「Big Dataをプロに教わろう」 第25回Web広告研究会フォーラムレポート(前編)
「第25回WABフォーラム」前半の様子をレポートする。
2012年4月23日 9:00
ビッグデータは単なるバズワードか、イノベーションか
技術者と広告主から見たビッグデータの現状と活用法
公益社団法人日本アドバタイザーズ協会Web広告研究会は2012年2月29日、東京都中央区時事通信ホールで「第25回WABフォーラム」を開催した。
WABフォーラムでは毎年、Web広告研究会宣言(以下、WAB宣言)が発表されるが、今年の宣言は「Cooking Big Data ~マーケティングの新しい時代へ~」を発表。 WAB宣言を受けた2つのパネルディスカッション、「Big Dataをプロに教わろう」と「広告主が考える今年のマーケティング注力テーマは?」も行われ、2012年のWebマーケティング戦略を予測する有意義な議論も交わされた。
2012年Web広告研究会宣言 「Cooking Big Data」

代表幹事 本間 充
第25回WABフォーラムでは、最初にWeb広告研究会代表幹事である本間充氏が登壇し、開会の挨拶とWAB宣言を発表した。本間氏は、「2012年1月4日から日本アドバタイザーズ協会が公益法人となったため、下部組織であるWeb広告研究会も今年は公益性の高い活動をしていく
」ことを明かし、会員社の活動はこれまでどおりだが、活動内容のより多くを外に向けて発信していく必要があるとした。
また、広告費全体が下がる傾向にある中で、インターネット広告費がいまだ右肩上がりとなっていることに触れたうえで、インターネットの歴史からトリプルメディアまでの流れ、デジタルメディアのデータ分析、ソーシャルメディアやクラウドの登場などを説明した。そして、「データの分析は、Webマーケティング関係者がリードできる領域であり、Webでの知見が他のデジタルメディアでも活用できる
」とまとめ、2012年のWAB宣言「Cooking Big Data ~マーケティングの新しい時代へ~」を発表した(WAB宣言の詳細)。
最後に本間氏は、
Webから端を発したデータがこれから多くの領域を飲み込もうとし、Webのマーケティングメンバーが考えてきた論理が他のメディアにも広がろうとしている。
これからの1年は、Big Dataを考え、学びながら活動していきたいと考えているので、皆さんの感想やアイデアをフィードバックしてほしい
と挨拶し、WAB宣言の発表を終えた。
テクノロジー、分析のプロが教える ビッグデータの真実
続く第一部では、「Big Dataをプロに教わろう」というテーマで、トランスコスモス株式会社の萩原雅之氏をモデレータに、株式会社野村総合研究所(NRI)の城田真琴氏と日本オラクル株式会社の龍野智幸氏の2人をパネリストに、パネルディスカッションが行われた。

エグゼクティブリサーチャー
萩原 雅之氏
萩原氏は、「第一部はソリューションを提供する側、第二部は利用する側から、ビッグデータについて議論していきたい
」と話し、「システムベンダー主導でバズワードとなっているビッグデータと、我々広告・マーケティング業界との接点を見つけていきたい
」と前置きする。そのうえで、ビッグデータという言葉は話題となっているが、まだまだソフトウェア会社やSIerが中心となっているため、今回のWAB宣言が広告・マーケティング業界でもビッグデータを考えるキッカケになればよいとした。
続いて萩原氏から紹介された城田氏と龍野氏は、「ビッグデータは単なる流行か、本質的な変化なのか」という質問に答えていく。

Fusion Middleware事業統括本部 ビジネス推進本部 本部長
龍野 智幸氏
龍野氏は、
IT業界は3~4年の間隔で、Web2.0、クラウド、ソーシャルといったバズワードを生み出しながら業界を牽引している。
しかし、必ずしも嘘八百や夢物語を並べているわけではなく、ビジネスやその先にいる人たちにつながらないものではない。バズ的な要素はあるが、それによってイノベーションが生まれると考えている。
ビッグデータへの対応を誤るとオラクルにとって脅威となる。真摯に、前向きに、率先して向かっていく必要があると考えているし、その先の皆様のビジネスをリードしていくというスタンス
と話した。

イノベーション開発部 上級研究員
