「SEOの意外な裏技」その10:robots.txtでリンクジュースの受け渡しをうっかりブロックしないために
robots.txtでdisallowするだけでは、ページはインデックスに含まれ、リンクジュースの流れを阻害する
2009年6月12日 9:00
自分のドメイン名にあるページにロボットをアクセスさせないための手段として、robots.txtを採用しているWebサイトが結構ある。確かにいいやり方だけど、僕らの元に寄せられる質問を見ていると、robots.txtを使ってグーグルやヤフー、MSNといった検索エンジンのロボットを排除するとは一体どういうことなのかってことに関して、少々誤解があるようだ。以下に、ロボットの排除方法をざっと分類してみよう。
robots.txt ―― URLへの訪問はさせないが、URL自体をインデックスに取り込んで検索結果ページ(SERP)に表示するのは許可する(よくわからない人は、下の例を見てほしい)。
メタタグ(meta要素)のnoindex ―― 訪問は許可するが、URLのインデックス化や、SERPへの表示はさせない。
nofollow属性の付いたリンク ―― 賢いやり方ではない。あるリンクにnofollowを付けても、他にnofollowの付いていないリンクがあれば、そのリンク先ページはインデックス化されてしまうからだ(ページのリンクジュースを「無駄」にしないためにこの方法を使うのならいいけど、その場合は、この方法でロボットを排除できるとか、SERPへの表示を防げるとは思わないことだ)。
以下は、robots.txtでロボットを排除しているのに、グーグルのインデックスには含まれているページの一例だ。
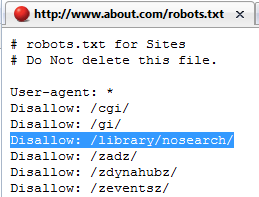
見ての通り、about.comは「/library/nosearch/」というフォルダにロボットがアクセスすることを明らかに禁じている。なのに、グーグルでこのフォルダのURLを検索すると、こんな結果が返ってくるんだ。
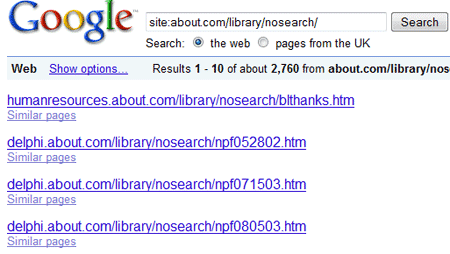
グーグルは、この「ロボット排除」を行っているディレクトリから2760件ものページを見つけ出している。これらのURLはクロールされていないわけだから、検索結果にはアドレスのみが表示される(グーグルはページの内容を見ることができないから、タイトルや説明などは付かない)。
ここで、もう一歩踏み込んで考えてみよう——検索エンジンの目に触れないようにしたページがあったとしても、それらのURLはリンクを獲得し、リンクジュースをはじめとするクエリ非依存型の順位決定要素を貯め込むことができる。でも、そこから外部へのリンクが検索エンジンの目に触れることはないんだから、これらのURLには貯め込んだものを「引き渡す」方法がないことになる。この状況を図で表すとこうだ。
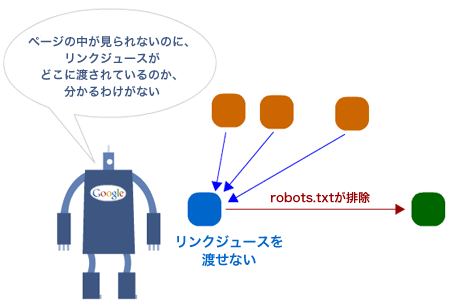
大事なのは次の2点だ。
robots.txtによってロボットを排除しているURLにリンクする場合は、nofollowを使ってリンクジュースを無駄に流さない。
ロボットを排除しているページが(特に外部リンクからの)リンクジュースを獲得していることがわかっている場合は、robots.txtではなくメタタグ(meta要素)を使って「noindex, follow」を指定し、自サイトの必要な場所にリンクジュースを渡す方法を検討する。
あるページをrobots.txtでdisallowするとクロールは禁止できるがインデックスは禁止されないため、リンクジュースの流れをコントロールしたければ、disallowしているページに対して、他の方法でインデックス自体を禁止するべきだという記事。
グーグルはrobots.txtでnoindexを指定することでインデックスを禁止できることを明らかにしているので、metaタグでnoindexを指定できない場合などは、この手法を使うのがいいだろう。
5月18日からのSMX Londonでみんなに会えるのを(それから、19日のウィルと僕のプレゼンも)楽しみにしているよ!
追伸:アンディー・ビアード氏が以前、このトピックについて「SEOのプロでも引っ掛かるリンク構築の落とし穴」という信頼できる記事を書いている。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




