Webサイトの完全なURL一覧の作成をラクにしてくれる6つの手段(ツール)
URLリストを作るための手段とツールをいくつか紹介する。サイト移行の準備やSEOの問題分析に役立ててほしい
2025年3月31日 7:00
この記事では、URLリストを作るためのツールをいくつか紹介する。「サイト移行の準備」「SEO上の問題点を分析」「404の調査」などを進めるときに役立ててほしい。
ウェブサイト上のすべてのURLを検索する必要がある理由はさまざまだが、何を検索するかは、具体的に何を目的としているかによって異なる。たとえば、次のような目的が考えられる:
- インデックス化されているすべてのURLを特定することで、カニバリゼーションやインデックスの肥大化といった問題を分析したい。
- 特にサイトを移行する場合、グーグルに認識されている現在のURLと過去のURLを収集したい。
- 404エラーになるすべてのURLを検索して、移行後のエラーを解消したい。
いずれのシナリオでも、1つのツールで必要なすべての情報が得られるわけではない。残念ながら、Google Search Consoleはすべてを網羅しているわけではないし、「site:example.com」での検索にも限界があり、そこからデータを取り出すのは難しい。
前述のようなニーズがある人は、ここで紹介する手法を使って、効率良くサイトのURLリストを作ってほしい。
手段1 古いサイトマップとクロールエクスポート
公開サイトから最近削除したURLを探している場合は、変更が行われる前にチームの誰かが保存した、
- サイトマップファイル
- クロールデータのエクスポートファイル
がないかチェックしてみよう。必要な情報が得られることも多い。
しかし、この記事を読んでいるということは、それもだめだったということだろう。
手段2 Archive.org
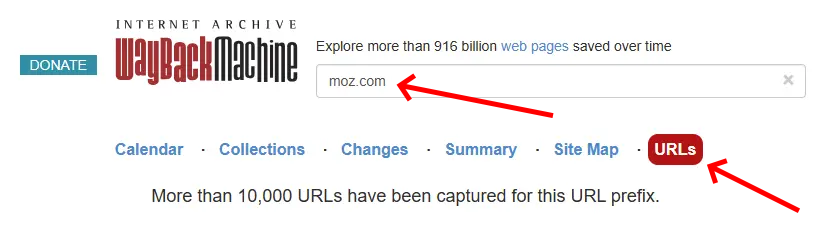
Archive.orgはSEOの作業に欠かせないツールで、寄付によって運営されている。あなたのサイトのドメイン名でArchive.orgを検索して「URLs」オプションを選択すると、最大1万件の登録済みURLにアクセスできる。
ただし、いくつか制約がある:
URLの制限 ―― 取得できるURLは最大1万件にとどまるため、大規模なサイトには不十分だ。
品質 ―― 多くのURLは、不正な形式のファイルや参照リソースファイル(画像やスクリプトなど)の可能性がある。
エクスポートオプションの欠如 ―― リストをエクスポートする機能が実装されていない。
