謎だらけのSEOテクニカル問題を解決する8つのポイントとは? 【前編】あなたのページがなぜインデックスされないかを把握しよう
あなたのサイト、グーグルが正しくクローリングできていないかも? まずはチェックリストで原因を探ろう
2018年10月22日 7:00
この記事は、SEOのテクニカルな問題をどう解決するか、その具体的な手法を8つのチェックポイントとして前中後編の3回に分けてお届けする。今回は、8つのチェックポイントのうち3つを解決する。
SEOではときに、普段ならあまり目にしないような問題が舞い込んでくることがある。そう簡単には答えが出ない問題だ。頭をひねって考えてみても、何も出てこない。
そういった問題は、少々のキーワード調査や基本的な技術設定をしてみたところで解決できるものではない。これはテクニカルSEOの問題であり、未知の領域にはまり込んでしまう問題なのだ。
まさにそうした性質から、こうした状況とチェックリストは相容れないものだが、飛行機に乗ったときと同じ理由で、チェックリストはあると便利だ。どんなに用心深い人でも物事を忘れてしまうことはあるし、チェックリストがあれば、どこを探ればいいのかが分かる。
不可解なSEO問題の例をいくつか見てみたいだろうか? 以下に、読み進めながらよく考えてみてほしい例を4つ挙げる。この記事の最終回で回答を示そう。
SEOでどうしても腑に落ちない問題、ありませんか?
ページには、サーバーでレンダリングされる製品マークアップが表示されていたほか、Feefo*の製品マークアップも表示されており、これにはクライアントサイドで付加される評価が含まれる。
* Feefo: 消費者の評価・レビューを企業へ提供するサービス。
Feefoの評価スニペットは、Fetch and Renderのほか、Mobile-Friendly Testツールでも正常にレンダリングされた。
レンダリングされたDOMを構造化データのテストツールにかけると、両方の構造化データがエラーなく表示された。
クライアントと競合他社のレビューページはすべて、グーグル上で評価付きのリッチスニペットを獲得していた。
競合他社はすべてBing上で評価付きのリッチスニペットを獲得していたが、クライアントにはなかった。
レビューページは、グーグルの構造化データテストツール上で正しく検証できるratingスキーマを備えていたが、Bing上では見当たらなかった。
クライアント向けの大規模なテンプレート全体で、head要素内にサーバーサイドでレンダリングされるnoindexタグを含むページがグーグルによってインデックス化されていた。
ウェブサイトはランダムに302エラーを返していた。
これはブラウザではまったく起こらず、クローラーでのみ起こった。
ユーザーエージェントを変えても違いはなく、ロケーションやクッキーを変えても違いは見られなかった。
SEOテクニカルの問題を解決するための8つのチェック項目
こういったSEOのテクニカルな問題を解決するための、8つのチェックポイントをリストにまとめた。
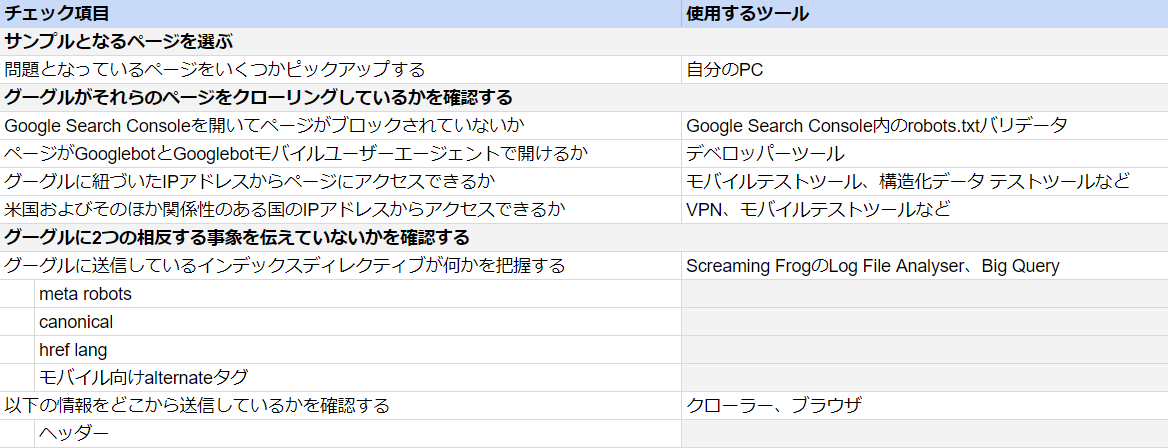
この画像はチェックリストの一部である。以下リンクから、チェックリストのテンプレートをダウンロードできる(Googleスプレッドシートのコピーを作成すること)。
このチェックリストにあるいくつかの項目は、必ずしもすべてのシナリオに当てはまるわけではないので安心してほしい。というのも、このチェックリストの目的はチェックできるすべての項目を挙げることであって、チェックすべきすべての項目を挙げることではないからだ。
チェックリストの事前チェック
チェックリストを使用する前に、あなたの抱えているSEOの問題について少しだけ考えてみてほしい。
それは本当に重要なことか?