城田 真琴氏
一方、城田氏は「ITアナリストとして中立的な立場からテクノロジの動向調査やベンダーの戦略分析、ユーザー企業のIT利用動向調査を行っている
」とパネルを交えながら話し、現在はクラウドやビッグデータに注目していることを明かした。
また、NRIはビッグデータを使った事業をすでにいくつか行っており、スマートシティの分野やインターネット業界、ソーシャルメディア業界、通信業界、小売業界、金融・保険業界などの多くの活用領域でビッグデータは多岐に使われていると城田氏は説明した。
「ビッグデータという、曖昧でわかりづらい言葉を説明してほしい
」と萩原氏に振られた龍野氏は、ビッグデータの定義として4つの要素「大量であること」「加速度的であること」「データの多様性があること」「価値があること」を示した。このうち、3つの要素に該当すればビッグデータになると説明する龍野氏は、
実は、日本ではiモードなどで大量の多様性のあるデータが加速度的に価値を生み出すことが行われていたが、米国ではスマートフォンやソーシャルメディアの登場でこれらの要素に気づき、価値=金になるから盛んにビッグデータという言葉が言われ始めたように感じている
と話した。
さらに、龍野氏は「ビッグデータの話になると、構造化データや非構造化データといった言葉が飛び交うが、これらの言葉は理解しなくてもかまわない
」と話を続ける。
要するに、従来のように関係性がハッキリしている氏名、年齢、職業などのデータ(構造化データ)だけでなく、Twitterのつぶやきや画像のような、ひと目では関係性がわかりづらいデータ(非構造化データ)も扱われるようになり、一瞬のうちにテラバイト(10の12乗バイト)からゼッタバイト(10の21乗バイト)にまで加速度的に膨れ上がることがビッグデータの特徴だというのだ。
ビッグデータの価値は 現状分析よりも次の行動予測にこそある
前述のように、日本では以前からビッグデータがあったと話す龍野氏は、1996年から2006年までの情報量と情報消費量の資料を示しながら「10年で情報量が532倍増えているのに対し、選択可能な情報量は64倍しか増えておらず、その情報をすくい取る力が6.6%から0.8%に下がっている
」と説明する。
このように、ビッグデータに最近注目しはじめた日本と、前述のように早くから価値に気づいていた米国などでは、対応がまったく違うというわけだ。
日本に比べて貪欲な米国、欧州、中国などは、データをいかに金に変えるか効率一辺倒で考えてくる。
たとえば、日本ではアクセスログ解析や効果測定などを行うのが好きだが、グローバルな流れでは、ユーザーの行動を“フォーカス”するのではなく、行動によって次に何が起こるかを真剣に考えて効果を“予測”する、というのがビッグデータの特徴である
と龍野氏は説明した。
城田氏は、「なぜ今、ビッグデータなのか」という観点から話を始め、「ソーシャルメディアや会員カード、あるいはWebクリックストリームといったデータをしっかり分析していくこと
」と話す。
顧客の声を傾聴しようという話は以前から出ており、グループインタビューやアンケートなどが行われているが、これでは模範的な回答しか得られず、実際の購買行動にはつながらないこともあると城田氏は指摘する。
一方、ソーシャルメディアではユーザーの本音を得ることができ、大量のデータを収集できる。会員カードについても、これから何を買うかではなく、実際にどのような属性の人が何を買っているかをきちんと分析できるというわけだ。
米国では、DataShiftという、自社のサービスや商品について、Twitter上でのつぶやきをリアルタイムで拾うサービスなども登場している。たとえば、チェーン店であれば、ユーザーがどの店舗でつぶやいているかを収集し、それらのつぶやきから店舗ごとのサービスや対応を調べ、サービス向上につなげることができるという。そのためには、これには大量に流れているテキストデータを分析する高い技術が必要だ。
テキスト分析の技術の例として城田氏は、大量のデータ処理を可能にするオープンソースのソフトウェア基盤「Hadoop(ハドゥープ)」も紹介している。クックパッドでは、1年分の膨大なサイト内の検索キーワード分析に7,000時間かかると見積もっていたが、Amazonのクラウド上のHadoopを使うことで処理が30時間で完了したという。「何の根拠もなくビッグデータが騒がれているのではなく、今までできなかったことができるようになり、マーケティング業界に大きなインパクトを与えている
