検索エンジンがキーワードとページの“関連性”を算出する方法と、検索順位との関係
検索エンジンにおいて、検索キーワードに「関連性がある」ページがどれかを判断する「関連性エンジン」の仕組み
2014年1月6日 9:00
この記事では、検索エンジンにおいて、検索キーワードに「関連性がある」ページがどれかを判断する「関連性エンジン」の仕組みを探るとともに、SEO担当者にとってこれが何を意味するかについて説明する。
いまのウェブ検索エンジンは、「情報検索」の分野における数十年もの研究に基づいて、ウェブページが検索クエリに関連しているかどうかを評価する洗練された方法を備えているのだ。
関連性を判定する
ユーザーからクエリを受け取った検索エンジンが最初にしなければならないのは、インデックス内にあるページのなかで、どのページがクエリに関連していて、どのページが関連していないかを判断することだ。僕はこの記事全体を通じて、これを「関連性(レリバンシー)」の問題と呼ぶことにする。より正式に定義するなら、次のようになる。
検索クエリとドキュメントが与えられたとき、そのクエリとドキュメントの類似性を評価する関連度を計算すること。
この場合の「ドキュメント」には、title要素、meta descriptionタグ、被リンクのアンカーテキストなど、クエリがページに関連しているかどうかを判断する助けになると思われる、あらゆるものが含まれる。実際、検索エンジンはさまざまなページ要素を使用して多くの関連度を計算し、それらすべてに重みを加えることで、最終的な関連度を導き出している。
関連性の問題は、研究者の間で極めて詳細に研究が進められてきた。この分野で最初に論文が出たのは数十年前だが、現在も研究が続けられている。この記事では、時間という試練に耐えて生き残った最も影響力のある手法を重点的に取り上げる。
「関連性」と「検索順位」それぞれの処理
「関連性の判定」と「関連ドキュメントの検索順位付け」という2つの処理は、検索エンジンの中では1つの段階として実行されるとしても、概念上は分離できる。
その概念的フレームワークでは、まず関連性の段階でページごとに二値的(YesかNoかに分ける)な判断を行い、次に検索順位付けの段階でドキュメントの順序を決めて、結果をユーザーに返す。