その問題は、ほんのわずかなトラフィックに影響するだけだろうか? ほんの一握りのページに影響があるだけで、すでにウェブサイトに役立つ他の対応を数多く列挙したリストがあるだろうか? それなら、ここでやめておいた方がいいだろう。
こんなところでやめたくないのは僕だって同じだ。正しいことをしたいとも思うし、問題を深く掘り下げたい。しかし半年後、SEOに関する20の複雑な未知の問題を解決しておきながら、title要素を書き直さなかったためにウェブサイトに変化がなかったなら、どのみち解雇されるのだ。
ただ、そういう状況ではないことを願う。その場合は、先に進もう!
どこに問題が生じているか?
膨大な時間を無駄にしたくはない。この素晴らしい格言を聞いたことがあるだろうか? それは、『ひづめの音が聞こえたら、シマウマではなく「馬」と思え』(余計な想像をめぐらせず、最も一般的な原因を探せ)というのものだ。
僕たちが進めようとしているプロセスはかなり複雑なので、先に進みたいかどうかは、完全に個々の判断に委ねられている。ただ、問題を解決できるであろう明らかな要因を見落とさないようにしてほしい。以下では、僕が遭遇したよくある問題で、そのほとんどが「馬」だったものをいくつか挙げる。
- 本来あるべき水準よりパフォーマンスが低い。
サイトのパフォーマンスが低いと、人はすぐに言い訳を探したがる。グーグルの不可解でばかげた取り組みは責任をかぶせるのに好都合だ。だが実際には、お粗末なサイトや、競争の激化、ブランドの失敗が重なった結果である場合が多い。これは「馬」だ。 - トラフィックが急減した。
何かが起こったのは確かだが、おそらくこのチェックリストの出番ではないだろう。そうした問題には、基本的なチェックリストがたくさんある。それについてはトラフィック減少の診断について記事を書いたので、まずはチェックしてみてほしい。 - 間違ったクエリに対して、間違ったページが検索結果に表示される。
僕の経験では(と、おそらくこの記事全体の冒頭に書いておくべきだったが)、これは通常、サイトのターゲティングが貧弱だったり、カニバリゼーションが顕著だったりする場合の基本的な問題だ。おそらく「馬」だろう。
より複雑な問題である可能性が高く、デバッグに取りかかる必要があるケースには、次のような要因がある。
- クライアントサイドのJavaScriptを多く含むウェブサイト。
- レガシーリソースが多い、大規模で古いウェブサイト。
- グーグルの新しいサービスや機能に関連しており、コミュニティでの情報が少ない問題。
こういう問題が発生していなければ、早速チェックリストの項目に従って進めてみよう。
① いくつかサンプルページを選ぶ。
作業するサンプルページをいくつか選ぼう。どんな問題が生じているかにかかわらず、その問題が現れているページだ。いや、これは代表的なページとはならないが、それについては後述する。
もちろん、ほんのわずかなページにしか影響がなければ、実際には代表的なページになるかもしれないが、それはそれで問題ない。その問題が重要なのは確かなはずだ。上述のステップを飛ばしていないと考えていいだろうか? よし、それでは次に進もう。
② グーグルはそのページを1度でもクロールできるかを確認する
まず、Googlebotがページにアクセスできるかどうかをチェックする。これは200ステータスコードとして定義する。
