生成AIが著作権侵害になるのはどんな事例? 法的リスクを弁護士に聞いた
AIで生成されたイラスト・文章・音楽などにも著作権はあるのでしょうか?これら生成AIの法律問題には知的財産や肖像権の侵害・帰属、個人情報の不適切利用、秘密情報の漏洩などがあり、現在の訴訟もこれらに関する内容が目立ちます。違反すると「差し止め」や「損害賠償」を請求される可能性があるので、事業者も利用者も理解したうえで使用することが必要です。
2023年12月19日 7:00
私たちの日常に浸透しつつある生成AI。たとえば、伊藤園では2023年9月発売の新商品「お~いお茶 カテキン緑茶」のテレビCMに生成AIが作成したタレントを起用、「日本初の事例」として話題を呼んだ。
生成AIで作成したキャラクターや文章に著作権はあるのか。そもそも生成AIの開発・学習に個人情報や著作物を使用できるのか。何をしたら違反で、違反するとどんな罰則があるのか。
これらの疑問を『生成AIの法的リスクと対策』(日経BPマーケティング)の著者である西村あさひ法律事務所・外国法共同事業の弁護士 福岡真之介氏に聞いた。


法的リスクが高いのは、「著作権」「個人情報」「秘密情報」の違反
生成AIの製品には、主に次の3種類がある:
- 文章生成AI
- 画像生成AI
- 音楽・音声AI
これらは大量のデータからその特徴を学習し、プロンプト(入力)に応じて適切な結果を出力する「機械学習」の手法を用いて開発されている。
企業が生成AIを利用する場合には、ChatGPTなどの大規模言語モデルに追加で小規模データを学習させ、特定の用途に向けた学習済みモデルを作成する「ファインチューニング」を採用するケースもある。自社で大規模言語モデルを一から開発するのは技術やコスト的に難しいためだ。
といっても既存の大規模言語モデルには、ファインチューニング可能なモデルと不可能なモデルがある。そのため、AIから望ましい結果を得るために、プロンプトに自社に特化した情報などを含めるなどして最適化する「プロンプトエンジニアリング」の手法も注目されている。
これらを踏まえ、生成AIには次の4つの「利用段階」がある:
- 大規模言語モデルを作成する段階
- ファインチューニングをする段階
- プロンプトを入力する段階
- アウトプットを利用する段階
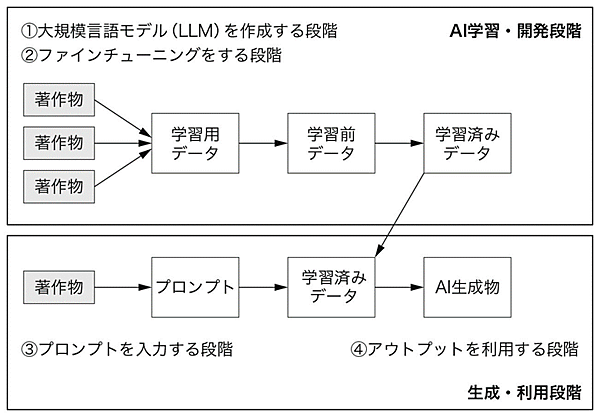
そのうえで生成AIの法的リスクを考えると、主に次の8種類があるという。
①知的財産の侵害・帰属
他人の著作権、その他の知的財産権を侵害する。生成AIの知的財産権が誰に帰属するのか不明確な場合がある。
②人格的権利・利益の侵害
肖像権やパブリシティ権・個人のプライバシー等を侵害する。
③個人情報の不適切利用
個人情報保護法に違反して個人情報を取り扱う。
④秘密情報の漏洩
自社や他社の秘密情報を漏洩する。
⑤誤情報の利用
生成AIが作成した間違った情報を利用して判断したり、その情報をAI利用者に提供したりする(主に生成・利用段階)。
⑥バイアスによる差別や不公平な取り扱い
生成AIが生成した差別的な情報を利用して判断したり、その情報をAI利用者に提供したりする(主に生成・利用段階)。
⑦フェイクニュースの流布やマルウェア作成等の不適切利用
生成AIによりフェイクニュースやマルウェアを作成し、それを流布する(主に生成・利用段階)。
⑧各種業法の違反
弁護士法・医師法・金商法等の業法に違反するサービスを提供する(主に生成・利用段階)。
福岡氏いわく、なかでも法的リスクが高いのは①知的財産の侵害・帰属、③個人情報の不適切利用、④秘密情報の漏洩の3つ。
現状、世界で起きている生成AI関連の訴訟も、この3つに関する内容が目立つ。たとえば、GitHubが提供する『GitHub Copilot』は、米国で著作権法やプライバシー法に違反しているとしてプログラマーから集団訴訟を提起されている。
これは、ユーザーであるプログラマーが書きたいプログラムコードを提案するAIサービスで、その学習用データは未公表だが、GitHubの公開リポジトリに登録されているオープンソースのコード(ユーザーが登録したコード)だろうと考えられている。
それらのコードは作者名と著作権帰属の表示が必要な可能性があるが、GitHub Copilotの出力には、これらが表示されていない。プログラマーたちは、これがライセンス違反にあたると主張している。
