“アルゴリズム”は、もっとも非人間的なものの代表だともいえる。ソーシャルメディアにとって、そのアルゴリズムが不可欠だというのは、実に皮肉めいている。
僕はこの間、グーグルがどうやってユーザーデータを集めているかについて書いた記事を掲載した(前編、後編)。今回は、著名なソーシャルメディアサイトが、ユーザーデータを活用する上でどのようにアルゴリズムを用いているのか、白日の下にさらそう。
ソーシャルメディアを成り立たせているのは人間の力だが、ユーザーが入力したデータを利用できる状態にする仕組みは、アルゴリズムによって作られている。現在活動している無数のソーシャルメディアサイトで実証済みのことだが、ユーザーの関与とアルゴリズムによる処理ルールの上手いバランスを見出すことは、とても難しくなりがちだ。これから紹介するアルゴリズムは、悪意のないユーザーと結びついて初めてうまくいくものだ。
人気ソーシャルメディアのアルゴリズム
Y CombinatorのHacker Newsの場合
公式:
(p - 1) / (t + 2)^1.5
解説:
投票数を経過時間因子で除算。
pはユーザーからの投票数(ポイント)。
tは投稿から経過した時間(単位は時間)。
投稿者自身の投票を無効にするため、pから1を引く。
経過時間因子は(投稿から経過した時間 + 2時間)の1.5乗とする。
Redditの場合
公式:
- 記事の投稿時刻をA、2005年12月8日午前7時46分43秒をBとし、その差tsを秒単位で求める。
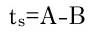
- 支持票Uと反支持票Dの差をxとする。
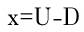
- 次の条件によりyの値を-1、0、1のいずれかとする。
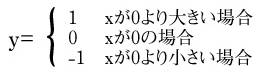
- xの絶対値(|x|)と1のうち、大きい方をzとする。
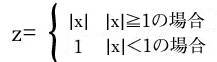
- 次の関数f(ts,y,z)の値を計算し、順位を決定する。
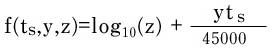
解説:
まず、2005年12月8日午前7時46分43秒という時刻は、記事が投稿されてからの経過時間を相対的に定めるための定数だ(サイトを立ち上げた時刻らしいけど、確かめようがなかった)。記事の投稿時刻からこの定数を引いた値がtsだ。tsは記事をトップページから引き下ろす力として働く。
yは支持票と反支持票のバランスを示す。
45000は12.5時間を秒に直した定数で、ytsと組み合わせることにより、記事が投稿されてから時間が経つほど得票の影響力が減じる。
log10も得票の重み付けを行うもので、後から得た得票よりも初めの方に得た得票を重く扱う。この場合、最初に得た得票10件は、11件目から101件目の得票の合計と同じ重みを持つ。
出典:code.reddit.com、Redflavor.comおよびHacker NewsのユーザーAneesh氏。
StumbleUponの場合
公式:
(
÷
そのユーザーがそのドメイン名にStumbleで訪れた回数
(
÷
そのユーザーがそのドメイン名にStumbleで訪れた回数
+
オーガニックボーナス
-
知り合いからのプラス評価
(
+
オーガニックボーナス
N
解説:
オーディエンススコアとは、StumbleUponユーザーそれぞれがもっている点数(力)で、ファンの数や評価の数などによって計算される。
最初にそのページを評価したユーザーの「力」(最初に該当ページを見た人のオーディエンススコアを、そのユーザーがそのドメイン名をStumbleした回数で割ったもの)が、その後に続くStumbleユーザーの力の合計に加わる。
その他のユーザーの力は、プラス評価したユーザーとマイナス評価したユーザーそれぞれについて、最初のユーザーよりも少ない割合で加算または減算されていく。オーガニックボーナスとは、StumbleUponのツールバーを使用して“たまたま”そのページを訪問して評価した場合に与えられる既定のボーナスだ。
公式の末尾にあるNは、「セーフティ変数」だ。上記の推定アルゴリズムに柔軟性を持たせる。値は乱数で決定する。
出典: Venture Skills Blogのティム・ナッシュ氏。もっと詳しい情報についてはこのブログを見てほしい。
Del.icio.usの場合
公式:
ポイント = (直近3600秒の間に該当の記事がブックマークされた回数)
解説:
Del.icio.usの「Popular」ページにおけるランクは、ポイントの大小で決まる。そのポイントとは、直近1時間(3600秒)にブックマークされた回数だ。この回数が多いほど、ポイントも高い。各ブックマークは1ポイントとして加算される。
出典: Del.icio.usのPopularページに関する僕自身の長期的観察に基づく。
アルゴリズムは悪用させない(Digg.comの場合)
Diggの場合は少し様相が異なる。ここまで説明してきたサイトに比べ、Diggは透明性に欠ける。裏をかかれるのを恐れていて、そのためアルゴリズムを秘密裏に開発した。中身はどうやら競合サイトよりもずっと複雑らしい。
少なくとも、Diggのアルゴリズムには次の要素を考慮していると思う。
- 投稿時間
- 投稿カテゴリ
- 投稿者のDiggにおけるオーソリティ
- 投稿者のウェブサイト全体における活動
- 投稿者の友人とファン
- 後続Diggユーザーのオーソリティ
- 後続Diggユーザーの友人とファン
- 後続Diggユーザーの地理的位置情報
- 後続DiggユーザーのHTTP参照元
ソーシャルメディアに関する専門家の方々の意見を聞きたい。この記事の内容をもっと良くするには、どうすればいいのかアドバイスが頂ければと思う。個人的に僕に連絡を取りたい場合は、電子メールか、Linkedinか、Twitterを通じて、いつでもどうぞ。それではまた。
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




