誰もがデータサイエンティストに!? データ分析の道しるべ「スキルチェックリスト」の活用法
データサイエンティスト協会三氏に「スキルチェックリスト」の活用法を聞いた。
2024年1月17日 7:00

高度人材の育成とデータ分析業界の健全な発展に貢献してきたデータサイエンティスト協会が、「データサイエンティスト スキルチェックリスト ver.5」および「データサイエンス領域タスクリスト ver.4」を2023年10月に発表した。協会の活動や最新版に新しく追加された内容などについて、スキル定義委員の佐伯諭氏(データサイエンティスト協会 事務局長)、高橋範光氏(ディジタルグロースアカデミア 代表取締役社長)、杉山聡氏(アトラエ シニアデータサイエンティスト)の三氏に聞いた。
データサイエンティスト協会の活動
――データサイエンティスト協会について教えてください。
佐伯: 2013年に発足し、データサイエンティストに求められるナレッジやスキルの定義、実態調査、情報発信、セミナー・トレーニング・検定プログラムの提供などを通じて、データサイエンティストを取り巻く環境を整備してきました。
データサイエンティストにはさまざまな定義がありますが、当協会では、「データサイエンス力、データエンジニアリング力をベースにデータから価値を創出し、ビジネス課題に答えを出すプロフェッショナル」と定義しています。
――会員にはどのような業界の人が多いのでしょうか?
佐伯: 最初はマーケティング業界とITベンダー業界の人間が中心でした。10年たつうちに、製造業、金融業、教育事業などさまざまな業界や、ネットベンチャーの人も増えてきました。
――新しい業界の人が増えたことで、協会の運営方針は変わりましたか?
佐伯: この5年くらいは、製造業や金融業といった事業会社の人たちが、データサイエンスやデータアナリティクスを用いて、会社で保有するデータをどう活用するか、さらに会社全体のDXをどう進めていくか、といった議論が非常に多くなっています。データサイエンティストの採用・育成・教育に関する課題も、コミュニティハブ委員会で活発に議論されています。
近年は経済産業省やIPA(独立行政法人 情報処理推進機構)と、ITスキル標準(IT人材に求められるスキルやキャリアを示した指標)について対話しながら、産業界が必要としているデータサイエンティスト像を明確にして、国に示してきました。結果として、国のAI戦略が策定されるなど、この10年で国としての取り組みがはっきり示されてきました。

スキルチェックリストの使い方
――「スキルチェックリスト ver.5」について教えてください。
佐伯: データサイエンティストに必要とされるスキルをまとめたチェックリストの第5版です。2021年に第4版として公開したデータサイエンティストの「ミッション、スキルセット、定義、スキルレベル」および「スキルチェックリスト」を、現在のビジネス環境や実態に合わせて全面的に見直しました。以下からダウンロード可能です。
データサイエンスがビジネスに役立つには、「ビジネス力」「データサイエンス力」「データエンジニアリング力」の3つのスキルセットが必要です。各スキルをそれぞれ「★」から「★★★+」までの「★値」で表し、合計で600を超える項目があります。
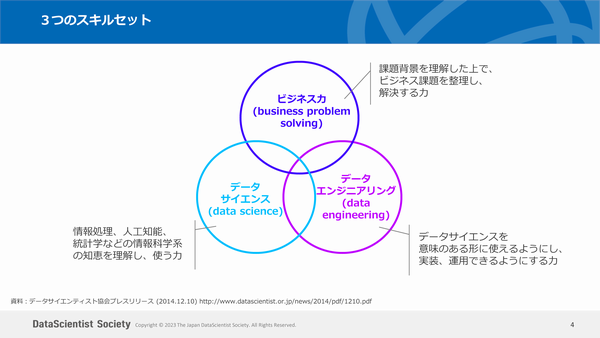
スキルレベルは、「シニア」「フル」「アソシエート」「アシスタント」の4つに分類しています。企業からは、「棟梁レベル(フル・データサイエンティスト)が足りない」という話がよく聞かれます。