エクスポートボタンがない問題については、Dataminer.ioなどのブラウザスクレイピングプラグインを使って対処できる。それでも、Archive.orgには前述のような制約があるために、大規模なサイトにとって完全な解決策にはならないかもしれない。
なお、Archive.orgには、グーグルがそのURLをインデックス登録しているかどうかが表示されないが、Archive.orgが検出しているということは、グーグルも検出している可能性が高い。
手段3 Google Search Console
Google Search Consoleを使うと、URLのリストを作成するうえでいくつかの貴重なソースが得られる。
[リンク]レポート:
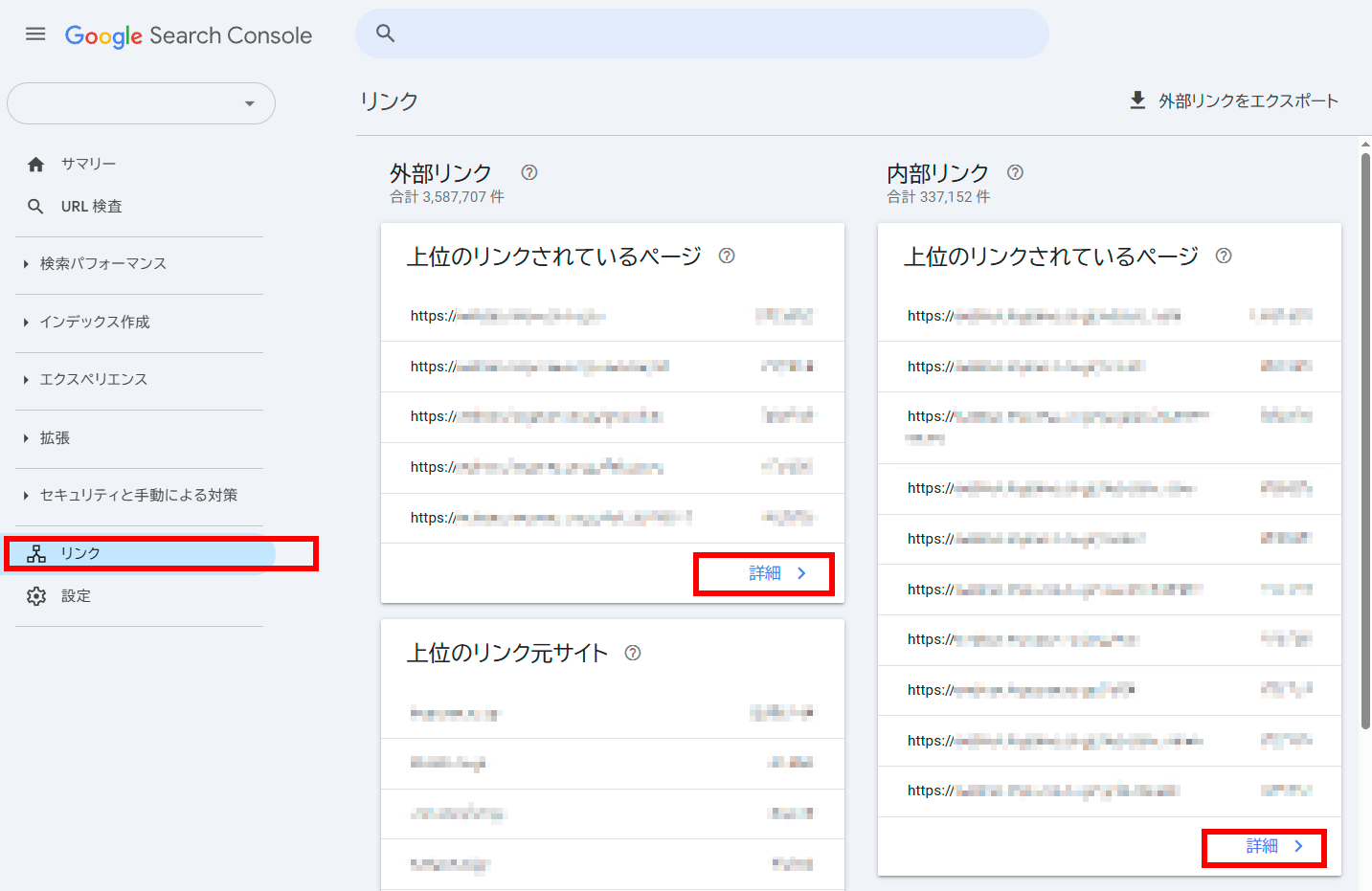
Moz Proと同様、Search Console「リンク」セクションでターゲットURLのリストをエクスポートできる。だが残念ながら、ここでエクスポートできるURLは1回あたり最大1000件までに制限されている。
また、リンクの各一覧ページではフィルタで表示内容を絞り込めるが、エクスポートにはフィルタが適用されない。そのため、ブラウザスクレイピングツールが必要になるかもしれない。ただしこれも、フィルタを適用しているURLの場合は1回あたり500件に制限されている。完璧とは言えない。
[検索パフォーマンス]>[検索結果]レポート:
