズムをグーグルは導入している。現状では、HTTPSでありさえすればよくサーバー証明書の種類や強度は問われない。同様に、HTTPSの実装にミスがあったとしてもほとんどの場合は評価対象としてみなしてくれる。
しかし将来的には判断基準が厳しくなるかもしれない。
HTTPで配信するコンテンツがHTTPSページに混在する場合、HTTPSアルゴリズムによる恩恵を受けられなくなる可能性があることを、グーグルのジョン・ミューラー氏が示唆した。
ページのHTMLドキュメントをHTTPSで提供していても、そのページで使われている画像やJavaScriptなど他のリソースをHTTPで提供していると、たとえばChromeブラウザでは、HTTPSを示す鍵マークに三角の警告マークが付く。
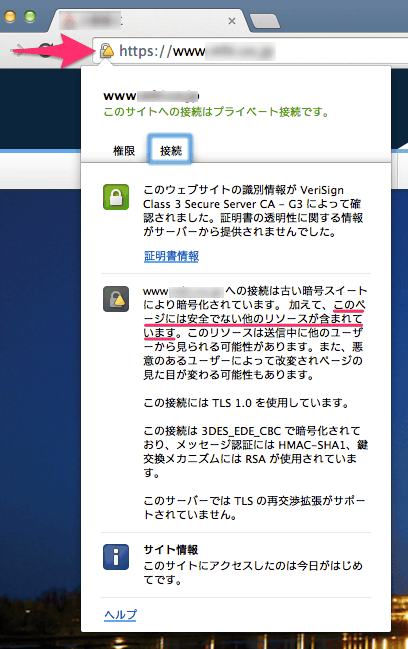
詳細を見ると、「このページには安全でない他のリソースが含まれています」という説明がある。この状態では、ページに表示されている要素のどれかが経路上で改ざんされている可能性を完全には排除できない。
たとえば、CSSが改ざんされていれば重要な情報が見えなくなっている可能性がある。もしJavaScriptが改ざんされていたら、そのJavaScriptはページ内容をどのようにでも書き換えられるため、表示されている内容のどれも完全には信頼できないということになるのだ。
ただし、混在するコンテンツのHTTPSを評価しなくなることが確定しているわけではない。ミューラー氏の個人的な見解が入っているかもしれない。
そうはいえど、せっかくHTTPSを使っているのだから、すべてのリソースにHTTPSを適用させたほうがいいに決まっている。たいていのブラウザでは警告マークが付くし、ブラウザによっては警告マークだけではなく警告メッセージがポップアップで出てくることがあるかもしれない。セキュリティやプライバシーを守るはずのHTTPSが、かえってユーザーを不安にさせてしまう。
グーグルはmeta keywordsタグを使っていません。何度も言わせないで!
でもいまだに気にかける人がいるのも事実 (Webmasters Stack Exchange)
利用している無料ブログにmeta keywordsタグを挿入する方法を、SEO系フォーラムで質問したユーザーがいた。
フォーラムメンバーの1人が、2009年にグーグルがウェブマスター向けブログに投稿した記事を提示し、グーグルはもうmeta keywordsタグをもう使っていないことを教えた。
ここで、グーグルのジョン・ミューラーが登場し次のようにコメントした。
私はグーグルのウェブ検索チームで働いているんだが、2009年のそのブログ記事はいまでも正しいことを認めたい。グーグルの視点からは、meta keywordsタグに時間を費やす必要はない。
meta keywordsタグに記述されたキーワードをグーグルがランキング要因にしていないことは、長らく知られている当たり前のことに思うかもしれない。しかし、依然としてmeta keywordsタグを気にかけるサイト管理者が存在する。そういう古い情報をどこでどうやって見つけてくるのだろうか?
Bingもmeta keywordsタグを、評価を上げる目的では使っていない(キーワード乱用のスパムを判断する材料に使っているかもしれない)。中国最大シェアのバイドゥ(Baidu)やロシア最大シェアのヤンデックス(Yandex)はひょっとしたらまだ使っているかもしれない。
meta keywordsタグの記述が無意味だとは言わない。サイト内検索システムで分類用のデータとして活用するなど、他の仕組みでは利用価値がある場合もあるからだ。また、中国やロシアのユーザーがターゲットである場合も、記述することはまったく差し支えない。
しかし、グーグル(とBing)の評価を上げるために、meta keywordsタグの作成・調整に時間をかけるのだとしたら、その価値はゼロだと言ってもいいだろう。この先グーグルがmeta keywordsタグを再び利用する可能性も、まず間違いなくゼロだ。
meta keywordsタグを使用していないことを説明した2009年の公式記事は、次のように締めくくっている。
グーグルが将来meta keywordsの情報を使うのは可能性としてはありえますが、そういうことはないでしょう。meta keywordsタグをもう数年来グーグルは無視してきました。現状ではその方針を変更する必要性を感じていません。
すべてのページがインデックスされないのは普通にあること
全ページをグーグルがインデックスするとは限らない (John Mueller on Twitter)
インデックスされるべきページがインデックスされないときに、どのページがインデックスされていないかを調べる方法はあるか?
ツイッターでこのように質問されたグーグルのジョン・ミューラー氏は、「そうした方法はないと」言い、次のコメントを付け加えた。
すべてのページを私たちは常にインデックスするとは限らない。
@webrankinfo @methode We never index all pages, so you can'f always fix that. Do you see sites with important ones missing? That'd be a bug.
