謎だらけのSEOテクニカル問題を解決する8つのポイントとは? 【後編】httpsへの移行が生んだリダイレクトの永遠ループ?
GoogleChromeで正しくインデックスされるための仕込みタグとは?
2018年11月5日 7:00
「謎だらけのSEOテクニカル問題を解決する8つのポイント」を3回に分けてお届けしてきたが、今回が最終回だ。最終回の今回は、残る2つのチェックポイントについて説明するとともに、前編で紹介した4つの不可解な疑問にも答えていく。
前編を読んでおく・中編を読んでおく
7. グーグルは、さまざまな重複/類似ウェブサイトの中から自分のサイトを集約できているか?
ここに至るまでのさまざまな問題をクリアしていれば、「自社のウェブサイトはスムーズに運用できている」と安心しているはず。しかし、自分のウェブサイト「だけ」ですべての問題を解決できているわけではない。ときには、より広範な環境や周囲のSERP(サープ/検索結果を表示するページ)にも目を向ける必要がある。
一般的には、次のような問題が挙げられる。
- 問題のあるページと類似または重複しているコンテンツ。
これは、シンジケートコンテンツなどの意図的に生成された重複コンテンツや、競合他社のスクレイピング、誤ってインデックス登録されたサイトなど意図しないコンテンツであるかもしれない。
いずれにしても、グーグルで完全一致検索を行うと、ほぼ常に見つかるコンテンツだ。なお「完全一致検索」とは、複数のサイトのページから具体的なコンテンツを拾い、引用符で囲って検索することだ。
この時点で問題は見つかったか?
「この時点で問題は見つかったか?」という問いに対して僕が思いつく最善の説明は、「グーグルは類似のページを集約して、その中の1ページだけを表示していると思うか? もしそうなら、グーグルは間違ったページを拾っていないか?」というものだ。
これは従来のグーグル検索である必要はない。Google人材募集やGoogleニュースなどでも、この種のケースが見つかる場合がある。
例を挙げると、小売業の場合、よりオーソリティのある別の業者がいつも同じ商品を最初に掲載しているために、コンテンツが検索順位に表示されないケースがそれに該当する。
これはいつでも同じ状況が起こることもあれば、時間が経つと集約状況が変化することもある。その場合は、問題解決にあたっているグーグルのサービスが何であれ、検索順位チェックツールのランクトラッカーが必要になる。
Pi Datametricsのジョン・アーンショウ氏は後者(疑わしいSERPの変動)について素晴らしい講演をしており、これも必見だ。
問題が見つかったら、それを回避する方法を探す必要があるだろうが、最も簡単な対処法としては、一般に次のようなものが挙げられる。
- コンテンツの重複解消
- 重複を検知するまでのスピードを速くする(表示されるすべての新規コンテンツを24時間配信するRSSフィードを用意することで、改善できることが多い)
- シンジケーションの削減
8. 他に考えられる要因のまとめ
ここまでたどり着いたということは、確信を持って次のように言えるということだ。
- グーグルはいつでも意図したとおりに僕たちのページをクロールできている。
- 僕たちはグーグルに対し、ページのステータスについて常にシグナルを送っている。
- グーグルはいつでも、僕たちが期待するとおりにページをレンダリングしている。
- グーグルは、ウェブ上に存在し得るいかなる複製ページからも正しいページを拾い上げている。
これでも、問題はまだ解決していないだろうか?
そしてそれは確かに重要な問題なのだろうか?
