急増するGAのリファラースパムを撃退! スパム業者の手口とは?
昨今急増するリファラ―スパムの仕組みと対策を解説する。実はMeasurement Protocolが関係している。
2016年4月21日 7:00

ここでは、昨今急増している「リファラースパム」の実態とその対策についてお話ししよう。「Measurement Protocolと一体何の関係があるの?」と思うかもしれないが、筆者はGoogleアナリティクスのデータにゴミが急増している背景は、このMeasurement Protocolの仕組みにあると確信している。
2015年から急増している「リファラースパム」とは?
まず「リファラースパム」とは何なのかを簡単に説明しておこう。外部のサイトからリンクによって計測対象サイトへ移動してきた場合に、参照元(リファラー)情報が取得できる仕組みになっているのはご存じだろう。
アクセス解析をしていれば、どんなページからのリンクで自分のサイトへ来訪したのかを確認するために、その参照元のページを確認しにいくだろう。そうしたサイト運営者の行動を想定したうえで、スパム業者が運営する参照元のページにウイルスなどを仕込んでおくわけだ(図1)。このようなアクセス解析データに悪意を持って参照元情報を残す行為全般を一般的に「リファラースパム」という。

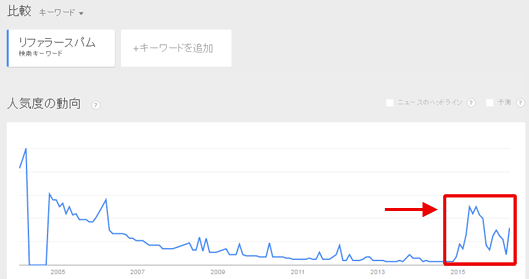
そして、この1年くらいだろうか、Googleアナリティクスでリファラースパムらしきものが増えて困っているという話が多くなっている。Googleトレンドで「リファラースパム」という言葉を調べてみると、あくまでも相対値だが、2014年までは下火になっていた言葉が、2015年に入ってがぜん話題に上ってきたことが伺える(図2赤枠部分)。このトレンドの上昇は、おそらくGoogleアナリティクスのリファラースパムの流行と関係があるのだろう。
リファラースパムの手口を知ろう
皆が知りたいのは、「どうやってリファラースパムを除外するか?」だろう。
いくつかのブログなどでは「参照元(リファラー)でフィルタ(除外)する」方法が書かれているが、これからも何百何千と出てくる「インチキ参照元」をその都度フィルタしていくのは現実的ではない。「参照元のスパムだから参照元でフィルタする」という発想はわからないでもないが、ここでは、現状最も簡単に、そして当面更新の必要もない別の方法をお伝えしたい。
そのうえで、今後現れるかもしれない新手のスパムに対応できるようにしたいのであれば、時間をさらに少し割いて、最後まで読み進めてほしい。今回の記事では、「なぜリファラースパムが急増しているのか」その根本的な理由がMeasurement Protocolの仕組みにあること、そして「Measurement Protocolを利用してスパム業者が何をやっているのか」ということまで推察する。
