Google Authorshipはなぜ終了したのか、復活するとしたらどのように?(中編)
グーグルはなぜGoogle Authorshipを終了したのか、「著者の信頼度」が検索に反映されることは将来あるのか、あるとすれば、どんな形だろうか。
2015年12月14日 7:00
この記事は、前中後編の3回に分けてお届けしている。Google Authorshipのこれまでについて簡単に説明した前編に引き続き、中編となる今回は、Google Authorshipの復活の可能性について見ていこう。→まず前編を読んでおく
グーグルはGoogle Authorshipを再び利用するのか
Google Authorshipが「終止符を打たれた」2013年8月以降、グーグルからは何の発表もなかった。前編で紹介したように、SMX Eastでゲイリー・イリーズ氏が発言するまでは。
さて、イリーズ氏の発言は、Google Authorshipが検索結果に再び利用されることを意味するのだろうか。
僕はそうは思わない。少なくとも、僕たちが以前に目にしたような形では実現しないだろう。
理由を説明しよう。
イリーズ氏は何も約束をしていない。
ゲイリー・イリーズ氏やマット・カッツ氏、ジョン・ミューラー氏といったグーグルを代表するような人々から、グーグルが何かをする「可能性がある」とか「かもしれない」といった話が出ると、人々はついグーグルが何かを「する予定」だと解釈しがちだ。これはフェアではなく、こういった人々の言葉を曲解することになる。
可能性があるという話が出たからといって、必ずそうなるとと確約されたわけではない。
今のままでも不都合はないのなら……。
では、Google Authorshipを復活させる具体的な計画がないなら、イリーズ氏が著者やパブリッシャーに対して「rel=author」タグの使用を続けるべきだとあえて発言したのはなぜだろうか。
第一の理由は、ある集団に何らかのスキーマの利用を始めてもらったなら、グーグルはそのままで維持したいと考えるからだと思う。ウェブページの情報を整理するのに役立つなら、その情報が現在「利用されている」かどうかにかかわらず、どんなものであっても検索エンジンにとっては都合がいい。
「rel=author」について言えば、グーグルにとっては今も、コンテンツと著者の関連を確実に知ることができるという点で役立っているのかもしれない。
Google Authorshipが終了したとき、僕は多くの人から「このタグをコンテンツから削除するつもりか」と尋ねられ、「なぜ削除する必要があるのか」と問い返した。残しておいても、害は何もない。それどころか、著者として個人のブランドの評判をオンラインで確立しようと努めている者として、コンテンツの著者が僕だとわかってもらえるヒントになるものは、可能な限りグーグルに提供したいと考えるのが当然ではないだろうか。
Google Authorshipを終了した原因は、まだ謎のままだ。
グーグルの検索に関する変更について、その理由がすべて明らかにされることはおそらくないと思われるが、ジョン・ミューラー氏が述べた公式の理由は、「モバイルファースト」のユーザー体験戦略をグーグルが推し進めていることに関連したものだった。
モバイルファーストとは、検索体験がモバイルで行われる比率がますます高まっているという認識だ。グーグルは最近、検索全体においてモバイルからの検索がデスクトップからのものより多くなったことを明らかにしている。この傾向が逆戻りすることは、まずないだろう。
これに対応してグーグルは、検索を含むすべての製品で、デザインをよりシンプルに、よりわかりやすく、より整然としたものにする取り組みを続けているのがわかる。最近行われたロゴのデザイン変更でさえ、小さい画面に最適化するためだった。
ミューラー氏によれば、Google Authorshipのスニペットは、モバイルの世界にとってはごちゃごちゃしすぎていて、継続を正当化できる十分なメリットをユーザーに与えられなかったのだという。
Search Engine Landの記事で、エリック・エンゲ氏と僕は、グーグルがGoogle Authorshipの実験を終了したのには他にも理由があるとして、次のような推測を述べた。
- このタグの普及率が比較的低かったこと
- Google+(これは、グーグルが著者を特定するための「アンカー」として利用していたものだ)への参加者が少なかったこと
- このタグを試した人の多くがタグの実装を間違えていたこと
最後の点について言えば、エンゲ氏が主要なパブリッシャーを調査したところ、Google Authorshipのタグをわざわざ実装してみたパブリッシャーでさえ、その多くが間違っていたという。ハイテク関連やSEO関連のパブリッシャーでさえそうだったのだ。
こんな状況では、無秩序でバランスを欠く印象を生むだけで、検索エンジンが求めているものにはなるはずがない。結局のところ、グーグルは、Google Authorshipのリッチスニペットを含む検索結果が、それ以外の検索結果に比べて本当に優れているとは保証できなかった。となれば、そんな物を大切にする必要があるだろうか。
ゲイリー・イリーズ氏は、「rel=author」を使用するサイトが増えればグーグルが再び利用し始めるかもしれないと述べたが、そうなったとしてもここに述べたような状況が変わるとは思えない。したがって、グーグルが「rel=author」を今後また利用することがあるとしても、僕たちが気に入っていたあのGoogle Authorshipプログラムのようにはならないだろう。