ちなみにマイクロソフトでは、大規模言語モデル (LLM) を組み込んだ自社の生産性向上ツール「Microsoft Copilot」に対して、法的リスクに対して責任を負う「Copilot Copyright Commitment」を2023年9月に発表している。Microsoft Copilotで生成した出力結果を使用して、著作権上の異議を申し立てられた場合、マイクロソフトが責任を負うわけだ。
生成AIの「開発・学習」段階におけるリスクのポイント
生成AIの法的リスクの大枠を整理したところで、利用段階に応じた法的リスクのポイントをまとめたい。生成AIの利用段階は4つに分類されると上述したが、①大規模言語モデルを作成する段階については解説を省く。大多数の企業や個人が一から大規模言語モデルを開発するのは、到底無理であるためだ。
ここでは、②ファインチューニングをする段階の解説に集約する。前提として、ベースとする生成AIは誰もが利用できるオープンソースではなく、独自のAIモデルを生成するプライベート仕様を活用することとする。ここで配慮すべきは、「学習に用いるデータ」である。個人情報や著作物の情報を利用する際は、注意が必要だ。
次に、いくつかの例とその回答を示す。
例社内向けに生成AIをファインチューニングする際、社員や顧客の個人情報を利用していい? →利用目的を公表し、その範囲で使用すればOK
基本的に「個人情報」は利用目的を公表して、その範囲内で使えば問題はないとのこと。他方で、個人情報をデータベース化した「個人データ」については、第三者提供が禁止されている。もし第三者に提供したい場合は、原則、本人の同意が求められる。ただし「業務委託」の場合は、同意が必要ない。たとえば、社員の個人情報のデータベースを人事コンサルタントに提供する場合、業務委託であれば同意がなくてもOKとなる。
例一般公開する生成AIサービスを開発する目的でファインチューニングする際、他人の著作物を著作権者の許諾なしに利用してもいい? →「享受目的」でなければOK
著作物とは、「思想や感情を創作的に表現したものであり、文学、学術、美術、または音楽の範囲に属するもの」とされている。具体的には、小説、論文、音楽、写真、絵画、彫刻、建築、映画などが含まれる。著作権法30条の4では、著作物を生成AIの開発・学習に利用するにあたり、「享受」を目的としないケースに関しては著作権者の許諾なしに利用できると規定されている。次の文化庁ホームページの説明も参考にしてほしい。
著作物は,技術の開発等のための試験の用に供する場合,情報解析の用に供する場合,人の知覚による認識を伴うことなく電子計算機による情報処理の過程における利用等に供する場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には,その必要と認められる限度において,利用することができることを規定しています。これにより,例えば人工知能(AI)の開発のための学習用データとして著作物をデータベースに記録する行為等,広く著作物に表現された思想又は感情の享受を目的としない行為等を権利者の許諾なく行えることとなるものと考えられます。
(文化庁のホームページより)
「享受」とは、視聴者等の知的・精神的欲求を満たすという効用を得ること(つまり、味わい楽しむこと)に向けられた行為であり、文章であれば読む、美術・音楽・映画であれば鑑賞する、プログラムであれば実行することが、これに当たる。著作物を機械学習の学習用データとして利用する行為は、享受にあたらないと考えられるそうだ。
とはいえ、もっとも安全なのは著作物を使わない、または許諾済みの著作物を活用することだ。たとえば、アドビが提供しているAdobe Fireflyは、オープンライセンスなど著作権の問題のない画像を学習段階で利用している。そのため生成AIの学習に使う画像データをAdobe Fireflyで用意するなどは安全な方法だ。
生成AIの「生成・利用」段階におけるリスクのポイント
続いて、開発した生成AIを生成・利用する場合の法的リスクのポイントを説明する。ここでの観点は、「生成AIで生成した生成物の著作権」および「秘密情報の取り扱い」の2点に絞りたい。
次に、いくつかの例とその回答を示す。
例生成AIでAIタレントを生成し、自社の広告物に活用する。AIタレントに著作権は認められるのか? →創作意図と創作寄与があれば、著作権が認められる可能性がある
