検索エンジン会社の人間と善良なるサイト運営者(人が好すぎるほどの善玉中の善玉)は、検索で高いランクを獲得するには、リンク価値の高いすばらしいコンテンツとリンクがあれば、それで十分だと言うけれど、実際には、彼らの言うとおりの特徴を備えていながら、重要なキーワード(大量のトラフィックをもたらす語句)で、検索結果に現れてこないサイトが数多くある。検索ランキングに入るのが言うほど簡単なことで、高いランクに値するページがすべて、連中の言う要素を備えているのなら、僕らSEO屋なんて必要ないだろう。

現実に目を向けてみれば、検索エンジンだって決して完ぺきじゃないってこと。彼らにしても、僕らの意図を汲み取って、僕らの検索に最も適合するページを見つけようと、けっこう悪戦苦闘しているんだ。
ではなぜ検索エンジンは、常に完璧な関連性を持つ検索結果を返せないのか? その理由をここで挙げてみよう。
関連性は主観によって変わる。
最大の問題はこれだ。たとえば、カナダで「コーヒー」と検索して、最も関連性が高いとしてTim Hortonのウェブサイトが出てきたとしよう。確かに、これはこれで意味を成す。なぜなら、Tim Hortonはカナダで最も人気のあるコーヒーチェーンだからね。だけど、シアトル在住者にとってはどうだろう。スターバックスが最も関連性の高い結果になるんじゃないだろうか。
次に「49ers」と入力して、フットボールチームを検索してみよう。だけど同じ「49ers」でも、歴史家ならカリフォルニアのゴールドラッシュに関する研究資料を探している可能性だってある。
さらに別の例を挙げれば、今日は「bones(骨)」という検索で、犬用の骨を買う店を検索し、次の日は同じキーワードで、前夜に見逃したテレビ番組「Bones」のエピソードを検索するかもしれない。
いったいどうやれば、検索エンジンがこの種の曖昧さを読み解けるのだろう? 読心術でもできればいいんだろうけどね(笑)。
これまでのところ、検索エンジンが辿りついた最良の方法は、検索ユーザーの特質評価とパーソナライズ化検索を利用したアプローチだ。検索エンジンがユーザーをうまくプロファイルできればできるほど、検索結果の関連性が向上する可能性も高くなる。ただ言うまでもなく、この方法についてはプライバシー侵害を不安視する声が多く上がっている。
自然言語による検索の問題。
MySQLデータベースエンジンは、「SELECT first, last FROM employee WHERE last = "Smith";」というようなSQLクエリを与えた場合、正確に関連するレコードをすべて抜き出してくる。この場合は、SQL構文という形式化した文法があり、曖昧さはない。
だが一方の検索エンジンは、「who has smith as last name in chicago(シカゴでラストネームがsmithの人は誰)」とか、「smith last name chicago(smith ラスト ネーム シカゴ)」といったような検索を受け取る。そう、検索エンジンを使うときの検索は自然言語、つまり僕らが普段使っている言葉を使うんだ。
同じことを表現するにしても、何通りもの言い方がある。コンテキストにその人の癖などなど、変化は多様だ。検索エンジンのユーザー入力コンポーネントは、インデックスを調べる前に、まずこうした検索の曖昧さを除去して、より形式化したものに変換しなければならない。
貧弱な検索。
検索ユーザーの中には、現実世界でも自分の言いたいことをうまく表現できない人が多い。それが、検索エンジンに検索を出すとなればなおさらだ。彼らは掃除機のことを「吸い取り器」と表現したり、クリーニングサービス業者をオンラインで見つけられなかったりする。もっとひどい場合は、スペルを間違え、検索エンジンにとってこの問題をより「おもしろい」ものにしてしまう。
類義語の存在。
これはもう1つの難題だ。世の中には、「車」と「自動車」のように、同じ意味を持つ言葉が存在する。何かを検索する場合、自分が入力した語句がそのまま出てくるページはもちろん、関連性があるなら、同じことを意味する別の語句が出てくるページも表示してほしいと思うだろう。
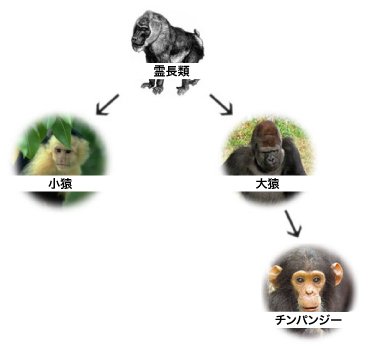
たとえば、「小猿(monkey)」で検索する場合、その時求めているのは「小猿」を含むページの検索結果だけでなく、おそらく「チンパンジー」や「大猿(Ape)」という語句が出てくるページもほしいんじゃないだろうか。あるいは、もう少し厳密に検索する場合なら、たしかにチンパンジーは霊長類だけど、小猿ではないので、チンパンジーに関するページは出てこないでほしいかもしれない。こうした細かなことが頭に浮かぶ検索ユーザーは少なく、そのために検索エンジンは大変な苦労を背負い込むことになる。
多義語の存在。
また世の中には、文脈によって意味の変わる言葉がたくさんある。たとえば「wood」で検索する場合、それは、木でできた何かついて語っているページを求めているのかもしれないし、木がたくさん生えている場所のことを指しているのかもしれない。適切なコンテキストがなければ、人間にだってその答えを言い当てるのは困難だ。だとすれば、検索エンジンにとってそれがどれほど大変なことか想像できるだろう?