その場合は仕方ない、僕たちを雇ってみるのはどうだろう。
この記事でSEOに関するすべての問題を挙げたいところだが、あまり実用的ではないので、この記事の締めくくりとして、最初に挙げた4つの問題への答えの前に、ここまでの問題に当てはまらなかった要因と解決方法をあと2つ紹介する。
その1. 無効なHTML、またはうまく構造化されていないHTML
君とGooglebotは同じHTMLを目にしているかもしれないが、そのHTMLが無効だったり、間違ったりしている可能性がある。ページが従来のHTMLの仕様に沿わない場合、Googlebot(またはその他すべてのクローラー)は回避策を講じなければならず、それが不可解な動作を引き起こすことがある。
そうした動作を見つける最も簡単な方法は、レンダリングされたDOMツールをよく観察するか、HTMLバリデータを使用することだ。
W3Cのバリデータは非常に便利だが、普通なら気にしないエラーや警告もたくさん検知する。それらの警告のうちどれを気にしなければいけないかというと、次の点だ。
- まず、エラーを探す。
- そのエラーがHTMLの属性に関する場合はすべて無視する。(常に当てはまるとは限らないが、当てはまる場合が多い)
その代表的な例は、head要素の中断だ。
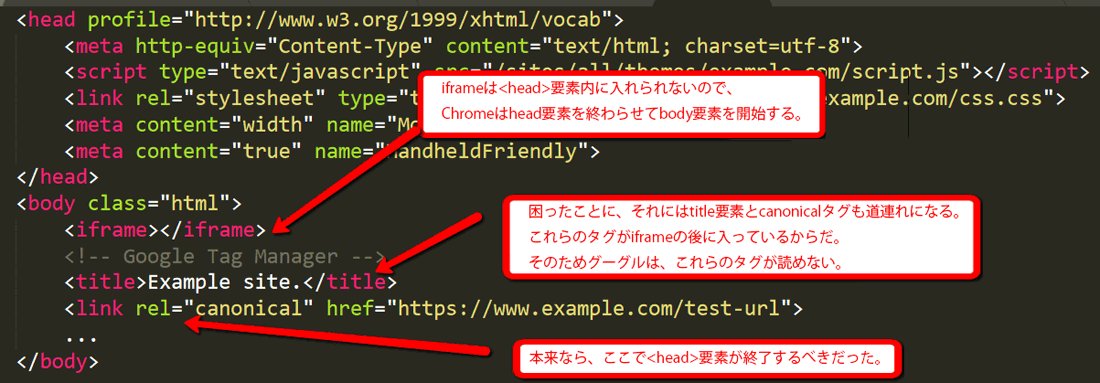
iframeはhead要素内に入れられないので、Chromeはhead要素を終わらせてbody要素を開始する。困ったことに、それにはtitleタグとcanonicalも道連れになる。これらのタグがiframeの後に入っているからだ。そのためグーグルは、これらのタグが読めない。本来なら、headタグは別の場所で閉じる必要があった。
オリバー・メイソン氏は、head要素のうかつな中断について、さらに微妙なケースについて説明した優れた記事を書いている。
その2. 疑わしい場合は差分を比較する
Diff Checkerなどの差分チェックツールで、2つのものを1行ずつ比較しようと試みることの力を過小評価してはいけない。常に有効というわけではないが、効果がある場合は強力だ。
たとえば、グーグルが突然フィーチャードマークアップの表示を停止した場合は、ページをQA環境内の履歴またはWayback Machineと比較してみよう。
最初に挙げたの4つの質問への回答・まとめ
ここで、最初の質問に答えていこう。これらの質問はどれも、Distilledの顧客から寄せられた問題だ。
1. グーグルはなぜ、製品ページに5つ星のマークアップを表示していなかったのか?
グーグルは、サーバーでレンダリングされたマークアップと、クライアントサイドでレンダリングされたマークアップの両方を目にしていたが、サーバーでレンダリングされた方が優先されていた。
そこでサーバーでレンダリングされたマークアップを削除すると、クライアントサイドで設定していた5つ星のマークアップが表示され始めたということだ。
2. Bingはなぜ、グーグルのようにレビューページに5つ星のマークアップを表示しないのか?
この問題は、schema.orgへの参照に起因していた。
<div itemscope="" itemtype="https://schema.org/Movie"></div>
<p> <h1 itemprop="name">Avatar</h1> </p>
<p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span> </p>
<p> <span itemprop="genre">Science fiction</span> </p>
<p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a> </p>
<p></div></p>競合他社のマークアップと比較したところ、唯一の違いは僕たちがitemtypeでHTTPSバージョンのschema.orgを参照していたことであり、これをBingはサポートしていなかった。
頼むよ、Bing。
3. noindexタグを含むページが、なぜインデックス登録されていたのか?