その仕組みと手口を知れば、次に新手のスパムが現れても自分で対策を考えられるようになるだろう。いつまでも対症療法で、毎回何かあってから慌てふためくのはやめたくないだろうか? そうした読者の方は、最後までお付き合いいただきたい。
リファラースパムは「ホスト名」で判別できる
まず、結論を述べよう。リファラースパムを除外するには、「ホスト名を自社ドメインだけに絞り込んでデータを見る」これだけだ。具体的な方法は2つ。手順は順を追って説明していく。
まず前提としての知識をおさらいしよう。計測対象ドメインのことをGoogleアナリティクスでは「ホスト名」というディメンションで表記している。当然ながら、普通は自社サイトでないドメインは本来計測対象外となる。この「ホスト名」はどのレポートにあるのだろう。
Googleアナリティクスで[ユーザー]>[ユーザーの環境]>[ネットワーク]レポート(図3赤枠部分)を表示してみよう。そしてプライマリディメンションで「ホスト名」(図3青枠部分)を選択する。これが計測対象ドメインを表示するレポートだ。
自社ドメインしかないはずなのだから、当たり前すぎて普段はまず見ることがなかったレポートだが、ここでは大活躍する。なぜならここにスパムが集結しているからだ。図3の例では、計測対象サイトのドメインが「xfusion.jp」なので、計測対象外のホスト名(図3緑枠部分)はすべてスパムだ。
![図3:[ユーザー]>[ユーザーの環境]>[ネットワーク]レポート](/sites/default/files/images/article2016/ga-mp/ga-mp03_02.png)
このレポートにセカンダリディメンションで参照元を追加する(図4赤枠部分)と、(not set)の参照元も怪しげな参照元ばかり(図4青枠部分)で、いわゆるリファラースパムであることがわかる。
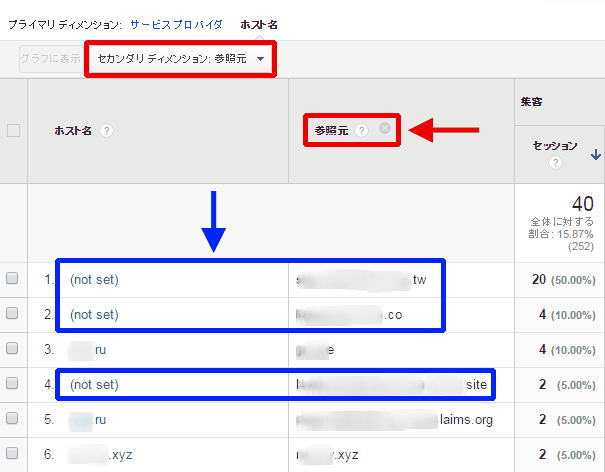
もちろん、場合によっては、テスト環境のサイトやグーグルキャッシュサイトでの閲覧(webcache.googleusercontent.com/translate.googleusercontent.comなど)といったリファラースパムではないホスト名が表示されることもある。それはシステム担当者などに聞けば、関係のないサイトか関係ありそうなサイトかの切り分けは容易にできる。それ以外の怪しげなホスト名はまずスパムによるデータと考えてよい。
ちなみに、筆者が関係しているサイトをいくつかチェックしてみると、2015年1月前後から自社サイト以外のホスト名によるデータが急増している。上下に振れ幅はあるものの、月間1万セッションもない小規模なサイトでも、月間数百セッションのスパムデータが存在した。アクセスの多いサイトでは影響は小さいかもしれないが、小規模なサイトでは大きな影響を受けるレベルだ。