検索エンジンの能力の不完全性。
僕が以前に書いた適合性フィードバックに関する記事を補足し、この問題をもっとうまく説明するため、関連する考え方を少し説明させてほしい。それは精度(検索結果における適合項目の割合)と再現率(適合する母集団に対し検索で抽出できた割合)の考え方だ。
精度と再現率は、情報抽出の研究者が検索エンジンの能力を評価するときに使う測定基準だ。検索ランキングのアルゴリズムが、どれほど洗練されているかということは重要ではなく、結局本当に重要なのは、ユーザーが検索結果に満足するかどうかだ。精度というのは、検索結果全体のうち関連する結果の割合を指し、検索エンジンの効率の良さを示すものだ。関連性の低い結果が多くなると、精度は下がる。また再現率とは、検索エンジンが関連性を認識して抽出すべきものを、どれくらい完全に取り出せたか測る指標だ(もちろんこれは、研究者が本来関連する結果の総数をあらかじめ知っていることが前提)。検索結果の中で関連する結果の数が、あるべき総数を下回れば、再現率は下がる。
検索エンジンが関連する文書をすべて見つけ出し、無関係なものは一切含めない(100%の精度、100%の再現率)、これが理想だ。しかし精度と再現率は、一方が上がれば他方が下がる関係にあり、実際問題としてこれは不可能だということがわかっている。
抽出能力の実験に基づく研究から、再現率が増加するに伴い、精度が低下する傾向にあることがわかった。
「精度と再現率の二項対立」より。
しかし幸いなことに、検索ユーザーの多くは精度の方を重視しがちで、上位10件の検索結果においては特にその傾向がある。検索結果ページの最初の数ページを見ないで飛ばしてしまう人は、ほとんどいない。品質評価による適合性フィードバックは、精度を高める上で優れたアプローチだ。この手法では、品質評価によって最も関連性の高い文書を選び、その情報を基に元々の検索を洗練して、大半のユーザーにとってより良い結果を返すことができる。
スパムの存在。
検索エンジンは、「品質シグナル」あるいはウェブページから自動的に推測できる測定基準によって、関連するページを見つけ出す。ところが、ひとたび悪玉SEO屋たちがこうしたシグナルを嗅ぎつけると、それを模倣し始める。これは、検索エンジンにとって頭の痛い問題だ。いずれ、偽の品質シグナルをでっち上げるのはどんどん困難になっていくと思うんだけど、だからと言って不可能になるとは言い切れない。人間なら簡単にスパムを見分けられるけれども、コンピュータにとっては、非常に困難な作業なんだ。
こういったことを知るのは大事なことなんだろうか?
これは興味深い点を突いているから、とても重要な話なんだ。検索エンジンは認めたくないだろうけど、検索エンジンにとって僕らSEOは必要な存在なんだよ。上で書いたとおり、関連性は主観の問題だ。受け身のアプローチをとり、検索エンジン側が関連性があると考える検索において、自分のウェブサイトが品質評価をパスするものと当て込む姿勢で満足だろうか? それとも、積極的に働きかけて最高のキーワードを見つけ出し、そのキーワードを自分のコンテンツに織り込み、リンクを得て、さらに高いランクを獲得しているウェブサイト(ウェブの権威サイト)を入念に研究し、同じようにできる方法を探る方が良いと思うだろうか? 僕なら、積極的に働きかける方を選ぶね。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




