マーケティングで利用するために知っておくべき人工知能(AI)の基礎知識
AIの種類と生い立ちから可能性を知る
2017年1月5日 7:00
可能性ばかりが語られる人工知能(AI)だが、本当にできることは限られている。マーケティングで利用するためには、人工知能がどういうものかを正確に理解する必要がある。

理工学部 情報科学科 教授 高木 友博氏
「Web担当者フォーラム2016秋」では明治大学の高木教授が、「人工知能の虚空と現実 ― マーケティングで本当に使うために人工知能を正しく理解する ―」と題して、探索木、エキスパートシステム、データドリブンな知能実現など、まず知っておくべき人工知能の基礎を解説した。また、マーケティングで機械学習を活用すれば、 人の思い込みを越えることなどAIの実践面も紹介した。
「人工知能は何でもできる」は誤解
人工知能は今まさにブームである。科学雑誌だけではなく、ビジネス雑誌でも特集されることがある。しかし、中身は次のようだと高木教授は言う。
とんでもないことがたくさん書いてある
映画のようにロボットが反乱を起こして人を支配するようなことは当面はあり得ないし、「人工知能は何でもできる」と過剰に期待すると失敗する。そこで、マーケティングに人工知能を使うという話の前に、そもそも人工知能とはどのように生まれ、発展してきたのかを紹介した。
人工知能の歴史 1探索木(サーチツリー)
――可能な選択肢のツリーから成功のパスを探す
人工知能の創生期に研究されていたのが、初期状態から可能な選択肢を遷移してゴールの状態までのパスを探す、「探索木」の考え方だ。取り得る選択肢を繋いだかたちがツリー構造になるが、このすべてのルートをサーチスペースといい、その中から成功のパスを「探索」する。これは、チェスや将棋のようなボードゲームを進める考え方と同じなので、人工知能の研究はゲームの研究という時代があった。
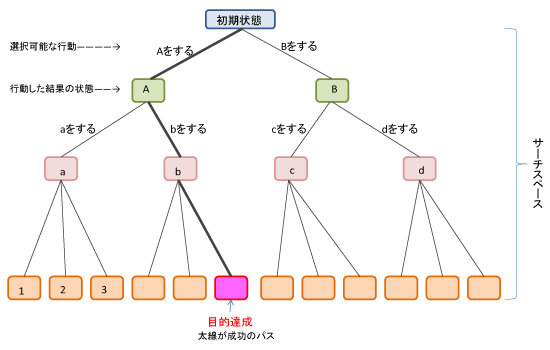
サーチスペースが広ければ広いほど(選択肢が多いほど)探索は難しくなるが、コンピュータの計算パワーが進むことで解決される。今では、計算パワーが人間の能力を上回ったため、碁の世界チャンピオンに勝つ「AlphaGO」のようなプログラムが登場した(碁のサーチスペースはチェスや将棋よりも広い)。
人工知能の歴史 2エキスパートシステム
――知識と論理を用いた推論
探索木では解決できない問題のために考えられたのが「エキスパートシステム」で、「知識べース」と「論理で推論するエンジン(推論機構)」で問題を解決する。背後で動作するのは「プロダクションシステム」という。
医療診断を例にすると、医師など専門家の知識を溜めて、知識べースを作る。知識ベースの中身は、「症状Aであれば病名B」のようなルールである。そして患者の症状を推論機構に入力すると、「○△%の確率で、病名□○」というように出力される仕組みだ。
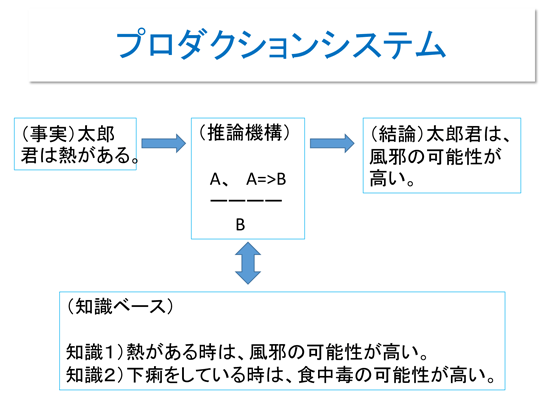
ここで核になるのは、
- 知識を投入する
- それを論理で推論したり問題解決する
の2つだが、論理だけでは解決できない問題がある。ひとつは「矛盾」で、文章の内容に矛盾があっても、人間ならそれを乗り越えるが、論理は破綻する。

もうひとつは「グラウンディング問題」で、これは論理モデルが現実世界と結びつけられないことをいう。たとえば、実際には選択肢が無限にあって選択肢のツリーが描けないというのもこれに当たる。