――スキルチェックリストは、どのように活用されているのでしょうか?
佐伯: 以下のような使い方を想定しています。
データサイエンティスト協会では、データサイエンティストの実務能力と知識を有することを証明する試験である「データサイエンティスト検定™」を実施しています。リストを見れば、今、自分に何が足りていないか、何を身につけるべきかが分かります。
自社のデータサイエンスに必要な項目やレベルを選んで、自社の事業に合わせるという使い方をされています。また、スキルチェックリストと同時にタスクリストもIPAと協働して発表していますが、こちらはデータ分析プロジェクトの一連の流れが書いてありますので、自社の業務に当てはめたり、必要な箇所にドメイン知識を入れ込んだりするなどのアレンジをしています。
データサイエンスを学べる学部・学科が多くの大学で開設されています。そのシラバス(授業計画)策定にこのチェックリストやスキルセットが参考にされているようです。グローバルでも同じようなリストが公表されているので、それと比較しながら、具体的な学習時間などを決めることができます。
最新版の目玉はAI利活用に関するスキルの定義
――第5版で大きく変わったのはどこですか?
高橋: 「AI利活用スキル」を追加し、69項目を定義したというのが、一番大きな変化です。活用スキルと背景理解・対応スキルに大別し、計9つに分類し、ハルシネーション(事実に基づかない情報をAIが生成する現象)、ファインチューニング(AIの追加学習)、異なるデータ種類を統合処理するマルチモーダルAIなどの実践スキルをレベル分けしたうえで定義しました。
実務に即して説明します。たとえば、従来であれば、Webサイトにチャット機能を導入する場合、Web担当者(データの準備とメンテナンス)とシステム担当者が必要だったと思います。
生成AIを導入すると、FAQのデータをとりあえずサーバに置いておけば、勝手に引っ張ってきてチャットツールが作れる。その場合、生成AIを使ったチャットツールをWeb担の人たち自身が作り、データメンテナンスとツールの管理をするようになりますので、彼らにもAI利活用スキルが必要になるだろうということです。
ECサイトは、作り方が根本的に変わるでしょう。通常、ECサイトではユーザーが製品を検索します。それが、ゆるいニーズで検索したり、あるいは検索するまでもなく、行動履歴を参照して「これが必要ではないですか」とレコメンドされたりするようになる。A/Bテストはもっと頻繁に行われ、2種類ではなく、生成AIが作成したよりパーソナライズされた画像や広告を出し分けるようになるでしょう。

杉山: 弊社では、Greenという転職情報サイトを運営していますが、すでにかなり生成AIや関連技術を使っています。曖昧なニーズのキーワードで高い精度で検索できたり、ユーザーの行動を基にどのような求人に興味があるかを判断したりしています。
これまでも、「Aの募集記事を見た人はBも見ている。だからAを見た人にはBも出そう」というレコメンドはありました。そのサイトにおける多くのユーザーの行動履歴を蓄積して、傾向を見つけてレコメンドするというものです。この場合、比較するためのさまざまな技術をたくさん知っていて、該当タスクにはどれとどれを組み合わせればいいか理解して、いろいろ試してみるというデータ分析の専門スキルが必要でした。
しかし、LLM(大規模言語モデル)の登場で、機械が文章の意味を理解するようになりました。「この募集記事を読んだということは、この求人と似ているBとCにも興味ありますよね」という感じで、行動履歴の蓄積なしでレコメンドが出せるようになっています。
1回の閲覧で精度の高いレコメンドが出せるのであれば、もはや検索すら必要なくなります。そもそも、転職活動のはじめの段階では、自分が何を求めているのかよく分からないですよね。そういう言語化できないところをサポートしつつ、検索するというより、「あなたはこれを求めているのではないですか」と言ってくる。そういう方向に向かっていく予定です。
ただし、従来のスキルが不要になったわけではありません。生成AIの登場で、手元にあるデータを全部入力すれば、何か特徴を見つけてくれるようになり、楽に1歩目を踏み出せるようになりました。1歩目で精度の高い分析結果が出ればそれでOKだし、イマイチなら、従来の手法を組み合わせてみるという手順になるので。また、業界ごとのドメインに関する知識は相変わらず必要です。それがなければ、ビジネスに役立てることができません。