これへの回答は、この記事でも挙げた「head要素を中断してしまう」ケースだ。
開発者らはhead要素にいくつかのアドテクを組み込み、非標準のタグを挿入した。つまり、以下のタグ以外のタグを挿入したということだ。
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
そのため、headセクションが途中で終了し、noindexタグがbodyセクションに取り残されて、読み取ってもらえないという状況に陥った。
4. ウェブサイト上のあらゆるページが約20~50%の確率でクローラーだけに302を返したのはなぜか?
これを解明するには時間がかかった。クライアントは、古いレガシーサイトに2台のサーバーを使っていて、1台はブログ用、もう1台は残りのサイト用だった。この問題は、ブログをサブドメイン(blog.client.com)からサブディレクトリ(client.com/blog/…)に移行した直後から発生するようになった。
サイトを見るだけでは何も問題なかった。ユーザーが個別のページをリクエストしても、どれも問題なく見えた。ブログのすべてのURLをクロールして、リダイレクトされたことをチェックしても、問題はなかった。
しかし、気づいたときにはSearch Consoleでエラー急増のフラグが立ち、通常行われるサイト全体のクローリングの間も、手動で確認したときは正常だった多くのページがリダイレクトのループを引き起こしていた。
僕たちはGoogleのレンダリング機能を使用して確認したが、ページは正常だった。
結局分かったのは、ブログページの直後に非ブログページがリクエストされると(これは現実的に考えてクローラーだけが処理可能な速さだ)、非ブログページへのリクエストはブログサーバーに送信される、ということだった。
これらのリクエストには、長い間忘れられていたリダイレクトのルールが適用され、削除されたブログ記事(またはその他の壊れたURL)はルートに302リダイレクトされる。それに今度は、HTTPからHTTPSへの全面的な301リダイレクトルールが適用されるが、これが再度ブログサーバーからリクエストを受けることになり、永遠にループする。
たとえば、
の直後に
がリクエストされると、次のような結果になる。
- このリンクへの302:これは削除されたブログ記事をルートにリダイレクトするルールだった。
- このリンクへの301:これは全面的なHTTPSへのリダイレクトだった。
- このリンクへの302:ブログサーバーはブログ以外のHTTPSホームページについて把握していないため、再度HTTP版にリダイレクトする。これを繰り返す。
これらの処理が周期的に302エラーを引き起こしていたので、開発者と協力して問題を解決できた。
これまでで最大の難題は?
体験者の声を聞いてみよう。どんな問題に遭遇したことがあるだろうか? ぜひコメント欄で教えてほしい。
この記事の執筆に協力してくれた@RobinLord8、@TomAnthonySEO、@THCapper、@samnemzer、@sergeystefoglo_にも謝意を表したい。
関連記事
【Google公式】英語版SEOオフィスアワーの最新TIPS特集: ページ分割・サイトマップ・title・リダイレクトなどなど【SEO情報まとめ】
2023年1月20日 7:00
イマドキのSEOでJavaScriptに関して最低限知っておきたい調査テクニック(後編)
2018年8月27日 7:00
ウィキペディアがサイト全体を常時HTTPS化、これが今後のWebの方向性か など10+4記事
2015年6月19日 7:00
まとめサイトがグーグル検索から次々と消滅し始めた など10+4記事
2014年2月7日 9:00
グーグル検索結果のデザイン変更に対応! titleタグ見直し5つのステップ など11+7記事
2014年3月28日 9:00
あなたのサイトは大丈夫? 手動ペナルティを受けていないか調べる「手動対策ビューア」をグーグルが公開 など10+4記事
2013年8月23日 9:00
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