この記事では、こうした分離や、これがさまざまなランキングシグナルにどのように関連しているかを明確に示すデータをいくつか紹介する。
「クエリモデル」と「ドキュメントモデル」
「検索クエリ」や、そのクエリに合致するかどうか調べられる「ドキュメント(Webページ)」は、そのままで文字として存在しているが、文字で作られた文章というのは、実はコンピュータにとっては扱いづらい形式だ。
なので、クエリやドキュメントを「書かれたままの文字列」から「コンピュータで計算できる状態」に翻訳することが、類似度を計算する際の最初のハードルだ。
これには「クエリモデル」や「ドキュメントモデル」を利用する。ここで「モデル」という言葉は、文字列を計算可能な形にすることを格好よく言い換えたに過ぎない。
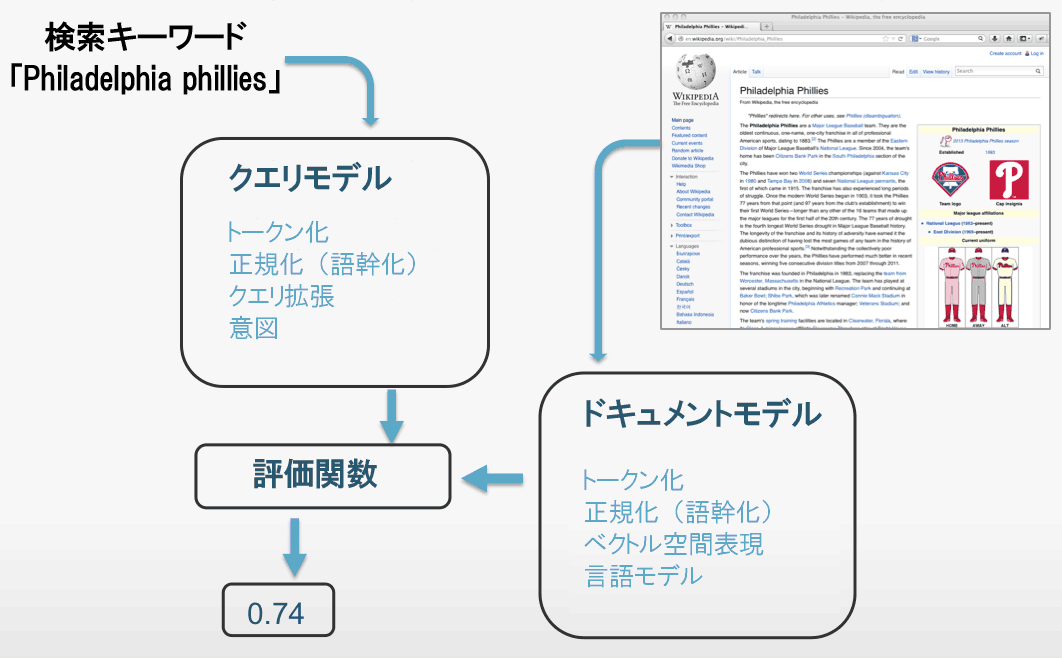
上の画像では、このプロセスを米プロ野球チームの「フィラデルフィア・フィリーズ」というクエリと、フィラデルフィア・フィリーズに関するウィキペディアのページの場合で示している。
類似度の計算では、クエリモデルとドキュメントモデルによって、検索クエリやWebページをコンピュータ処理可能な状態にし、それを最終段階で評価関数にかける。
以下では、この「クエリモデル」と「ドキュメントモデル」について、それぞれ解説する。
クエリモデル
次に示す画像は、数種類のクエリモデルを示している。図の下のほうが基本的な処理で、上のほうに行くにしたがって高度な処理になる。
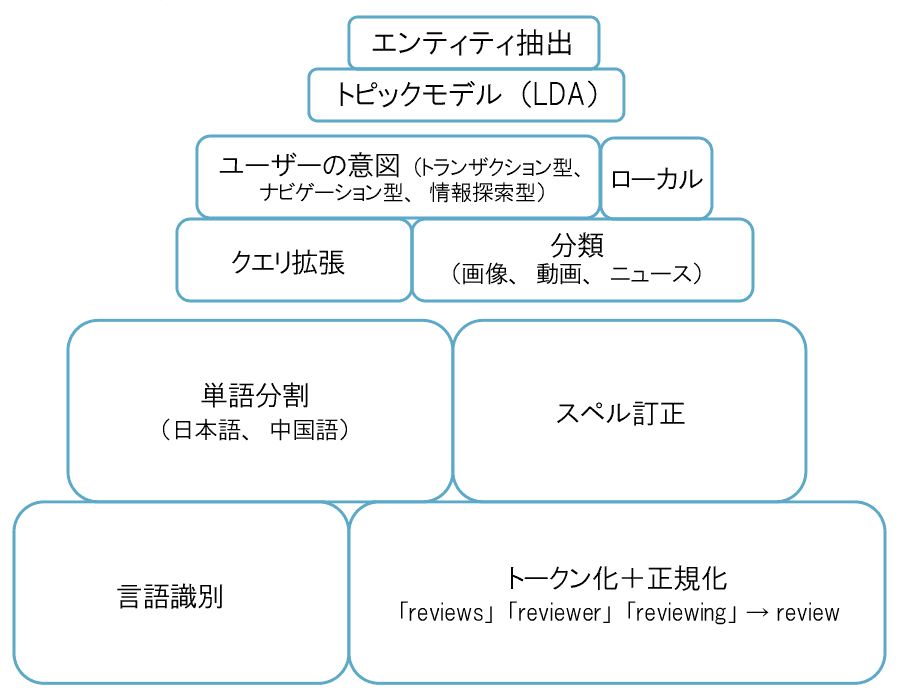
下のほうにある基礎の部分には、次のようなものがある。
トークン化 ―― 文字列を単語に分割する処理
単語の正規化 ―― 一般的な語尾を除去する語幹化などの処理
スペル訂正 ―― クエリに含まれる単語にスペル(綴り)のミスがある場合、検索エンジンはそれを訂正して、正しいスペルの単語に対して結果を返す
基礎の部分の上には、「クエリ分類」や「意図の判断」などが乗っている。検索エンジンは、あるクエリが時期的なものと判断するとニュースの結果を返し、クエリの意図がトランザクション型だと判断するとショッピングの情報を表示するが、そうした処理に対応する部分だ。