セグメントで絞り込むか、フィルタで除外するか
具体的な対処法は、次の2つのどちらかになる。
- 方法1:過去のデータは、セグメントで対応する
- 方法2:今後のデータをきれいにしたい場合は、ビューにフィルタを適用する
それぞれ、画面を交えて具体的な手順を解説していこう。
方法1:セグメントで絞り込んでレポートを見る
セグメントで対応する場合は、以下のように設定する。
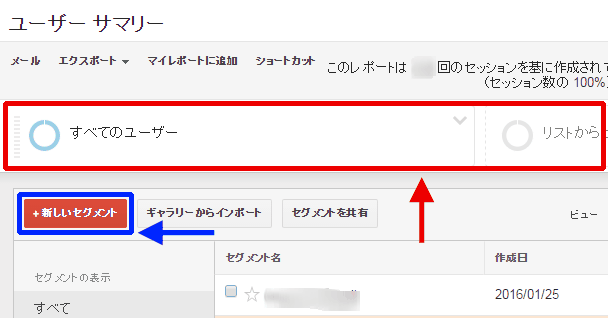
- レポート上部のセグメントのエリアをクリック(図5赤枠部分)
- 「+新しいセグメント」をクリック(図5青枠部分)
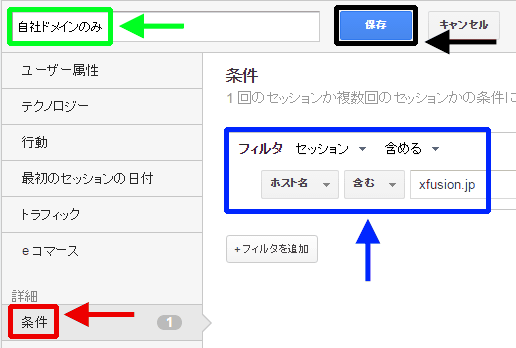
セグメントの作成画面が表示されたら、以下のように設定しよう。図6青枠部分のホスト名の値「xfusion.jp」は、サイトに合わせて修正してほしい。
- 「条件」をクリック(図6赤枠部分)
- セグメント条件を設定(図6青枠部分)
- セグメントの名前を付ける(図6緑枠部分)
- セグメントを保存(図6黒枠部分)
セグメントを保存できたら、表示しているレポートにこのセグメントを適用しよう。これで、怪しいホスト名のスパムデータが除外された状態になる。
方法2:フィルタでスパムのデータを除外する
フィルタを使用する場合は、アナリティクス設定からビューにフィルタを適用する。なお、フィルタを使う場合は注意が必要だ。この方法だと設定する以前と以降でデータの継続性がなくなるので、新しいビューを作成して、そのビューにフィルタを適用するのが望ましい。作業を間違えておおもとのデータを削除してしまわないよう、必ず新しいビューを別途作成してから、そちらにフィルタを適用するようにしよう。
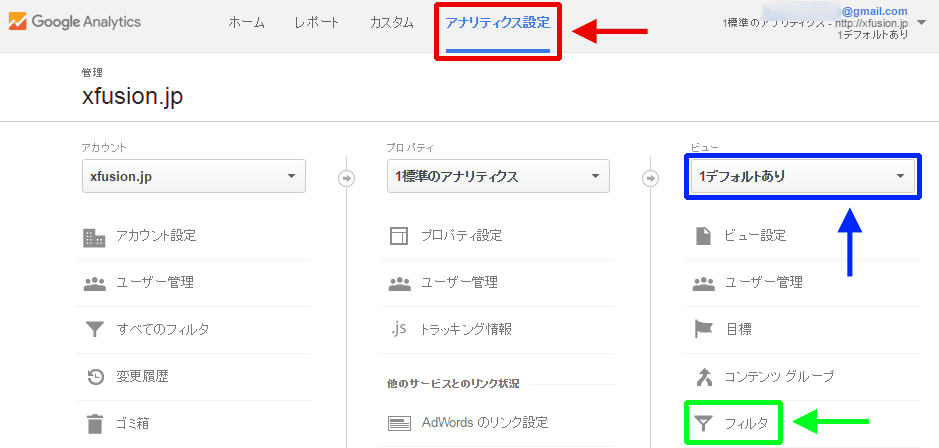
- 「アナリティクス設定」を表示(図7赤枠部分)
- フィルタを適用したいビューを選択(図7青枠部分)
- 「フィルタ」をクリック(図7緑枠部分)
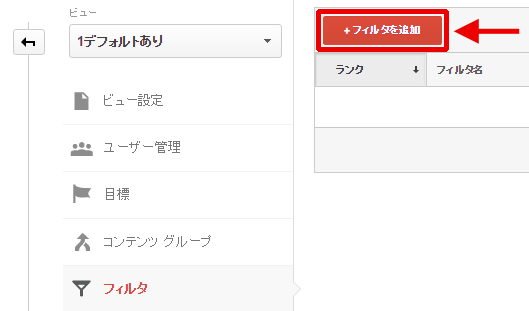
- 「+フィルタを追加」をクリック(図8赤枠部分)
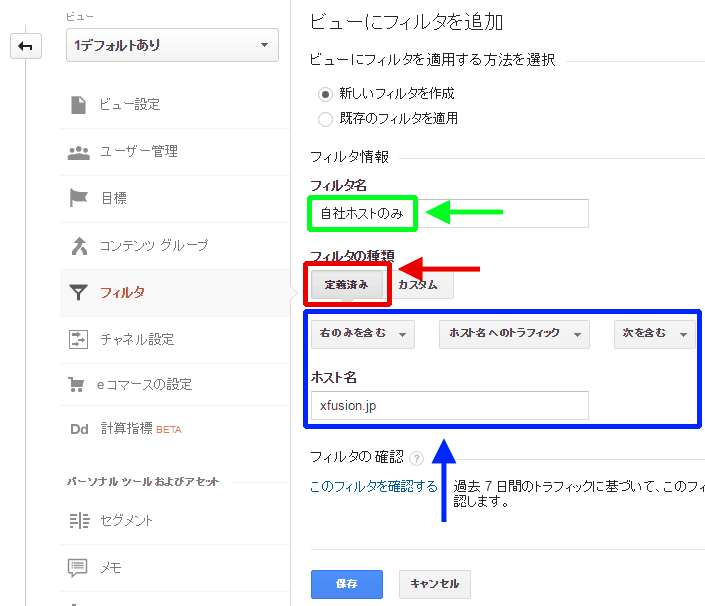
- 「定義済み」を選択(図9赤枠部分)
- 「右のみを含む」「ホスト名へのトラフィック」「次を含む」を選択(図9青枠部分)
- 「ホスト名」に自社のドメインを記述(図9青枠部分)
- フィルタ名を付ける(図9緑枠部分)
フィルタが作成できたら「保存」をクリックしよう。この設定以降、該当のビューには自社ホスト名のデータのみが集計されるようになる。