協会が目指しているのは、1億総データサイエンティスト
――棟梁クラスの人材不足を補うために、スキルチェックシートを活用してリスキリングしたデータサイエンティストが入ってくるという想定でしょうか?
佐伯: 転職前提ではありません。棟梁にはドメイン知識が必要なので、ドメインにずっといる人なんです。
高橋: データサイエンティスト協会が目指しているのは、1億総データサイエンティストです。要するに、「データサイエンティスト=数学やデータに詳しいスペシャリスト」という発想から、まず脱却しなければいけません。
現在はどのような業種であれ、あらゆる業務でデータを使っています。誰もがまずは見習いレベルのデータサイエンティストでなければならないし、棟梁というのはデータを使うだけでなく、うまく使う環境を作る人のことです。そしてデータは業務に根ざしているので、業務がわかっていないとデータサイエンティストとしての活躍はできません。
「未経験者がAIを使ってここまでできるのか」という衝撃
杉山: リスキリングが転職前提ではなく、社内の人が学んでスキルアップしていくという話で、最近いい事例がありましたので紹介します。
弊社では、4年くらい前から機械学習とディープラーニングの勉強会を社内で実施しています。半年間みっちり勉強した後で、1ヵ月かけてフリーテーマで分析してもらって完了なのですが、今年の成果物の質が高く、即座に実務で活用できるレベルだったのです。
参加者はエンジニアではなく、カスタマーサクセス(サービス導入後、顧客に伴走して成果を出す支援をする部署)のメンバーが2人と、営業企画のメンバーが1人。参加メンバーは、半年前までデータ分析もプログラミングもやったことがなかったのですが、一番ドメイン知識を持っている人たちです。その3人が半年勉強して、コーディングやエラー対処等の難しいところはChatGPTなどの生成AIをフル活用し、分析してくれた結果がとても面白くて、よい示唆を与えてくれるものでした。
はっきり言って、同じテーマで分析したら私は勝てないと感じました。もちろん、単なる分析力は私の方がずっと高いですが、ドメイン知識の深さが段違いなので、同じデータを見たときの思考の深まり方や知見のレベルが全然違いました。「たとえ分析は初心者であっても、ドメイン知識を持つ人がAIを使えばここまでできるのか」というのは衝撃でした。
現場の知識を持って、現場のことを愛している人が、自らデータ分析を行う。細かいことや難しいことはAIに聞いて直してもらいつつ、週に1回30分ずつ、旧来の専門家が出てきて、結果の解釈や分析の方向性だけを整えるサポートをする。現場でのデータ・AI利活用としては、これが理想形の1つかもしれません。
そのうち、元々現場にいた人が、分析が面白くなってプロのデータサイエンティストになることがあるかもしれません。数学好きで分析のプロになった人より、ビジネスをやっていて分析が面白く感じるようになった人の方が、今の時代に合うでしょう。そうやって棟梁レベルのデータサイエンティストが増えていく時代かなと思います。
スキルチェックリスト・タスクリストを活用して、AI人材を育てるには?
佐伯: 確かに、データがあるからといって、アウトソーシングでデータサイエンティストに分析してもらっても、目を見張るような成果は得られないことが多いです。現場のドメイン知識は超重要ですよね。
高橋: データサイエンティスト協会としては、気づいていない人にきちんと気づいてもらえるように発信していく。何が必要なのだろうと困ったときに、スキルチェックリストを活用してもらうという感じだと思います。
それを携えれば、杉山さんのお話のように、会社の中で今まで誰もやっていなかった分析をして、新たな成果・価値を生み出せる人材になる人もいるでしょう。中には、「だったらもう自分で作るよ」と独立する人も出てくると思います。スキルチェックシートは、独立するときに何を身につけたらいいのかという道しるべにもなる。キャリアの選択肢が広がると思います。
杉山: 今、あらゆる企業が生成AIの流れに乗り遅れまいとしています。しかし何から手を付けていいか分からないというとき、タスクリストを上から順番にやっていけば、AIの検討・PoC・実験がひと通りできます。カバー領域が広めのリストなので、自社に必要なものをピックアップして自社流にアレンジすれば、誰でも始められるタスクリストキットになっています。
あとは、生成AIを活用するために勉強すべきことが分からないなら、AI活用のスキルチェックリストを順番に見ていけば、かなり戦える人になると思います。
このタイミングで、ここまで整理されたものが出ているのは、世界的にも珍しい。しかも日本語です。我々はこの改訂に命をかけています。すごく大変でしたが、とても素晴らしいものができたので、ぜひ活用していただきたいです。
また、スキル定義委員会でこの改訂に参加してくれる方も募集しています。すごく大変だけれど、楽しくて価値があって勉強になりますので、参加をお待ちしています。
バックナンバー
この記事の筆者
筆者の人気記事
Webサイト全体HTTPS化(常時SSL)の流れはもう止まらない
2016年2月1日 7:00
ホームページ・ビルダー17でWordPressサイトはどこまで作り込める? 制作会社の仕事は奪われる?
2012年10月5日 12:00
インバウンドマーケティングの本当の姿とは、高広伯彦氏が15の疑問とともに語る
2014年1月8日 9:00
要件定義とは? Webサイトリニューアル成功のカギを握る「要件定義」の目的と作り方を紹介
2019年3月20日 7:00
ユーザーの検索意図を狙うSEOの最新動向を住氏が解説! 売れるサイトにするための4つのポイントとは?
2019年1月16日 7:00
GoogleのHTTPSサイト優遇方針で待ったなし! Webサイト常時SSL化の効果と実装ポイント
2016年6月22日 7:00