では、「著者の信頼度」が検索に反映されることは、将来あるのか
この質問に、僕ははっきり「イエス」と答える。
グーグルの人々がこれまで公式にあるいは非公式に示唆したことから考えると、彼らは著者の信頼度を判定する適切な方法を見いだしてはいないが、グーグルは今も信頼度を判定することに関心を持っているようだ。
では、著者やパブリッシャーがみんなすべてを正確にタグ付けするとは期待できない現状にあって、グーグルが著者の情報と信頼度をどのように評価するつもりなのだろうか。
その答えは、ナレッジグラフ、エンティティ検索、機械学習にある。
非常に初期の検索エンジンは、ほとんどが人の手によるものだった。たとえば、ヤフーの検索は元々、編集者のグループが目にしたすべてのウェブページを分類しようとしたところから始まったものだ。だが、ワールドワイドウェブが生まれて急速に拡大し始めると、そのようなやり方では対応できないことがすぐに分かった。
そしてウェブページのテーマと相対的信頼度の両方を評価する手段として、ウェブページ間のハイパーリンクを利用するほうが優れた方法であることが判明し、ウェブ全体の検索が始まった。
グーグルの掲げる使命は「世界の情報を整理する」ことにあることを思い出してほしい。時の経過とともに、グーグルはウェブページについて知るだけでは十分ではないと気づいた。現実の世界は、人、場所、事物、概念といったエンティティ間の関係によって構成されており、グーグルは、こういった関係を学ぶ方法が必要だった。しかも、十分な規模をもって。
ナレッジグラフはグーグルが学習したことを蓄積したものであり、機械学習はそれなりの規模を維持して学ぶためのエンジンだ。端的に言えば、検索エンジンの機械学習とは、フィードバックメカニズムによって自ら学習できるアルゴリズムを開発することだ。グーグルはこのテクノロジーを利用して、エンティティとその関係性を取得して互いにリンク付けする作業を幅広く行っている。
僕の見立てでは、このプロセスが次の革新的なステップとなって、グーグルはやがて、あるトピックに関して重要性が高いとみなされる著者を、その人物が実際に著したコンテンツによって特定し、読者の捉え方からそのコンテンツの相対的な信頼度を評価し、これを検索順位の決定要因として利用できるようになるだろう。
実際、マット・カッツ氏は2013年6月、著者情報のこれからについて語った動画の中で、ナレッジグラフを利用したアプローチをほのめかしているように思える。ここでカッツ氏は、グーグルがキーワードへの依存から脱却し、「文字列から事実へ」と移行し、検索結果の質を高めるために、ウェブコンテンツの背後にいる「現実の人々」と「その関係性」を明らかにする方法を見いだしていくと語った。
機械学習のプロセスが利用するのは、人々がすでにウェブ上で行っている行為以外の何ものでもないということに注目してほしい。
このプロジェクトはすでに進行中だ。たとえば今、グーグルに、「Who is Mark Traphagen?」(マーク・トラファーゲンってだれ?)と聞いてみてほしい(つまり私のことだ)。米国など英語が使われている国にいる場合、おそらく検索結果の一番上に次のような内容が表示されるだろう。
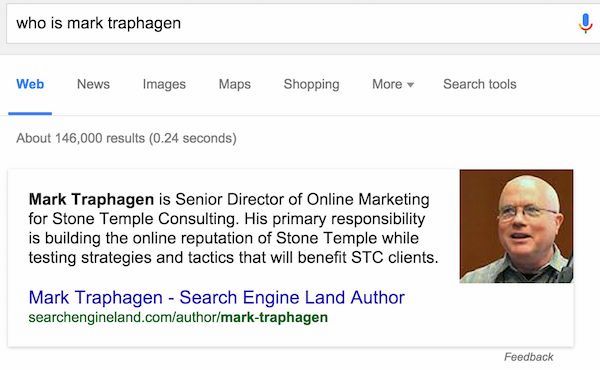
これは、グーグルのナレッジグラフの結果を表示するナレッジパネルだ。ここからいくつかのことがわかる。
グーグルは、人々が探しているその対象、つまりその「マーク・トラファーゲン」が僕である可能性を強く確信している。世界にはグーグル検索に表示される可能性のあるマーク・トラファーゲンが他にも何人かいるが、グーグルは、「マーク・トラファーゲン」を検索しているユーザーの大多数が僕についての結果を求めていると考えているのだ。ありがとう、みなさん。
グーグルは、人々が探しているマーク・トラファーゲンが、Search Engine Landで記事を書いていると強く確信している。そのため、サイトに掲載された僕のプロフィールは、真のマーク・トラファーゲンを求めるユーザーの(聖杯を求めるにも等しい)人生をかけた探究に、適切ですぐにわかる答えを与えるものとなる可能性が高いのだ。
グーグルがこのような取り組みをそれなりの規模で継続することが可能なら、僕たちの助けなどなしに、検索順位に著者の信頼度を反映させるといった問題を解決できるだろう。ありがたいことだ。
ではこれが、ゲイリー・イリーズ氏の勧告とどう関係するだろうか。思うに、このようなプロジェクトを十分な規模で成功させるには、最終的には機械学習に頼らなければならないことは承知しているものの、それまでの間どんなことであれ僕たちに機械の手助けをしてもらえれば、グーグルは歓迎するということなのだろう。
第1期のGoogle Authorshipについていえば、Authorshipプロジェクトの真の目的の1つに、機械学習のアルゴリズムをトレーニングするために僕たちの助力を得ることがあったのだと見る人もいるのだ(僕もその1人だ)。その点で、「rel=author」タグはまだまだ役立つのだろう。
これまでGoogle Authorshipの沿革と復活の可能性について見てきた。最終回となる次回は、Google Authorshipの将来について考えていく。→後編を読む
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