リファラースパムの実態はデータの「偽装送信」
では、昨今急増しているリファラースパムは、一体どのようにして生成されたデータなのだろうか?
「Measurement Protocolの仕組みを利用したデータの偽装送信」というのが、筆者の考えだ。Measurement Protocolの仕組みは特集の連載第1回を参照してもらいたい。一定の形式を満たしていれば、気軽に誰でもどこからでもグーグルにデータを送信でき、そして機械的に送りつけることができるので、スパム業者はこの仕組みを利用していると考えられる。
おそらく、スパム業者はこの仕組みで手当たり次第にリクエストを飛ばしている。状況証拠をお見せしよう。自社サイトのドメインを除いたホスト名で絞り込んだデータを詳しく見てみたのが図10と図11だ。
各種ディメンションを並べたカスタムレポートを作成してみたのだが、ディメンションの値に歯抜け「(not set)」が多いことが確認できる。たとえば言語は「(not set)」が多い(図10赤枠部分)。ブラウザやオペレーティングシステムはもっともらしいユーザーエージェントを付けているのか、まともなものが多いようだ(図10青枠部分)。

別のカスタムレポートを見ると、参照URLも「/」(つまりトップページ)か「(not set)」だ(図11赤枠部分)。通常、参照元ドメインがあって、参照URLが存在しないなんていうことは発生しない。
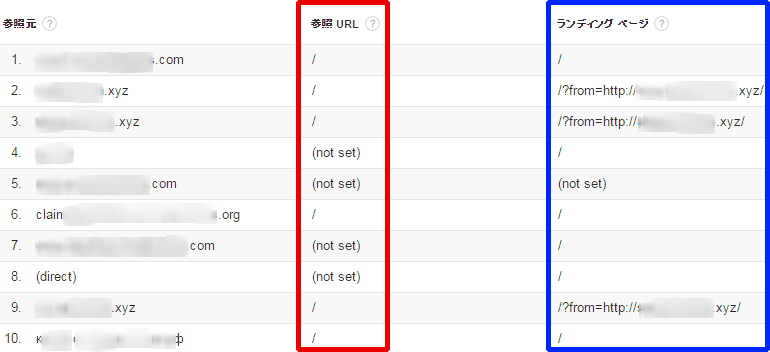
ランディングページも「/」(つまりトップページ)を除くと、「?from=」といったパラメータが付与されていて(図11青枠部分)、「閲覧ページから参照元に気が付いてもらおう」というスパム業者の工夫が見てとれて、失笑を禁じ得ない。
こういった歯抜けのデータを見ると、スパム業者のやることはやはりまだ雑で、とにかく簡単に大量生産、大量リクエスト送信できる方法をとっているという実態がわかる。これらから総合的に判断すると、スパム業者はMeasurement Protocolの各種パラメータを網羅的に付与するのではなく、必要最低限なパラメータに加えて自分たちのリファラー(参照元)を仕込んでリクエストを送信しているのだと想像できる。
また、これは推測になるが、この時期にリファラースパムが急増した理由は、特集の第2回で解説したように、すべてのプロパティがMeasurement Protocol仕様でデータ収集を受け付けるようになったためだと想像している。この強制移行の時期は明確にわからないが、仮に2015年1月前後であったとすれば、冒頭に話したリファラースパムの流行時期と合致するのではないだろうか。
プロパティIDが「UA-xxxxxxxx-2」以降だとスパムはこない?