最後に、ピラミッドの頂点には、「エンティティ抽出」や「潜在的トピック表現(LDA:Latent Topic Representations)」など、より抽象的なクエリ表現が置かれる。実際、グーグルは「フィラデルフィア・フィリーズ」が米メジャーリーグの野球チームであることを認識しており、ちょうど野球シーズンということで、前日の夜のスコアを検索結果の上部に(そして右側にはナレッジグラフを)表示する。
ドキュメントモデル
クエリモデルと同様、検索でよく使われるドキュメントモデルにはさまざまな種類がある。

「TF-IDF」は、最も古く最もよく知られたドキュメント処理方法の1つで、各クエリおよびドキュメントをベクトルとして表し、コサイン類似度の一種を評価関数として使用するものだ。
「言語モデル」は、言語の統計値に関する情報を符号化するもので、たとえば「search engine optimization」(検索エンジン最適化)というフレーズは「search engine walking」(検索エンジン歩行)というフレーズよりはるかに多く使われる、といった知識を持っている。言語モデルは、さまざまなアプリケーションの中でも特に機械翻訳や音声認識で多く使われている。また、情報検索にも非常に有益だ。
そのほかにも、クエリとドキュメントを与えられて関連性の確率を直接モデル化する「確率ランキング原理(PRP:Probability Ranking Principle)」を使用するモデルもある。このうち、「Okapi BM25」は特に効果を発揮している。
相関関係の調査
ここまで読んだ人は、こんなことを思うだろう。
検索エンジンは、実際にこれらいずれかのモデルを使用しているのか、使用しているとしたら、どれが最も重要なのか。
これを探るため、僕たちは過去に行った相関関係の調査(一般的な方法に関する背景はここを参照)と同じような調査を考案した。ここではグーグル米国版を使い、約14000件のキーワードで検索した上位50件の結果を収集した。これによって約60万ページが得られ、その後これらのページをクロールして、さまざまな類似度の計算に使用した。

ご覧のように、「言語モデル」による手法が、相関係数0.10と最高の成績を収めた(スピアマンの順位相関係数の平均)。これは、研究文献で公開された結果と一致している。