「今まさに議論中のテーマであり、著作権が認められるケースもあるかもしれない」と福岡氏。判断基準は「創作意図」と「創作寄与」があるか。たとえば、伊藤園がCM用に生成したAIタレントに著作権があるのかは、その制作過程が外部からは見えないため定かではない。しかし、類似性の高いAIタレントを別企業が使用すれば、著作権侵害にあたるリスクがゼロではないということだ。
例生成AIで生成したキャラクターが、既存のキャラクターにやや似ている。これを商用利用した場合、著作権侵害に当たるのか? →類似性と依拠性の2つを満たしていれば、著作権侵害となる
類似性とは「後発の作品が既存の著作物と同一、または類似していること」、依拠性とは「既存の著作物に接して、それを自己の作品の中に用いること」を指す(文化庁著作権課「AIと著作権」より)。
つまり、先に制作されたキャラクターと特徴が似ていて、そのキャラクターを知っていたのであれば、著作権侵害とみなされる可能性が高い。もし、生成AIの生成段階でプロンプトにそのキャラクター名(「ドラえもん風のロボットのキャラクター」など)を入力していた場合は、著作権侵害となる可能性がより高まる。
例社内で利用している生成AIに秘密情報を入力するのは、秘密情報の漏洩にあたるのか? →利用している生成AIのモデルと秘密保持契約の内容次第
利用している生成AIがプライベート仕様である場合、プロンプトに入力した内容が第三者に漏れないことから、自社の秘密情報をプロンプトに入力してもいいケースもある。ただし、他部署に漏れてはいけない情報や一部の人しか知り得ない情報であれば、話は変わってくる。秘密情報部分を削除したり、匿名化したりする必要があるだろう。
他社の情報においては、秘密保持契約の内容を確認する必要がある。どの範囲まで共有し、どんな目的で利用できるのかを事前に確認しておこう。
違反すると「差し止め」や「損害賠償」を請求される
今回取り上げた著作権やプライバシーの侵害、秘密保持契約違反の場合は「差し止め請求」と「損害賠償請求」の2つが存在する。福岡氏いわく、悪質でない限り刑事罰が課される可能性は低いそうだ。
差し止め請求においては、違反とみなされると、いかなる場合でも差し止められる。たとえば、該当のキャラクターやイラストを使って製品を販売していた場合は、すべて破棄させられる、秘密情報や個人情報の利用をやめさせられる、といった具合だ。ちなみに、故意・過失がなくても、違反とみなされ差し止め請求をされる場合もある。
損害賠償請求においては、著作権侵害の場合は損害額が低いという。たとえば、新聞の切り抜き記事を会社のデータベースに入れて、社内で読めるようにした企業が、新聞社2社に損害賠償請求をされた事例があったが、損害額は700万円と130万円ほどだった。日本では懲罰的賠償などが認められていないため、少額となる傾向があるという。
一方、秘密保持契約違反の場合は内容次第といえる。契約上で損害賠償額の上限や違約金があらかじめ定められている場合は、それに従うこととなる。プライバシーの侵害もケースバイケースだが、被害者が個人の場合は一人当たり数千円になることが多いようだ。

福岡氏は、著書『生成AIの法的リスクと対策』のなかで、「まだ議論が十分でない論点が多く、法令やガイドラインも変わり得るため、具体的な事実関係と適用ルールに応じた検討が重要だ」と述べている。ひとまず生成AIの法的リスクのポイントを押さえつつ、都度、最新の法令やガイドラインの確認が求められる。
バックナンバー
この記事の筆者


筆者の人気記事
「ステマ規制」何をしたら違反? PR表記のルールや禁止のポイント
2023年7月11日 7:00
Figmaで作ったデザインをWebサイトに即反映「STUDIO」
2023年10月3日 7:00
なぜ「コナズ珈琲」は人気? 好調のカギは“あえて”回転率を求めない居心地の良さ
2024年6月7日 7:00
なぜ「チョコザップ」は人気? 成功の裏に“規格外のマーケティング戦略”あり
2024年2月28日 7:00
「Tポイント」と「Vポイント」が統合し、日本最大級のポイント経済圏へ! サービスの主な変更点4つ
2024年4月26日 7:00
「あ、高速道路のSAで見たことある!」コーヒールンバが流れる自販機「アドマイヤ」は注文後に豆を挽く本格派だった
2023年7月13日 7:00