図のような「猿がどのようにすればバナナを取れるか?」と言う問題では、一見「バナナの下に箱を持っていき、その上に乗ればバナナをとることができる。」と解が求められるようにみえるが、「バナナの下」といっても箱には無限の置き方があり、うまくおかないとバナナを取れないこともあり得る。
つまり論理的には問題のない「バナナの下」という表現が実世界とつながっていないため、実際には問題を解いていない。碁では盤上の交点にしか石を置けないので選択肢は有限だが、もしどこに置いてもいいなら選択肢は無限で、探索木では解けなくなる。現実の陣取り合戦だったら、選択肢が無限で探索木では解決できないということだ。

人工知能の歴史 3データドリブンな知能実現
――大量データを検索し、統計的に判断
論理的アプローチの限界に困っていたところ、WWW(World Wide Web)が登場した。この頃から、人工知能研究は、データドリブンな検索的アプローチになっていく。
この好例として、マサチューセッツ工科大学(MIT)の質問応答システム「START(The START Natural Language Question Answering System)」がある。これは、質問されたら機械がインターネットに探しに行くというものだ。
たとえば質問窓に「What is the capital of Japan ?」と入力すると、STARTはネット上にある「○○ is the capital of Japan.」という記述をたくさん見つけてきて、○○に当てはまるのは「Tokyo」であると判断し、解答する。
従来の方法と大きく違うのは、知識を構造化しておかないことだ。論理的アプローチでは、知識を構造化して蓄え、それを元に論理的推論を行った。しかし質問応答システムは知識を整理せず、実世界に存在するたくさんの文の中で、最も頻度の高い物を解答とする。このような手法の利点は、実世界とつながり、実用可能な知能システムが生まれたことだ。
STARTではインターネット上のWebデータを検索しているが、これは「出版されているすべての辞書の記述から」でも、「2010年から2015年のA新聞の記事から」でもいい。大量の文章の中から、真偽は考慮せず、頻度の高いものを解答として出す、「確率を最大化する」というロジックで動いている。
真偽を考慮しないというのは、わざとおかしな文章を検索してみるとわかる。「ヨドバシカメラで働いているラクダ」と書いてあったら、人間なら「おかしい、どこか間違っているのでは」と思うが、検索エンジンでは採用情報が出てくる。これは真偽でいえば偽だ。
つまり、このようなデータドリブンなシステムは、人工知能の本質に迫ったものではなく、コンピュータが確率的に最大となる置き換えを見つけているだけなのだ。これが現在のデータドリブンな人工知能の課題であり、このままでは本当の知能は実現できないことを知っておかなければならない。
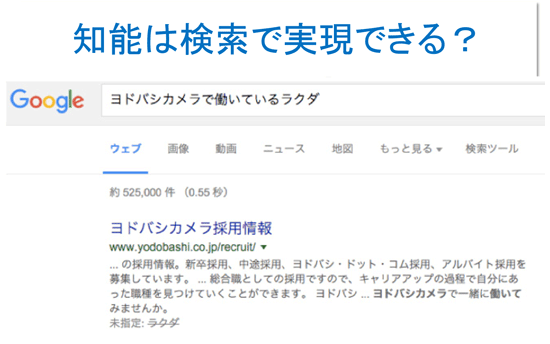
データドリブンな人工知能の実用と限界
最近ブームになっているデータドリブンな手法は、「機械学習」と「ディープラーニング」だ。
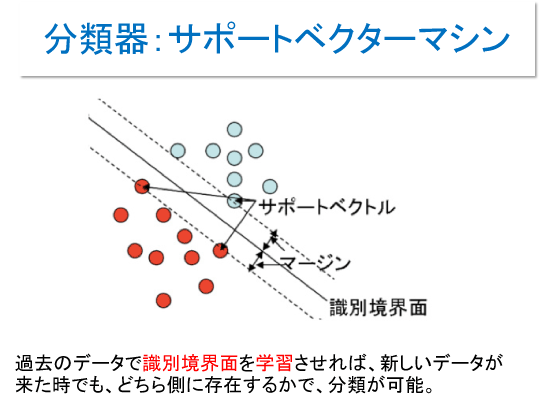
機械学習の本質とは、特徴の異なるグループの境界面を決め分類する事といって良い。
新しいデータが出てきたときに、どちら側かすぐわかるし、データが多いほど境界面は正しくひける。たとえば、「買ってくれそうなお客と買ってくれないお客の境界面」がわかれば、新しいお客がどちらかわかるというようにだ。