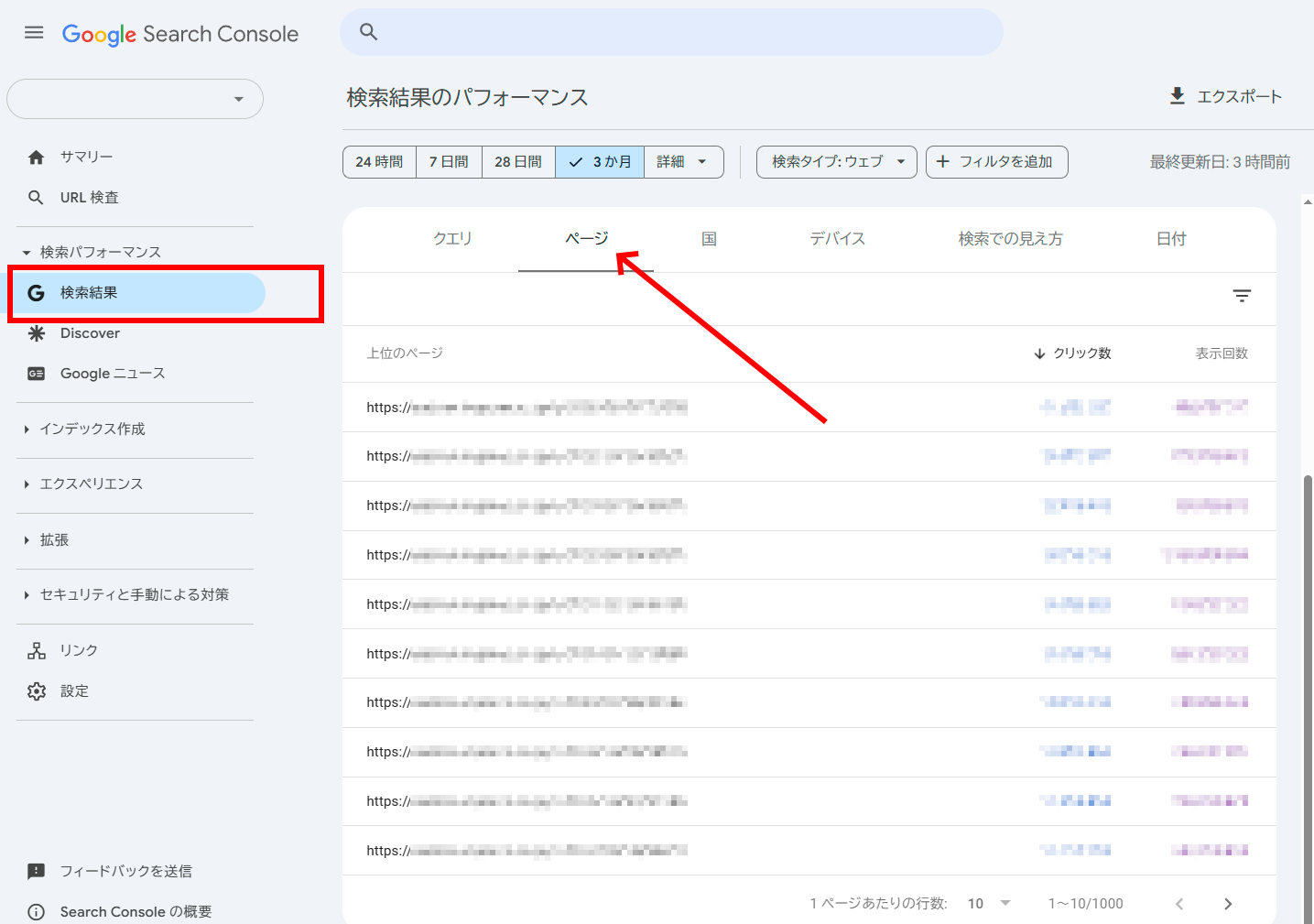
リストをエクスポートすると、検索インプレッションを取得したページのリストが得られる。エクスポートには制限があるが、大規模なデータセットにはGoogle Search Console APIを利用できる。
また、より広範なデータを簡単に取得できる無料のGoogleスプレッドシート用プラグインもある。
[インデックス作成]>[ページ]レポート:
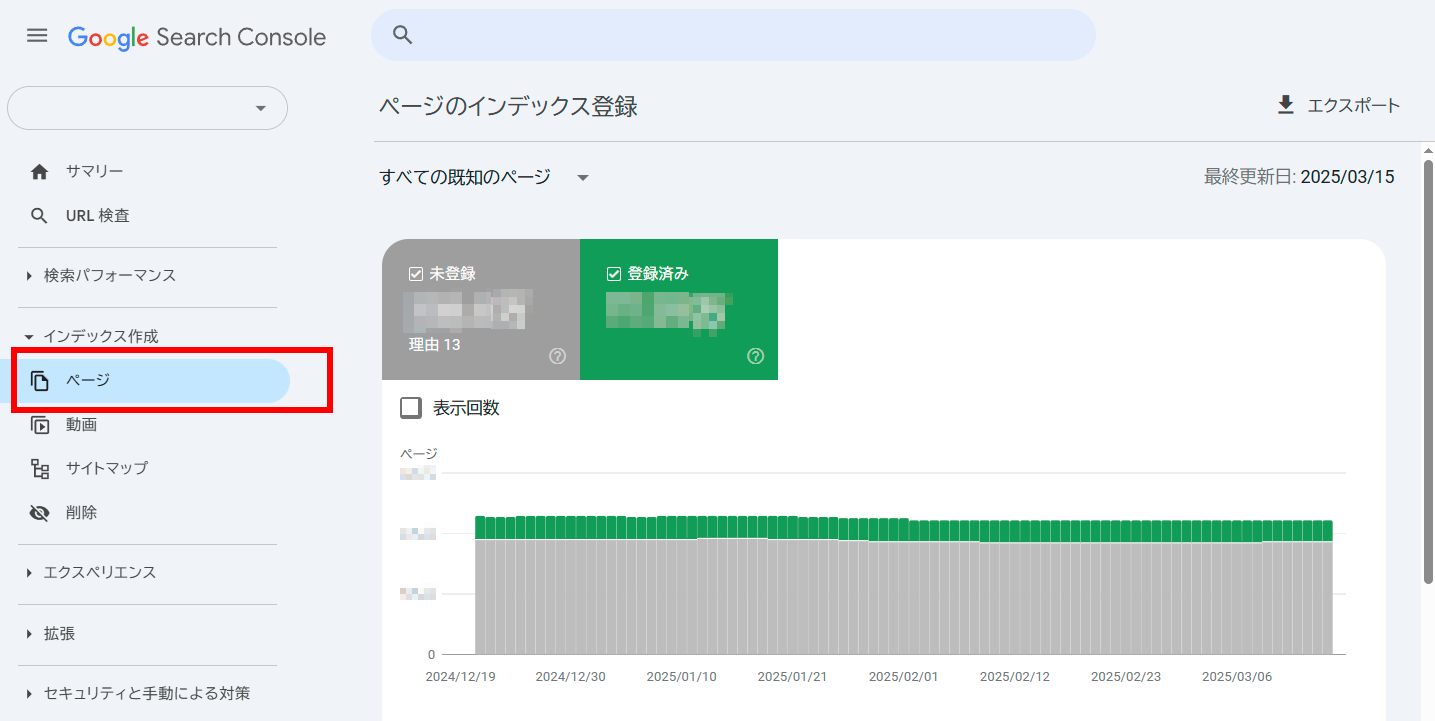
このセクションでは、問題のタイプ別にフィルタリングしたデータをエクスポートできるが、これも範囲は制限されている。
手段4 Googleアナリティクス
URLを収集するのに優れたソースとして、Googleアナリティクス4のデフォルトの[レポート]で[エンゲージメント]>[ページとスクリーン]を選択すると、上限10万件という十分な数のURLを取得できる。
もっと良いことに、フィルタを適用した別のURLリストを作成すれば、実質的に10万件という上限を回避できる。たとえば、ブログのURLのみをエクスポートしたい場合は、次の手順で処理するといい。
[レポート]>[エンゲージメント]>[ページとスクリーン]を表示し、右上のアイコンからデータ探索に切り替える。セグメントを追加する。
