リンクスパム判別は人工知能で? 機械学習での判別に挑戦したSEOマンの記録(後編)
さて、筆者が挑戦した機械学習によるリンクスパム判定ツールはうまく動いたのだろうか?
2013年8月26日 9:00
この記事は、前後編の2回に分けてお届けしていく。今回も、筆者が挑戦した機械学習によるリンクスパム判定ツールの顛末を見てみよう。
トレーニングセットについて一言
機械学習では、「解決したい問題を数値化する方法」である「モデル」が重要だ。
しかし、そのモデルを活かすも殺すもトレーニングセット次第だ。良いトレーニングセットとはすなわち、生まれたての機械学習プログラムに優秀な教師をつけることになる。悪いトレーニングセットは、落ちこぼれ先生に教えさせるようなものだ。
正確なだけでは十分ではない。トレーニングセットは、考えうる分類シナリオをくまなくカバーする必要がある。
「優良」ページが1つ、「スパム」ページが1つでは不十分だ。さまざまな可能性をちゃんと学習させるには、何百、何千というページをトレーニングセットとして与える必要がある。さもないと、機械学習プログラムはその限られた範囲のトレーニングセットから外れたアイテムを分類できず、先に進めなくなってしまう。
幸い、最初に「機械学習の基本的な概念と流れ」の3ステップ目でやった手作業による判定結果から、念入りに選ばれたスパムページと優良ページのリストができあがっている。これが僕らにとっての最初のトレーニングセットとなった。
その後で僕らは、スパム判定ツール(Is It Spam、IIS)を実行し、優良ページと悪質ページの判定結果を手作業で確認することによって、僕らは知見を深め、トレーニングセットを成長させた。
2つ目のバージョン(IIS 2.0)ではこれがうまくいった。でも、最初のバージョン(IIS 1.0)はあまりうまくいかなかった。
最初の試みは「失敗」
僕は最初のバージョンで、機械学習ツールとしてベイジアンフィルタを利用した。電子メールのスパムにはこれでうまくいくことを知っていたから、SEOスパムでも有効に違いないと思ったからだ。
だが、僕はこの時点ですでに冷静な判断力を欠いていたようだ。ベイジアンフィルタで電子メールのスパムをふるい分けるのは、野球のバットで魚釣りをするのと同程度の効果しかない。確かにスパムを捕まえられることもある。しかし同時に、多くのスパムを見逃がし、問題のないメールをスパム用フォルダに捨てて、世界中の熱心なスパマーたちを喜ばせるのが常だ。
それなのに、正気を失っていた僕は、こうしたささやかな問題のことをすっかり忘れていた。IIS 1.0は、当初うまく機能しているように思えた。最初のテストの正確さは75%だった。大したことない数字のように思えるかもしれないが、信頼できる正確なデータがあれば、リンクプロファイルのレビュー作業をとことん効率化できる可能性がある。僕はできたての機械学習ツールの父親として誇らしい気分だった。
だが、ベイジアンフィルタは「毒に冒される」ことがある。もし、スパムページの9割がウェディングに言及しているようなトレー二ングセットを与えれば、ツールはウェディング関連コンテンツをスパムとして見なし始めるだろう。それこそまさに、僕自身が経験したことだ。僕は、スパムだと思われるウェディング関係のリンクを約1万ページ分も登録してしまった(うちの会社はウェディング業界でたくさん仕事をしている)。次のテストを実行したとき、結婚にまつわるものなら何でもスパムと判断するようになり、精度は50%に落ちた。
こういったツールは、特定の業界を対象にしたサイト評価に使われることが多いので、これでは役に立たない。テストを重ねるたびにフィルタが毒されていくはずだ。膨大な数のページを使ってトレー二ングセットを構築するというアプローチだってあるかもしれないが、僕の貧弱な脳みそでは、それを扱うのに必要なインフラを考えられない。
ベイジアンフィルタだけを使用した場合、本当に問題となるのは、ページのコンテンツをチェックするという、たった1つの機能しかないことだ。リンク、ページの信頼性やオーソリティは無視されてしまう。
やれやれ。設計からやり直そう。僕は、かわいい人工知能君にカウンセリングを受けさせて、新しい脳みそをもらうことにした。
注記――僕がこの問題を理解できたのは、SEOmozのDr. Peteとマット・ピーターズ氏の協力があったおかげだ。こんな簡単なお礼では十分でない気もするが、今は謝辞だけでも述べておくべきだろう。
2回目の試みは「条件付きの成功」
2回目のテストではロジスティック回帰を使った。この機械学習モデルは、テキストではなく数値データを利用する。そのおかげで、僕はより多くの特徴を与えることができた。最初のテストを実施してみると、今回は実際それほど悪くなかった。数時間の作業で、ツールは以下のような特徴を評価できるようになった。