」と城田氏はまとめた。
これを受けて萩原氏は、
以前からデータ分析が必要という話はあったのに、なぜ今になってビッグデータが注目されるようになったのかは、それらを分析できる時間やコストが下がってきたことが大きい
と話した。
マーケッターとエンジニアの 壁を取り除くことが必要
続いて萩原氏は、広告・マーケティング業界からみたビッグデータの可能性がある領域として、「オンライン広告管理、アクセス解析、効果測定」「顧客データベース活用、ダイレクトマーケティング」「モデル化、売上予測、需要予測」「ソーシャルリスニング(マーケティングリサーチ、CRM)」の4つを挙げる。
そのうえで、
大量のデータ(非構造化データやリアルタイムデータ)をいかにマネジメントしていくかが大切。WAB宣言にビッグデータという言葉が入ったように、いろんな人がデータドリブンの考え方で活動していくということが大切になるだろう
と話した。
データの活用ついて、広告主側の企業内ではどのように認識されているのか、城田氏は、
ビッグデータはマーケティングと相性が良いと思っているが、我々のようなSIerは、企業の情報システム部門と話をしている。
情報システム部門では、技術は理解されても使ってはくれない。マーケティング部門では、使いたいと興味を示すが技術を理解してくれない。
この2つの部門をつなぐことが非常に難しい
と答えた。
龍野氏は「オラクルがWeb広告研究会の会員となって、最も楽しみなのは、マーケティング部門の方に今何ができるかを話して、何をしたいのかを聞けること
」と話しを続け、
現在のオラクルの技術では、1秒間に90万件のつぶやきをリアルタイムに分析することが可能。数秒でWebを離れていく人をリアルタイムに分析する技術があり、NRIのようなそれを組み立てるところと一緒になれば、やりたいことが可能になる技術がすでにあることを知ってほしい
と話した。
それに対し、萩原氏は「SIerがデータサイエンティストやアナリストを顧客に派遣するということをよく聞くが、それは主流となっているのか
」と質問する。
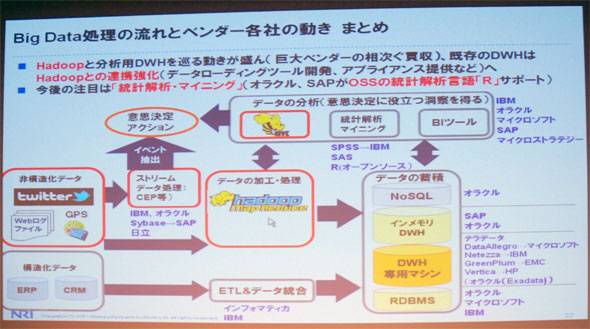
城田氏は、ビッグデータの処理の流れとベンダー各社の動きというパネルを示しながら、
ベンダーによって立ち位置は異なるが、ユーザーがほしがっているのはデータを蓄積する箱ではなく、そのデータを統計解析し、分析すること。ユーザー側にその力がなければ、ベンダー側で育成して提供するという流れは出てきていると思う
と話した。
萩原氏は「先ほどエンジニアとマーケッターでは使う言語が違うという話が出てきたが、うまくやるにはどうすればいいか
」と龍野氏に質問する。
龍野氏は、
我々がWebマーケッターの方にアクセスできるデータソースの数を聞くと、だいたい4~5つと答えが返ってくる。しかし、情報システム部門に聞くと社内には数十以上のデータソースがあることが多い。会社の中のすべてのデータをまとめればビッグデータになり、Webマーケッターはそれを活用できる
と説明した。
たとえば、ある商品に不具合があってWebが炎上しても、顧客データしか持っていないWebマーケッターは炎上する理由がわからない。そこで、設計や開発などのすべてのデータを全社員に公開し、気づきをフィードバックする仕組みを作ることで、ラインを見直したり製品不具合率を下げたりすることができたという。
一方で、
会社の中には、実はビッグデータが存在しているが、情報システム側と現場側の会話がうまくいかず、組織の壁もある。我々はこれらが円滑にコミュニケーションできるようにしたり、組織間のハブになりたいと考えているが、これをブレークスルーしない限り、マーケッターが情報システムに精通している欧米には抜かれてしまうと感じる
と龍野氏は話した。
城田氏も、
クックパッドの例にもあるように、ビッグデータをうまく分析するためには技術の力が不可欠。
エンジニアとマーケッターの距離が物理的に近いことが理想だが、日本でビッグデータをうまく活用できている会社の共通点は、頻繁にコミュニケーションできていることである
と話した。
技術革新で広がる マーケティングの可能性