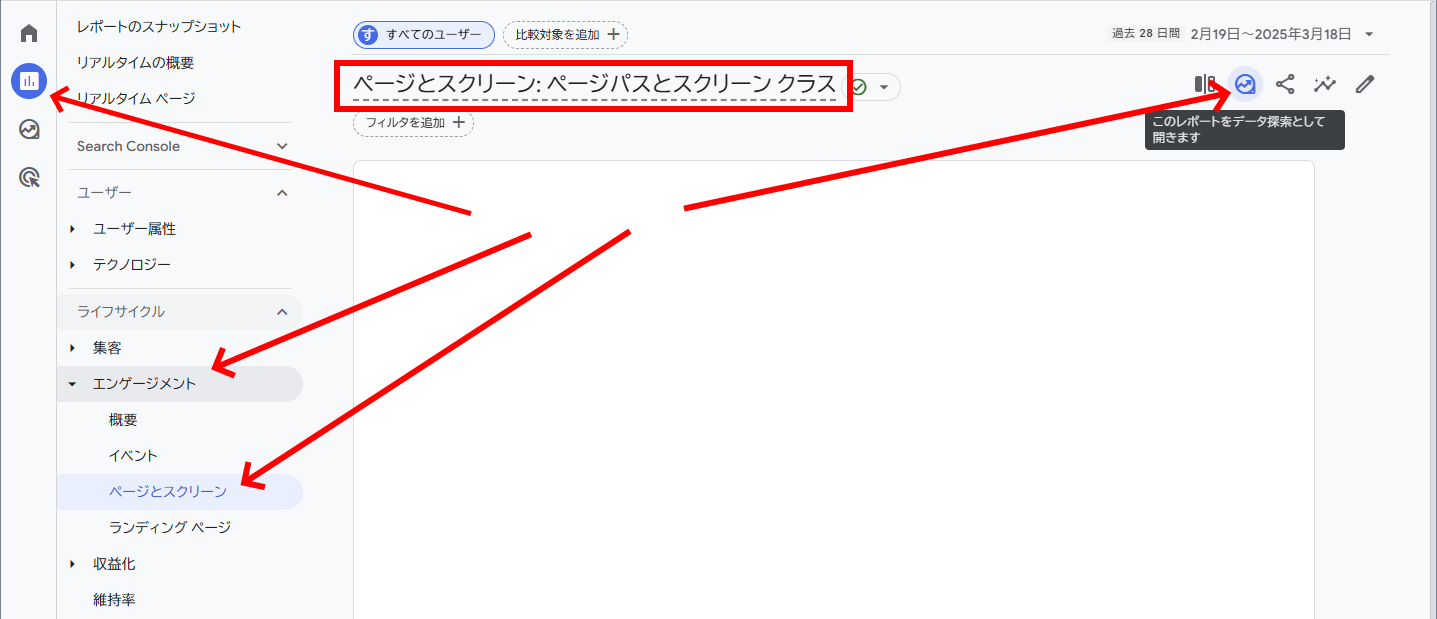
データ探索の画面に切り替わったら、左側のペインでセグメントを追加する。
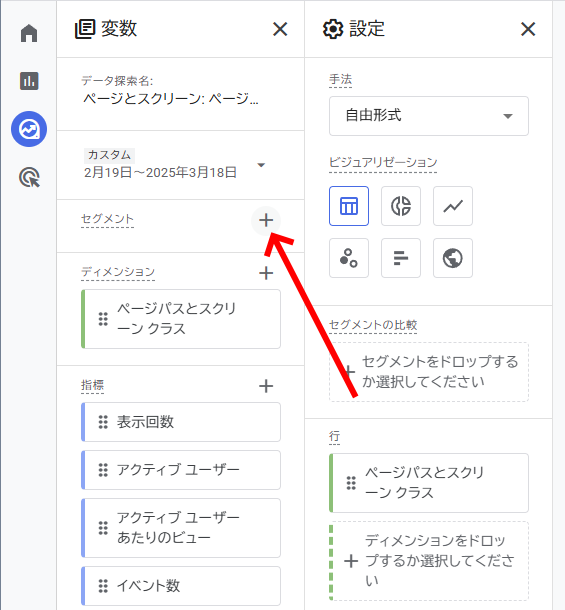
セグメント追加画面で、右上の[新しいセグメントを作成]をクリックする。
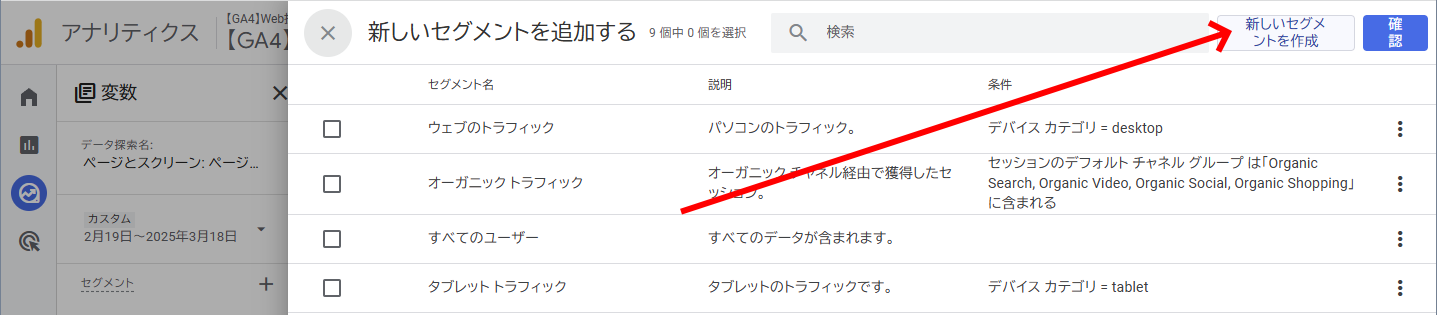
「/blog/」を含む「ページパス+クエリ文字列」など、より狭いパターンのURLでセグメントを定義する。
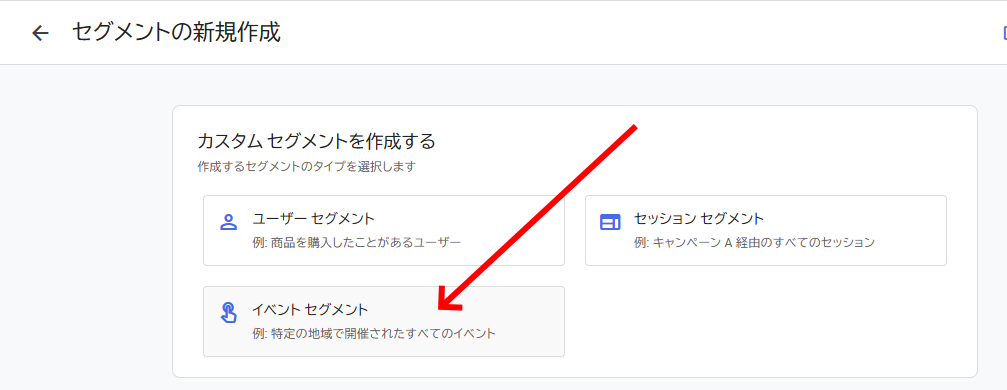
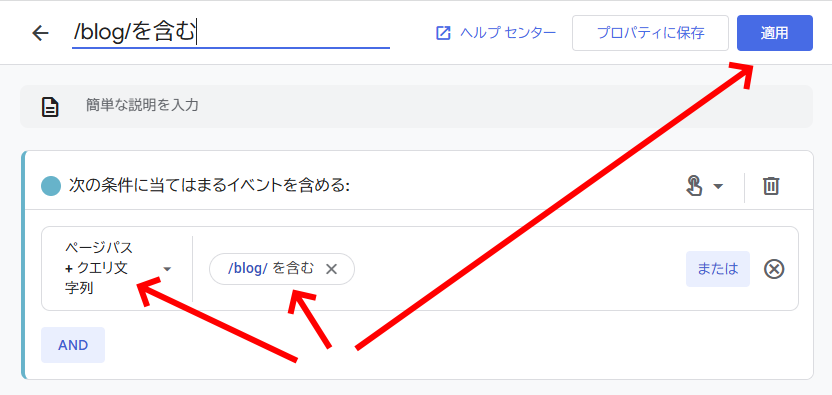
こうしたセグメントで全体を何分割かすることで、1セグメントのエクスポート数を10万件以下にできる。うまく分割していけば、サイト全体のURL一覧を作れることになる。
Googleアナリティクスで検出されるURLには、Googlebotが検出できないものや、グーグルにインデックス登録されていないものも含まれている。URLリストの作成という観点では重要ではないが、貴重な知見が得られる場合もある。
手段5 サーバーログファイル