- ページのトラストフローとサイテーションフロー(Majestic SEOから。今はSEOmozのメトリクスを追加中)
- ワードあたりのリンク数
- フレッシュ-キンケイドアルゴリズムに基づいたページのリーダビリティー(読みやすさ)
- ページあたりの単語数
- ページあたりの音節数
- ページあたりの文字数
- ランダムに発生するように見える他の少数の要素。ページあたりの画像数、スペルミス、文法の間違いなど
今回、このツールははるかにうまく機能した。特定業界に特化したトレーニングセットを使って、85%の精度で稼働した。
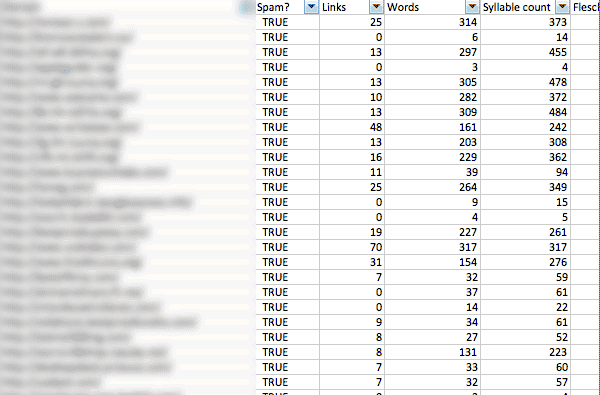
気になるという読者のために、成果を以下に示そう。
ただし、このツールを使ってさらに一般的なテストを試みたとき、僕の幼いコードは、大きく育ちすぎた足でつまずいてしまった。
笑える結果を2つ示そう。
- 自分自身をスパムだと見なした。
- SEOmozのランドのブログをスパム攻撃が渦巻くブラックホールだと見なした。
1つの業界にとどまらないトレーニングセットを作ろうとしたら、誤検知が大きな問題として残る。
がっかりだ。でも、特定の業界内だけなら有効に機能するわけだから、僕らはその目的で使い続けている。顧客ごとにトレーニングセットをカスタムメイドし、そのトレーニングセットで残りのリンクをチェックする。そうすると比較的はっきりした結果が得られる。
結果と次のステップ
幼いIISが歩けるようになったおかげで、僕らはリンクプロファイル評価にかける時間を30時間から3時間に大幅に削減できた。確かに悪くはない。
僕は、IISの公開版をリリースしかけたが、ユーザーたちは早速これを現実のリンクプロファイル評価に使い始め、しかも結果のチェックを怠った。これで僕は恐れをなし、誤検知の問題を直すまで、ツールを取り下げることにした。
僕の考えでは、分類セットに以下のような新機能を追加することで、誤検知に対処できるはずだ。
ベイジアンフィルタ
分類するのにベイジアンフィルタだけを利用するのではなく、1つの機能として利用する。
文法チェック
Pythonで文法をチェックする適切なアルゴリズムを知っている人はいないかな? もしいたら連絡してほしい。文法品質のチェックを1つの機能として加えたい。
アンカーテキスト
アンカーテキストは重要だ。次世代のツールは、アンカーテキストをベースにして、関連リンクを評価する必要がある。それは(たとえば署名記事にあるような)名前なのか? それとも(キーワードを詰め込んだリンクのような)フレーズなのか?
リンクの位置
リンクの位置も関係するかもしれない。これもまた、スパム検知の助けとなりうる一大特徴だ。反面、誤検知の増加につながる可能性もある。IISがプレスリリースの本文中にある、大量のスパムっぽいリンクを見たら、その中にある他のリンクまでスパムと判断し始めてしまうかもしれない。他の機能でこれを補完できるかどうか、テストする予定だ。
運がよければ、こうした変更を1つか2つ加えることで、複数の業界にまたがるページも評価できるツールが生まれる可能性はある。あくまでも、運がよければだが。
考察
これは、僕が今まで取り組んできた中で最も手強い開発プロジェクトだ。歯を食いしばりすぎて、たった6週間で、歯のエナメル質が10年分はすり減った気がする。とはいえ、以下のように、多くのものをもたらしてくれた。
自動ページ分析や機械学習について深く考え始めると、コンピュータによる言語の評価について多くのことが学べる。君が21世紀のマーケティング担当者なら、これは大きな意義を持つテーマだ。
僕は、グーグルによるペンギンアップデートの実装に関して、興味深いパターンを発見した。これは、機械学習を自分なりにいじった経験に基づくので、多少割り引いて考えるとしても、一度ここを見てほしい。
僕らが学んだのは、スパム的なページなど存在しないということ。存在するのはスパム的なリンクだけだ。特定のページからの1つのリンクなら、まったく問題ない。たとえば、プレスリリースページからのブランド名を使ったリンクのように。同じページからの2つ目のリンクは、スパムになる可能性がある。たとえば、同じプレスリリースから張られたキーワード満載のリンクなどだ。
僕らは、初回のリンクプロファイル評価に必要な時間を10分の1に減らした。
この作業はまた、謙虚さを学ぶよい経験にもなった。
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