もう1つ発見したこととしては、トラッキングID(プロパティID)の末尾が2番(UA-xxxxxxxx-2)以降のものでは、リファラースパムはほとんど見つからないという特徴がある。あるアカウントのケースでは、プロパティIDがUA-xxxxxxxx-1では毎月100セッション程度のスパムがあるのに対して、プロパティIDがUA-xxxxxxxx-2では毎月1セッションあるかないかといったレベルだ。
おそらく、Measurement Protocolの必須のパラメータであるtidの末尾の「-1」を固定して、UA-00000001-1からUA-99999999-1までかたっぱしからリクエストを送信しているのだろう。UA-xxxxxxxx-2やUA-xxxxxxxx-3は、アカウントで2つ目、3つ目のプロパティを作っていないとエラーになってグーグルに察知されやすいだろうし、スパム効率も悪いと考えているのかもしれない。
彼らの流儀に合せるのは本末転倒だが、もしこれから新規にアカウントを取るのであれば、最初のプロパティはテスト用にして、2つ目のプロパティを作ってそれを本番にするといった対応も有効かもしれない。すでにUA-xxxxxxxx-1で運用しているサイトを新しくUA-xxxxxxxx-2に差し替えると、データの継続性がなくなってしまうのでそこは注意が必要だ。
今後考えられるスパムとその対策
現状のリファラースパムは、冒頭に書いたホスト名の対策でひとまずは十分だと思われる。ただ、今後スパム業者がもっと緻密なことをやってこないとも限らない。たとえば、あらゆるサイトにボットを飛ばして、ドメインとプロパティIDのセットを調べてきて、それをMeasurement Protocolのパラメータに正しく仕込んでくるなんてことも技術的には可能だろう。そんなことをされたら、ホスト名で絞り込んでもすり抜けてしまうので、ここで書いた対策は通用しなくなる。
そのころにはグーグルがまともなスパム対策をしてくれることを期待したい。たとえば、「サイト運営者しか知り得ないMeasurement Protocolのパラメータを1つ加えて、そのパラメータと固有の値が合致していないリクエストは受け付けない」といった仕組みも考えられる。これもスパム業者に絶対に察知されないかというと疑問は残るが、少なくとも現在の誰でもどこからでも自由に偽装データを飛ばせる仕組みは早急に修正してもらいたいものだ。
補足になるが、アナリティクス設定(図12赤枠部分)のビュー設定(図12青枠部分)にある「ボットのフィルタリング」機能(図12緑枠部分)はリファラースパム除去に有効なのだろうか? 結論から言えば、この機能はリファラースパム対策には無力だろう。
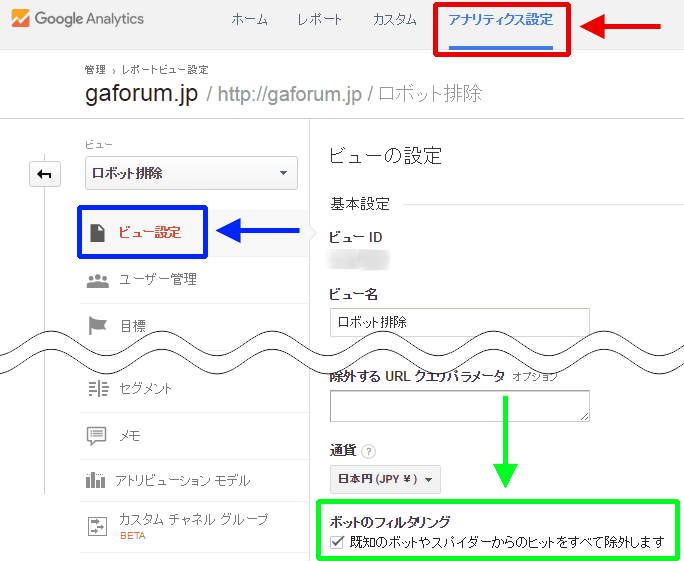