最初にクエリとドキュメントの両方を語幹化(正規化)して再計算すると、相関係数は全体的に少し高まる。
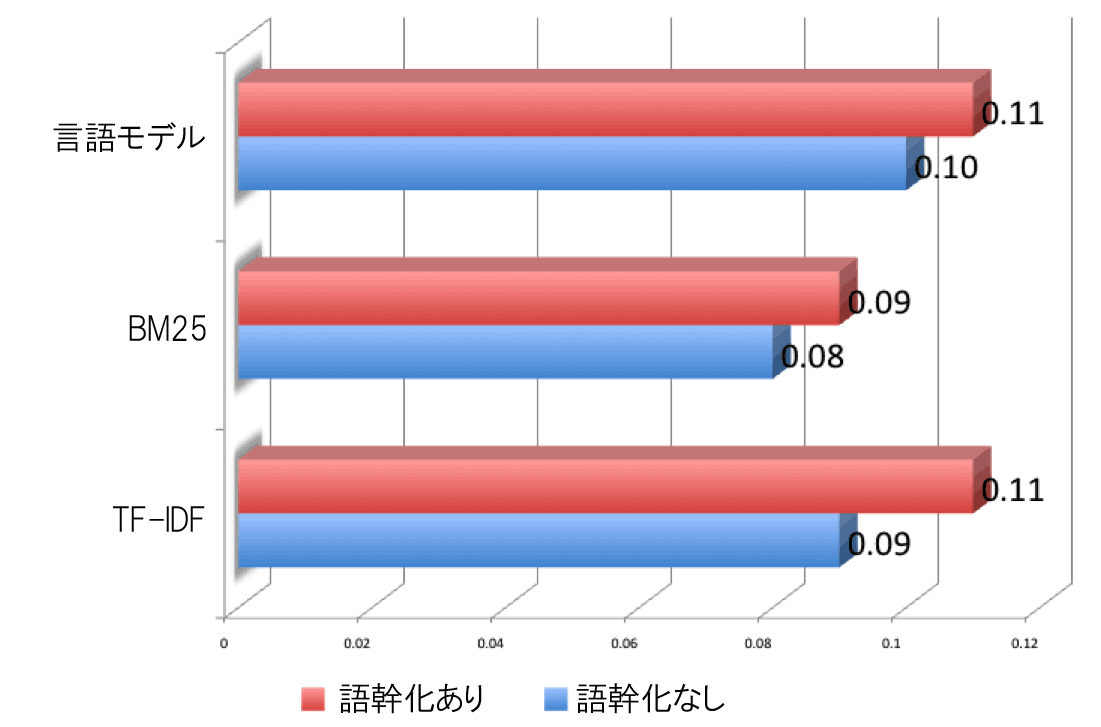
これは、グーグルが実際に関連性の計算で何らかの単語正規化や語幹化を行っていることを示唆している。
「関連性」と「検索順位」の関係
同じデータセットでこれらの相関関係とページオーソリティ(Mozscapeインデックスの被リンク集計メトリクス)を比較すると、以下のように大きな違いが見られる。

ここで、これらの洗練された類似度がそれほど有益ならば、なぜ相関係数はもっと高くならないのか、という疑問が生じる。その答えは、上述した概念上の関連性とランキングの分離にある。
僕はこれを確かめるため、以下のような実験を考えた。
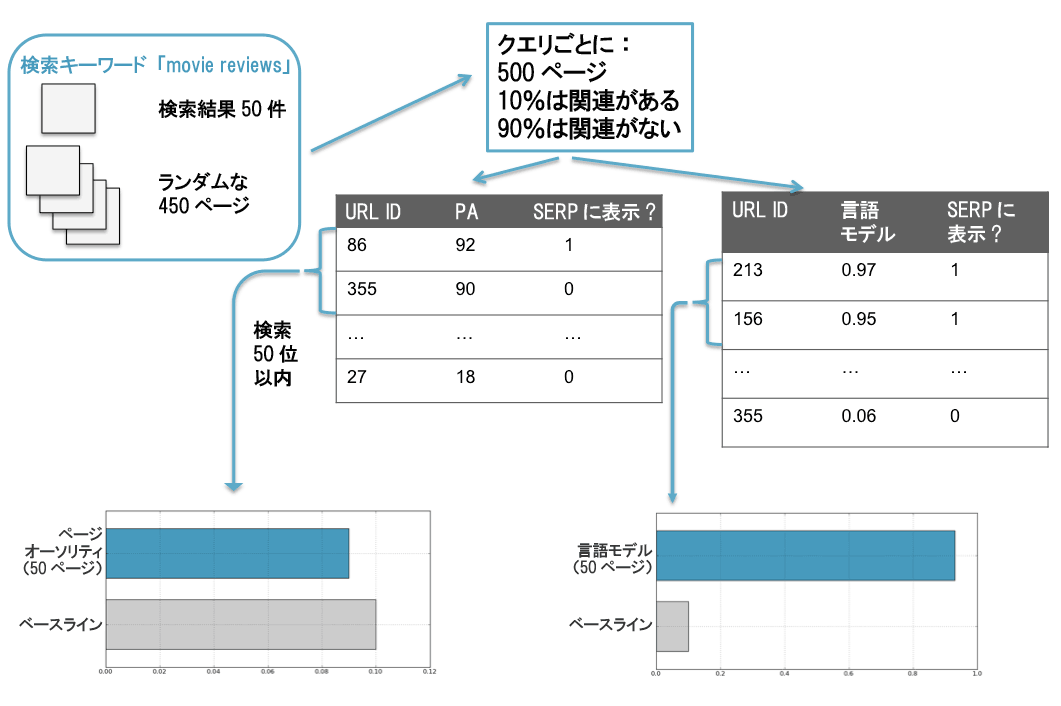
この実験は、「関連性のあるページ」と「関連性のないページ」を選別するという点において、「ページオーソリティ」と「言語モデル」のどちらがうまくできるかを算出するためのもので、次のようなことをしている。
まずランダムに450ページをデータセットから取り出した。元になったのは、上位50件の検索結果を(1位のページが9件、2位のページが9件、などとなるよう)横断的に階層化したデータセットだ、
次に、検索キーワードごとの検索結果の上位50ページに、このランダムな450ページを追加した。これで、検索キーワードごとに500ページからなる1つのグループができた。
この500ページのうち、50ページは元からそのキーワードでの検索結果(SERP)にあったもので、450ページは検索結果には本来はなかったものだ。つまり、500ページのうち10%はキーワードに関連があり、90%は関連がないことになる(ここでは、「ページがグーグルの検索結果に表示されていた」=「そのキーワードに関連がある」と想定している)。
次に、キーワードごとに「ページオーソリティ」と「言語モデル」を使って、各ページがどの程度そのキーワードと類似しているかを計算し、それぞれソートした(図中2つの表)。