よく見られる問題があれば明らかにするため、次の4通りの方法でチェックする。
- Search Consoleを開いてrobots.txtバリデータで確認する。
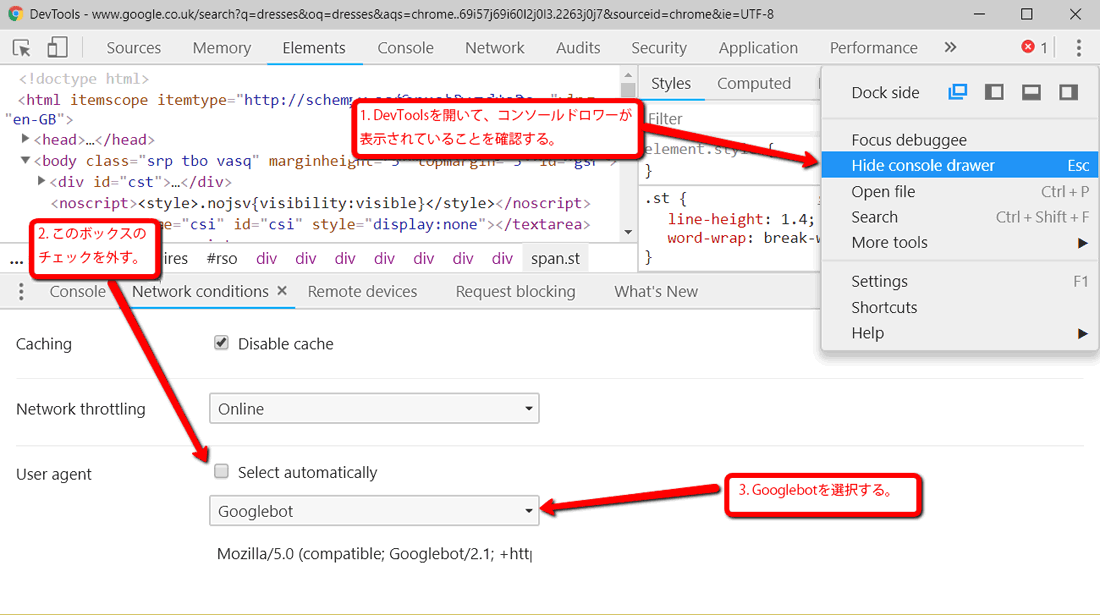
- デベロッパーツールを開き、GooglebotとGooglebot Mobileの両方でURLを開けることを確認する。
- ユーザーエージェントスイッチャーを入手するには、デベロッパーツールを開く。
- コンソールドロワーが開いていることを確認する(Escキーで切り替える)。
- 「...」をクリックして「Network conditions」(ネットワーク条件)を開く。
- ここでユーザーエージェントを選択!
- モバイルテストツールでページにアクセスできることを確認する(これはグーグルが利用しているいずれかのIPアドレスから取得される。自分のコンピュータで確認しても取得できない)。
- モバイルテストツールは、僕の見たところ米国のIPアドレスからアクセスするので、筆者にとっては一石二鳥だ。ただし、Googlebotは米国以外のIPアドレスからクロールすることもあるので、VPNを利用して、関連する他の国からサイトにアクセスできるかどうか二重に確認してみるのも有効だ。
僕は以前、これにHide My Ass!を利用したことがあるが、どのVPNでもうまくいく。
これで、Googlebotがページを1度でもフェッチすることに苦労しているかどうか、分かるようになるはずだ。
この時点で問題は見つかったか?
クロールの失敗を上記の簡単なチェックで再現できる場合は、Googlebotがページのフェッチに繰り返し失敗している可能性が高く、それが基本的な理由の1つである場合が多い。
ただ、そうでない可能性もある。テクノロジの性質上、多くの問題は矛盾しているものなのだ。
③ グーグルに2つの相反することを伝えていないか?
グーグルがページを見つけられるとしても、そのグーグルに2つの相反することを伝えることで混乱させてはいないだろうか?
僕の経験で言うと、この問題が特によく見られるのは、誰かがインデックスのディレクティブをめちゃくちゃにした場合だ。
ここでいう「インデックスのディレクティブ」とは、正しいインデックスステータスまたは検索結果に表示するべきインデックス内のページを定義するすべてのタグのことだ。以下に、そのほんの一部を挙げる。
- noindex
- canonical
- モバイル向けalternateタグ
- AMP向けalternateタグ
混乱したメッセージを伝えることになる例は、以下のようなものだ。
- ページAにnoindexを指定する
- ページBでページAを正規URLに指定する
あるいは、次のような場合もある。
- ページAのhead要素内では、ページAのURL(パラメータあり)を正規URLとして指定している
- ページAのbody要素内に、ページAのURL(パラメータなし)へを正規URLとして指定している
混乱したメッセージを伝えている場合、グーグルがどう対応するかは分からない。これが大きな要因となって、不可解な結果を目にするようになる。
上に挙げたようなインデックスのディレクティブがあるかどうかは、次のような場所をチェックするといい。
- サイトマップ
例:モバイル向けalternateタグはサイトマップに設置できる。 - HTTPヘッダー