「データ活用のために、構造化データと非構造化データを結び付けたり、内と外のデータを結び付ける技術はどの程度進んでいるのか
」と質問する萩原氏に、龍野氏は、
処理しやすい構造化データと違って、非構造化データは、まず取得して整理し、意味のあるものにする必要がある。
先ほどのHadoopなどで収集した大量の非構造化データを、時間をかけずにデータベース化するツールを作成することはベンダーの役割であり、構造化データと非構造化データを連携させる技術やツールはすでにあります。
しかし、そのためには(ハードウェアやツールに対する)それなりの投資が必要
と答える。
また城田氏は、楽天のように大規模な事例を身近に感じるのは難しいが、「さまざまな技術はあるので、Webマーケッターにはその技術を活用するためのアイデアを出してほしい
」と話し、アメリカンエキスプレスカード(AMEX)の事例を示す。
ここでポイントとなるのは、プライバシーの問題からいかにユーザーの承諾を得て、リアル世界のカード番号とFacebookのIDをひもづけるかということ。AMEXの場合は、ユーザーが関心や興味のあるものを分析して特別な割引クーポンなどをカード自体に提供し、クーポンをプリントアウトして利用するのではなく、カードを使うだけで自動的に割り引かれるようにしている
と話している。城田氏によれば、カード会社ではこのような取り組みが盛んで、同様にVISAカードとGAPがコラボした事例をはじめ、いくつかの事例も示した。
龍野氏は
これらの事例は決して夢物語ではない。ビッグデータは、大量で加速度的ということは説明したが、重要なのはそのデータをリアルタイムに分析して活用すること。その技術はもう整っているということを知ってほしい
と補足する。
パネルディスカッションの最後として「ソーシャルリスニングでは、テキスト解析が重要だが、日本語のテキスト解析は今後もっと進化するのだろうか
」と話す萩原氏。
それに対して城田氏は
テキスト解析するときには、その言葉がどのような意味を持つのかがわからなければ、満足な結果を得られない。どの語句がどのような意味を指すのかを学習させるような技術は使われていて、機械が意味解析をできるようにしている
と話した。
一方、龍野氏は、
特徴のあるキーワードを抽出するというのは技術として実現可能。ログを解析してどのような傾向があるかは調べられるが、精度の問題はあると思う。
ソーシャルリスニングの分野でサービスを提供する会社は、国内外で出てきているし、途上な部分はあっても要素としてはそろってきている。しかし、ソーシャルマイニングを自社でやるなら、ソフトウェアですべて行えるわけではないので、マイニングする人材を育てる必要もある
と説明した。
講演終了に際し、萩原氏はパネリストの2人にまとめを求め、龍野氏はこれまでビッグデータをどのように活用するのか、長期に捉えるのか短期で結果を出すのかについて話をまとめた。また、城田氏は、O2O(Online to Online)の流れで発生するビッグデータの活用と、それをいかにビジネスに活かすべきかとまとめ、第一部を終了した。
オリジナル記事はこちら: 「Big Dataをプロに教わろう」 2012年2月29日開催 第25回Web広告研究会フォーラムレポート(1)

- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
Facebookはよそいき、ホンネのTwitter、コミュニティに欠かせないLINE、ユーザーインタビューで明かす利用実態
2014年3月4日 8:00
広告出稿量は売上に本当に影響しているのか? シャンプー&ペットボトル茶のデータ分析実践例
2014年5月7日 9:00
Twitterは情報収集、Facebookはコミュニケーション、メールよりLINE……達観するソーシャルメディアユーザー
2013年3月19日 8:00
Web担当者が知っておきたい景品表示法の基礎、「知らないと手遅れになる、広告表現(ステマなど)のルール」
2012年7月23日 8:00
スマホサイトとアプリのプロモーション施策を徹底解説、3つの攻略ポイントとは
2013年9月4日 9:00
O2O×ソーシャルメディアで全国1万店舗へ集客する、ローソン8つの活用事例
2013年4月5日 8:00