最後に、それぞれのモデルで「類似している」とみなされた上位50件の「適合率」を計算した。ここでいう適合率とは、「ページオーソリティ」または「言語モデル」で類似度が高いとされた上位50件のうち、検索結果に実際に表示されていた上位50件が占める割合だ。
ドキュメント500件のうち10%は検索結果に表示されていたもののため、ランダムにソートすれば適合率は10%になる。この適合率10%がベースラインだ(画像下部のグレーのバー)。
結果は特筆すべきものだった。
「ページオーソリティ」で類似度を判断した場合 ―― 適合率はベースラインに非常に近かった。関連性の判断においては、ランダムに並べた場合とたいして変わらないが、いったん関連があると認識されれば上位50件をうまく順位付けできることがわかる。
「言語モデル」で類似度を判断した場合 ―― 適合率は100%に近い。言い換えると、言語モデルは500ページのうちどのページが検索結果に表示されるか判断するのはほぼ完璧だが、これらの関連するドキュメントを実際に順位付けするのはあまり得意ではない。
まとめ
クエリとドキュメントの間での類似度の処理は、過去の研究文献で十分に確立されている。こうした研究は、現代のあらゆる情報検索システムの基礎となっているため、検索エンジンでのウェブ検索においても、不可欠だ。そして、こうした処理は、グーグルのアルゴリズム変更の影響も受けない。
検索エンジンでは洗練されたクエリモデルとドキュメントモデルを使用するため、類似のキーワードを別々に最適化する必要はない。たとえば、「movie reviews」をターゲットとするページはすべて、「movie review」もターゲットになる。
SEOの仕事においては、で「関連性の処理」と「ランキングの処理」が概念上は分離されていることを利用できる。既存のコンテンツを作成したり変更したりする場合、まずは広範な関連キーワードに関係するページを作成することに専念しよう。その後で、検索結果の表示順位を上げることに重点を置くべきだ。
- この記事のキーワード
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を日本語訳したものです。

原文:「Determining Relevance: How Similarity Is Scored」 by Mat Peters (2013/06/12)