「決定木」も同様に動いており、顧客のセグメンテーションの際などに、分類性能が高くなるように分けていく。たとえば図の例では、背の高さで分ける方が、体重の重さで分けるよりも分類性能が高い(背の高さで分けると、○のグループと×のグループに分別できる)。このように、「どう分ければいいのか」を見つけるのが決定木だ。

クラスタリングも同様に、グループ分けを自動的に行うものだ。
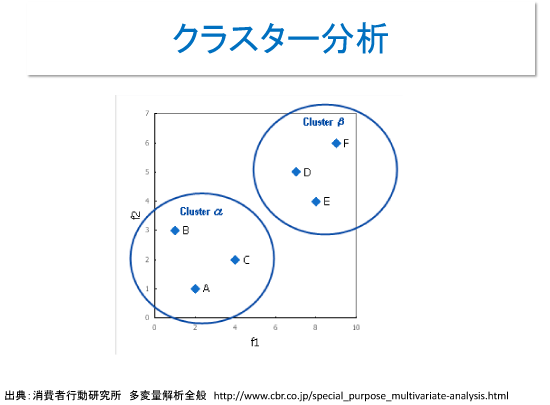
さて、機械学習による分類の話をいくつか紹介してきたが、実は機械学習にできるのは分類問題だけと言って良く、問題を解くような試行錯誤をともなう複雑な問題解決はできない。これまで紹介して来た人工知能の全体像から見れば、機械学習は人工知能そのものではなく、人工知能の一部に過ぎない。
また、機械学習は人工知能の一部だが、統計解析分野の多変量解析と重なる部分が多いため、統計解析も人工知能の一部であるかのように誤解されていることがある。しかしこれらは、異なる分野の、生い立ちの違うものである。
一方、「ディープラーニング」は「ニューラルネットワーク」である。つまり、脳の神経細胞を模している。神経回路の結線の強さを模倣したモデルを作り、重みを調整することによって脳の学習や判断の真似をする(人間が学習するのと同じように、何度も「これは××である」と反復すると、重みが強くなる)。
入力ノードと出力ノードの間に中間層を入れ、多段にしたのが人工の「ニューラルネットワーク」で、この層を深くしたのが「ディープラーニング」である。何がすごいかというと、認識のための特徴量を、あらかじめ人間が指定しなくていいという点だ。
従来なら、特徴として認識するのは何の情報か(たとえば色や形など)を人間が指定しなければならなかった。しかしディープラーニングでは、入力データを加工して、適切な特徴量をディープラーニング自身が見つける。
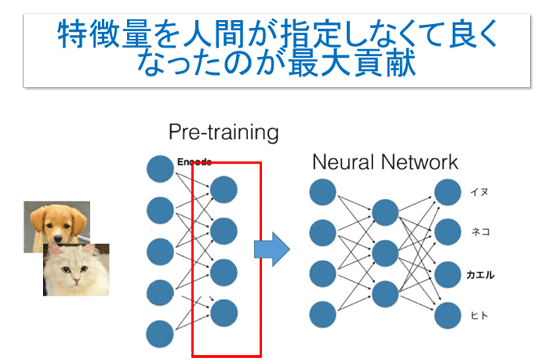
しかしこの構造では、画像を認識する程度の低レベルの処理しかできないし、一方通行の処理なので、次のような複雑な判断には使えない。
- 試行錯誤
- 問題解決
- 常識が必要なもの
現状での結論としては、現時点で実現できている人工知能と、映画の世界には、図のような隔たりがある。
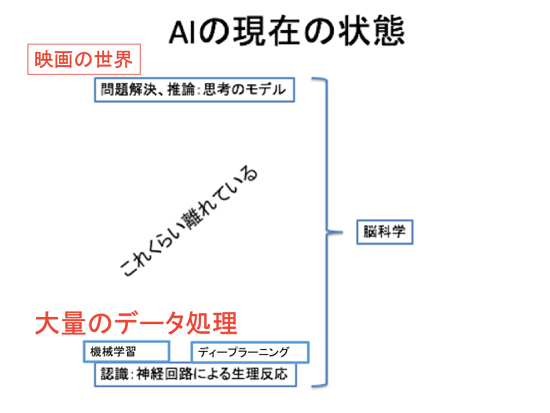
つまり、現在の機械学習やディープラーニングは、できることは知能が持つ能力全体からみると非常に限られるので、過度な期待をせず、向いている部分で使っていくのがいいだろう。人工知能を作り出す要素として「探索」「論理」「データドリブン」は非常に重要だが、いずれも一部に過ぎない。どれかひとつだけでは人工知能は実現できない。また、3つあっても、現状では人間のような高度な知能は実現できない。
マーケティングへの応用
さまざまな人工知能の手法のなかで、確実にマーケティングに利用できるのは、機械学習やその発展形だ。
高木教授が簡単な実験結果を紹介した。楽天の購買データを元に、デモグラデータを使ったセグメンテーションと、機械学習によるセグメンテーションで、どちらの分別性能がいいかを比較したものだ。
機械学習では、商品説明文から商品の特徴を示す言葉を抽出して、数値化したものを「商品の特徴」データとしてもち、顧客が購買した商品の特性の平均値をその顧客の特性とする(言葉を数値化しているので平均値を出せる)。そして、その特性から、決定木を使ってセグメンテーションしてみた。
実験の結果、決定木(属性選択)によるセグメントのほうが、デモグラ(男女や年齢)で分けたセグメントよりも、高額購買者・低額購買者の分別能力が高かった。