筆者の関係するサイト(月間1万セッションほど)で確認したところ、直近18カ月で、この機能のオン/オフによる差は400セッション程度で、除外されたデータの内訳を確認すると、そのホスト名はきちんと自社サイトのドメインが付いているものだった。また「言語」ディメンションの値を見ると、すべてが「en-us」だった。明らかに今回のリファラースパムで除去されるものとは違うデータだ。
少し古いが、公式情報によるとこの「ボットのフィルタリング」機能は、IAB(インタラクティブ・アドバタイジング・ビューロー)のボット/スパイダー一覧にあるユーザーエージェントに合致したデータを削除すると書いてあるので、いわゆるリファラースパムとは別種のものを除外しているといえる。リファラースパム対策とは別に、この項目もチェックしておくのがよさそうだ。
- Introducing Bot and Spider Filtering(Google+)
https://plus.google.com/+GoogleAnalytics/posts/2tJ79CkfnZk
- この記事のキーワード
関連記事
最初にやるべきGAの「フィルタ設定」自分のアクセスやIPの除外方法[第7回]
2016年7月7日 7:00
メルマガの開封率も計測できる! ユニバーサルアナリティクスの「Measurement Protocol」とは?
2016年4月7日 7:00
集客に一役買っている他サイトはどこ? GAの参照元を見てコンテンツ制作のヒントを得よう[第36回]
2017年3月23日 7:00
【GA応用編】独自のカスタムディメンションを作成・設定する方法とは[第54回]
2017年9月21日 7:00
ウチのメルマガは効いてるの? メルマガからの訪問に絞り込んで行動や成果を確認するには?(第12回)
2014年6月26日 9:00
GAで参照元とランディングページを一覧表で見る! カスタムレポートならではの分析方法[第63回]
2017年11月30日 7:00
バックナンバー
この記事の筆者

筆者の人気記事
URLクエリパラメータ(クエリストリング)の意味とは。使い方は? 除外はすべき?[第4回]
2012年4月26日 9:00
代表的な4つのグラフの使い分けのポイント(第2回)
2008年10月29日 11:00
棒グラフの用途に合った書き方 グラフの特徴や使い方のルールも解説!
2009年1月16日 10:00
分布図(散布図)とバブルチャートの使い方とは?正しいグラフの見方(第7回)
2009年4月22日 10:00
GAのトラッキングコードを正しい位置に設定する[第2回]
2016年6月2日 7:00
アンケートは「回収率」が重要! 信頼性が有効回答数よりも高くなる理由
2008年5月16日 10:00