例:canonicalおよびmeta robotsはヘッダーで設定できる。 - HTMLのhead要素
ここはすでにチェックしているだろうが、比較のために必要になる。 - JavaScriptでレンダリングされるディレクティブとハードコーディングされたディレクティブ
ページのソース内である設定をしていながら、JavaScriptでは別の設定をしている可能性がある。つまり、HTMLソース内に、レンダリングされたDOMとは異なる内容があるということだ。 - Google Search Consoleの設定
ページ上のインデックスタグと矛盾するパラメータや国別のローカリゼーションを無視するSearch Console設定がある。
レンダリングされるDOMについて、ちょっとした余談
この記事では、レンダリングされるDOMについて何度も言及している(気になる人のために明かすと、18回だ)。ここでは初めての言及となるため、その意味について軽くおさらいしておこう。
ウェブページを読み込む際、最初のリクエストはHTMLだ。このウェブページを右クリックして「ページのソースを表示する」をクリックすると表示されるHTMLがそうだ。
その後で初めて、JavaScriptによる指示があればページにされる。以前はあまり気にする必要もなかったが、今では多くのウェブサイトがJavaScriptを多用しているため、当然ながらほとんどの人が最初のHTMLを信用しようとしない。
レンダリングされたDOMとは、すべてのJavaScriptがレンダリングされ、すべてのページへの変更が行われたときのページを表す専門用語だ。これはデベロッパーツールで確認できる。
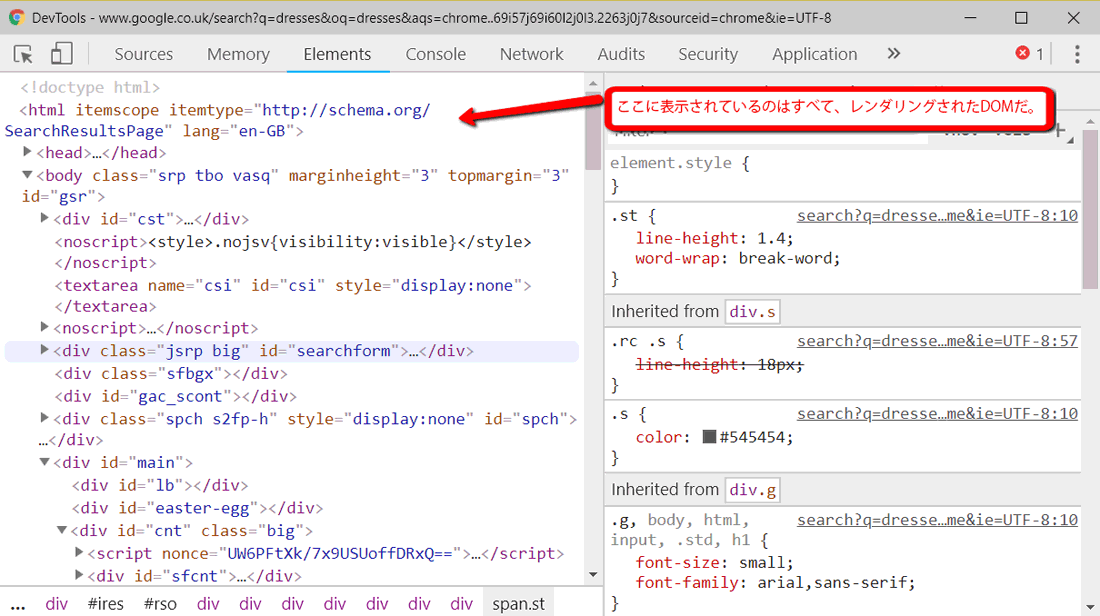
Chromeでは、右クリックして「検証」を選択する(あるいはCtrl+Shift+Iを押す)と確認できる。「Elements」(要素)タブに、レンダリング中のDOMが表示される。画面のちらつきがなくなったら、レンダリング済みのDOMが得られる。
この記事は、前中後編の3回に分けてお届けする。今回は、8つのチェックポイントのうち3つを説明した。中編となる次回は、4つ目から6つ目までのチェックポイントを見ていく。謎だらけのSEOテクニカル問題を解決する8つのポイントとは? 【中編】グーグルは正しくクローリングできている?
- この記事のキーワード
関連記事
謎だらけのSEOテクニカル問題を解決する8つのポイントとは? 【中編】グーグルは正しくクローリングできている?
2018年10月29日 7:00
SEO監査に有効な「Googlebotブラウザ」の必要性(前編)
2025年4月7日 7:00
「新R25」がSEO業界で類をみない英断! コンテンツシンジケーションのあるべき姿とは?【SEO記事13本まとめ】
2018年6月1日 7:00
ECサイトで商品詳細ページがインデックスされないときの対処方法【SEO情報まとめ】
2025年2月21日 7:00
CMS移行で検索ビジビリティが22%低下、原因はcookieの同意フォームだった!?
2022年9月12日 7:00
SEO担当者が知っておきたいJavaScriptの基本 ―― グーグルにサイトを正しく理解させるために(後編)
2017年9月25日 7:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