これが意味するのは、機械学習は顧客を最適に特徴付ける属性を数理的に求めてセグメント化しているが、人間がデモグラでセグメント化するときは思い込みに引っ張られている可能性があり、最適性は保証されないということだ。高木教授は次のように言う。
人は馴染みのあるものを好むためデモグラがよく使われるが、その効果は疑問
そもそも、何を売るか(商品特性)抜きで、最初にセグメントを決めることはできない。また、人手で可視化できるのは2属性程度までだが、二次元で試行錯誤したところで、最適化は難しい。しかし、機械ならば高次元での処理も可能となる。実験では、二十次元での最適ポジションと最適セグメントを求めることができたが、さらに高次元になっても、同様に計算可能である。
このように機械学習は、クラシフィケーション、フィルタリングなど、様々な場面で人の能力をはるかに超える性能を発揮する。フィルタリングではスパムフィルターが有名だが、優良顧客の抽出など、発想次第でさまざまなことに使える。
デジタル化が進むと、大量のデータが生まれてリアルタイム処理が求められる。IoTはこれに拍車をかけるだろう。この超多次元の世界で、人が二次元の視野で試行錯誤しても、最適化は不可能だ。そこで、マーケターのスキルを、人工知能で実現する必要がある。
その時の心構えとして、誤った方向性の期待をせず、人工知能を正しく理解し、自社の課題解決にどのレベルを活用するかを見極めなければならない。機械学習を単純に使うレベルであれば既に実用可能だ。また、今日の話のように機械学習は人工知能を実現する一部に過ぎないことを意識して、それに工夫を加えることで、より能力の高い知能を作り出す事も可能だ。それ以上のレベルに取り組むのであれば、専門のR&Dチームチームが必要となるだろう。
\ 【参加無料】2026年8月27日(木)開催 /

関連記事
生成AIは「鉄腕アトム」になれるのか? 東大・東工大教授が語るAI研究の最先端
2024年1月11日 7:00
AIとMAを活用したデジタルマーケティング基盤構築で重要な4つの秘訣とは
2018年3月28日 7:00
意思決定の精度を高めるためのビッグデータ活用、データで導く施策の成否
2014年6月4日 10:00
未来のマーケティングは“AI”によってどう変わるのか?
2021年11月10日 7:00
ChatGPTのプロンプトで使える回答を引き出す“7R”とは マーケター必須スキルとAI最前線
2023年10月18日 7:00
AIでリスティング広告はどう変わる? 媒体社と広告代理店がすべきこと
2017年2月27日 7:00
バックナンバー
この記事の筆者
筆者の人気記事
Webサイト全体HTTPS化(常時SSL)の流れはもう止まらない
2016年2月1日 7:00
ホームページ・ビルダー17でWordPressサイトはどこまで作り込める? 制作会社の仕事は奪われる?
2012年10月5日 12:00
インバウンドマーケティングの本当の姿とは、高広伯彦氏が15の疑問とともに語る
2014年1月8日 9:00
要件定義とは? Webサイトリニューアル成功のカギを握る「要件定義」の目的と作り方を紹介
2019年3月20日 7:00
ユーザーの検索意図を狙うSEOの最新動向を住氏が解説! 売れるサイトにするための4つのポイントとは?
2019年1月16日 7:00
GoogleのHTTPSサイト優遇方針で待ったなし! Webサイト常時SSL化の効果と実装ポイント
2016年6月22日 7:00