サーバーまたはCDN(コンテンツ配信ネットワーク)のログファイルこそ、自由に使える究極のツールだろう。これらのログでは、記録された期間にユーザー、Googlebot、またはその他のボットがアクセスしてきたすべてのURLパスの完全なリストを取得できる。
ただし、次の点は考慮しておくといいだろう:
データサイズ ―― ログファイルは膨大な容量になる可能性があるため、多くのサイトでは直近2週間分などの限られたデータしか保持していないことが多い。
複雑さ ―― ログファイルの分析は、慣れないと大変な場合もある。とはいえ、この処理を簡単にするさまざまなツールもあるので利用してみるといい。
手段6 Moz Pro
通常、リンクを張ってくれている外部サイトを検索するには、リンクインデックスを使用するかもしれないが、これらのツールはその過程で君のサイトのURLも検出する。
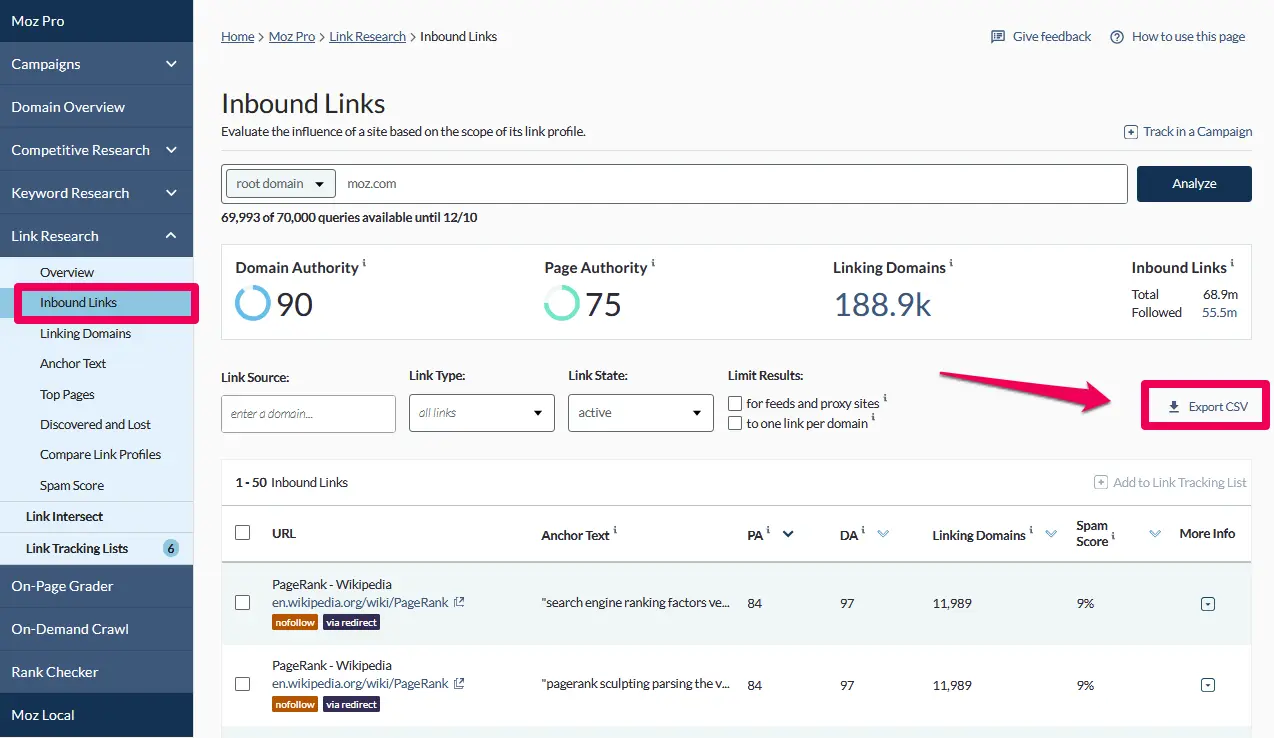
Moz Proの使い方:
Moz Proでインバウンドリンクをエクスポートすると、君のサイトにあるターゲットURLのリストをすばやく簡単に取得できる。対象が大規模なウェブサイトの場合、ExcelやGoogleスプレッドシートで管理するには手に余る量のデータをエクスポートすることになる。そのときには、Moz APIの利用を検討しよう。
注意すべきこととして、Moz Proでは、URLがグーグルにインデックス化または検出されているかどうかを確認することはできない点がある。ただし、ほとんどのサイトではMozのボットにもグーグルのボット向けと同じrobots.txtのルールを適用しているため、この方法は一般にGooglebotによる検出の可能性を測る代替策としてうまく機能する。
組み合わせて、健闘を祈る
これらのソースからURLを収集したら、次にそれらを1つにまとめる:
- 小規模なサイトならExcelを使う
- 大規模なデータセットならGoogleスプレッドシートやJupyter Notebookなどのツールを使う
すべてのURLが一貫して同じフォーマットになっていることを確認し、重複データをリストから削除する。
これで、現在、過去、アーカイブのURLを集めた包括的なリストの完成だ。幸運を祈る!
- この記事のキーワード
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「How to Find All Existing and Archived URLs on a Website」 by Tom Capper (2025/01/06)
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