— John Mueller (@JohnMu) 2015, 8月 19サイト内の全ページ数が10ページくらいのごく小さなサイトを除けば、ミューラー氏が言うように、サイト内の全ページがインデックスされないことは普通にありうる。一般的には、サイトが大規模になればなるほどインデックスされないページは増えていく傾向にあるはずだ。
サイトマップで送信したURLのうち、8~9割程度がインデックスされていれば問題ないだろう。
次に示す図は筆者のブログに関するSearch Console上のデータだが、サイトマップで送信した2,791URLのうち、2,767URLがインデックスされている。アーカイブページやカテゴリページを含めず、個別記事ページだけをサイトマップに記述しているが、それでもすべてのページはインデックスされていない。

もっとも、サイトマップで送信したURLが半分もインデックスされていないとか、重要なページが多数インデックスされていないといったような状況であれば、何らかの問題が発生していることを疑ったほうがいい。
Googlebotのクロールを高速化するためにJS/CSSをブロックできるか?
ナイスアイデアっぽいけどNG (Google Webmaster Central office-hours)
英語版のオフィスアワーで、参加者が次のように質問した。
Googlebotが速くクロールできるように、JavaScriptやCSSを隠すことはクローキングになるか? 一方でユーザーのブラウザは、そうしたJavaScriptやCSSを処理してページを表示する。
グーグルのジョン・ミューラー氏は、次のように答えた。
ああ、クローキングになる。ページを軽量化させようとして、ユーザーとGooglebotに違うものを見せたら、クローキングとしてみなされるだろう。
それにJavaScriptやCSSをブロックすると、そのページがどんなふうにユーザーに見えるのかグーグルが理解するのを妨げてしまう。だから、絶対にやめたほうがいい。
いい例がモバイルサイトだ。モバイルサイトに必要なJavaScriptやCSSを隠したら、そのページがモバイルフレンドリーだと認識できなくなる。結果として、モバイル検索で適切に評価できなくなるだろう。
一般的に言って、ユーザーとGooglebotには同じものを提供することを本当に勧める。
Googlebotのクロールを高速化するためにJavaScriptやCSSを取得させないというのは、ナイスなアイデアに思えなくもないが、デメリットのほうが大きそうだ。下手をすれば、クローキングとして手動対策の対象になってしまう。
ミューラー氏が推奨するように、コンテンツのレンダリングに必要なリソースのクロールは素直に許可しておこう。そのほうが適切に評価されメリットになる。
robots.txtに隠し機能の「Noindex」命令構文が存在した
利用は非推奨 (Eric Enge on Google+)
robots.txtでは「Disallow」で、指定したファイルやディレクトリのクロールを拒否できる。これとは別に、Googlebotに対しては「Noindex」という命令も使えることを知っていただろうか?
Noindexを指定すると、クロールは許可するが検索結果への表示を拒否できる。
User-Agent: Googlebot
Noindex: /moge/このようにrobots.txtに記述すると、/mogeディレクトリ内のファイルに関してGooglebotは、クロールするが検索結果には表示しなくなるのだ。勘のいい読者は気付いただろうが、noindex robots meta タグと同じ機能を持つ。
一見すると便利な命令のように思える。しかし、Noindexをサポートしていることをグーグルはオープンにしていない(数年前まではヘルプ記事に記載されていた)。
グーグルのジョン・ミューラー氏は、現状ではサポートしていることを認めながらも、安定性を確保できないため利用を推奨していない。今は機能するかもしれないが、いつ機能しなくなるかわからないのだ。
robots.txtでのNoindex命令構文の存在を知らなければ使うこともないだろうが、もし現在使っていたり、どこかでこの命令構文のことを聞いたりしても、使わないほうが無難だ。
検索結果に表示させたくないときは、ウェブページであればnoindex robots metaタグを使用する。画像やPDFファイルなどのmetaタグを記述できないコンテンツの場合は、X-Robots-TagのnoindexをHTTPヘッダーに含める。
 SEO Japanの
SEO Japanの
掲載記事からピックアップ
コンテンツマーケティングを指南する記事を今週はピックアップ。
- コンテンツマーケティングのはじめの一歩。
4つの優先事項を押さえる
- この記事のキーワード
関連記事
グーグル「常時HTTPSでなきゃChromeでひどい目にあわすよ、まずは1つ目の罰だ」 などSEO記事まとめ10+2本
2017年1月13日 7:00
サブドメインとサブディレクトリのSEO対決、2014年の勝者はどちら? など10+4記事
2014年8月29日 9:00
HTTPS移行のよくあるQ&A 13連発。順位は? インデックスは? 作業は? などSEO記事まとめ10+3本
2016年2月5日 7:00
スマホ版ページをnoindexにしてもスマホ検索には出る!?(スマホ対応ラベルも付く) など10+2記事
2015年7月3日 7:00
グーグルの“サイトリンク”をコントロールする方法、教えます など10+4記事
2014年9月26日 8:00
ウェブサイトは何時間ほど停止していたらSEOに悪い影響が出るのか? など10+4記事(海外&国内SEO情報)
2013年1月25日 9:00
バックナンバー
この記事の筆者

筆者の人気記事
「別タブで開く」リンク(target="_blank")は脆弱性あり?【SEO情報まとめ】
2020年3月13日 7:00
【重要】コアウェブバイタルとは? LCP/FID/CLSをわかりやすく解説【SEO情報まとめ】
2020年6月5日 7:00
新人に読ませておきたい「グーグルSEOでやったら本当にヤバいこと」【SEO記事12本まとめ】
2018年4月13日 7:00
グーグルが公式SEOチェックツールを公開【SEO記事11本まとめ】
2018年2月9日 7:00
もう待ったなし! グーグルが全サイトをMFIに強制移行へ(2020年9月予定)【SEO情報まとめ】
2020年3月27日 7:00
モバイルの「続きを読む」ボタンにグーグルの主要メンバーが不快感、将来は検索で不利になるのか?【SEO記事12本まとめ】
2017年2月10日 7:00




