DMP構築前にマーケターが知っておきたい、データ設計の注意点
データをきちんと用意するバックエンドの仕組みが整っていなければ、ポテンシャルを十分に活かしきれない
2019年7月30日 7:00
データ分析する前に、データの関連性を考えて必要なデータと項目を決め、データの更新頻度や集計テーブルの有無を考えておく必要がある。また、データ収集方法やデータ収取時にも注意すべき点が多々ある
この言葉通りに、データからビジネス価値を見出すには、分析の前の「下準備」をきちんと進めておくことがカギを握る。実際には、どんな難しさがあり、それをどう乗り越えて行けばよいのか。
アナリティクス アソシエーション(a2i)主催で4月9日に開催された「アナリティクス サミット 2019」において、「Quick DMP」を提供するアユダンテの井上達也氏が登壇し、「データ分析、その前に ~DMP構築で見えた、壁とぶち破り方~」と題して講演した。同社がQuick DMPを構築した経緯を交えた内容はとても興味深いものだった。

データ分析が無駄にならないためには
井上氏は、データ分析活動を支える環境はどうあるべきかから口火を切った。広告データ、行動データ、オフラインデータなどが一元的に管理され、分析結果をシェアして施策を練り、実際にやってみたことの成果もまたデータとして蓄積されていく。この一連の流れを作ることが理想とはいえ、なかなか簡単にいかないのもまた事実だ。
現実に目を向けると、データは分散していて分析に苦労し、分析結果を共有しようにも一筋縄にはいかず、よく分からないままに次の施策が決められて現場に指示が飛ぶといったことが起きている。最適化されぬまま、各フェーズでコストが発生していることになる。
こうした問題の根本的解決に活かせるのがアユダンテが提供するQuick DMPだ。CRMシステムなどサードパーティ製ツールで扱っているデータを集約して専用のデータベースで一元管理。Tableauなどを利用して分析や可視化を行い、さらにその結果を様々な形でデリバリできるサービスだ。井上氏は、Quick DMPがなぜ生まれたかの背景を含め、DMPのメリットや活用する上で注意すべきポイントなどをあらためて整理した。
データを自動的に整理することが重要
Quick DMPが作られる前、アユダンテは自社や顧客向けのレポート作成を、スクラッチで開発したExcelレポート生成ツールで対処していた。しかし、Excelのバージョンアップがある度に、うまく機能しなくなったり、一部データを手動で貼り付ける必要が生じたりと問題に直面していた。
レポートに表示する内容にちょっとした変更を加えるにもプログラム自体の手直しが必要でもどかしい思いをしていた。その後、Googleスプレッドシートのアドオンなどを使って、データ収集を容易にする仕組みを作ってみたが、細かな要件に対応しきれず、かといって自分達で手を入れられることにも限界があって厚い壁を感じていたという。
そうした状況下、アユダンテがQuick DMPを作ろうとしたきっかけはTableauとの出会いだった。セルフサービス型のBI(Business Intlligence)ツールとも言われるTableauは、各種の分析処理を直感的な操作体系の中で実践でき、しかもビジュアライズにも定評がある。
もっとも、フロントエンドにいくら優れた分析ツールを持ってこようとも、対象とするデータをきちんと用意するバックエンドの仕組みが整っていなければ、ポテンシャルを十分に活かしきれない。そこで同社は、複数のシステムからデータを集約・統合し、さらにはクリーニングする仕組みを開発することを決断。それが今日のQuick DMPへと結実している。データの“下ごしらえ”は機械に任せて自動化し、人は分析に集中できるようにしようとの想いがある。
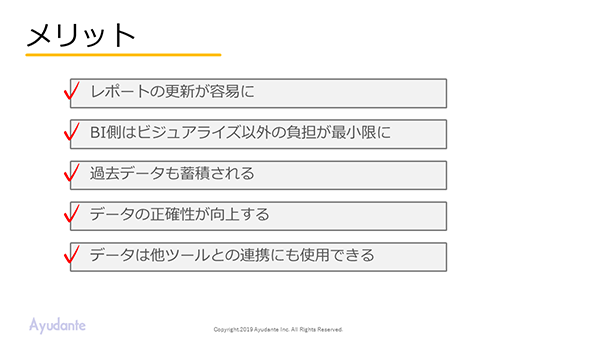
実際に得られたメリットとして、井上氏は以下の5点を挙げる。
- レポートの更新が容易に
- BI側はビジュアライズ以外の負担が最小限に
- 過去データも蓄積される
- データの正確性が向上する
- データは他ツールとの連携にも使用できる
データ設計の注意点
Quick DMPに限らず、DMPを構築する際には、データの設計が必要となる。具体的ステップとしては、以下を整理しなければならない。
- 必要なデータ
- データの関連性
- データの更新頻度
- 集計テーブルの有無
必要なデータはアウトプットイメージから想定し、そのデータのどのような項目が必要かを洗い出していく。必要なデータが決まったら、それぞれの関連性を考える。関連付けるための共通項目がない場合には、別のデータを取得して紐付けることも行わなければならない。
取得するデータと項目が決まったら更新頻度を検討する。リソースが十分であれば頻繁に更新できるが現実には制約があることも少なくない。その場合は、データの重要性とリソース負荷とのバランスから更新頻度の落とし所を決めていく。
集計テーブルは、データベースの中で、ある条件に沿って予め集計をしておくためのものだ。例えば日々の売上明細データを基に1週間分の売上データを集計しておくといったことができる。
データをローカル環境にロードする際のレスポンスが悪い場合や、データベースへのクエリー回数に応じて課金されるサービスを利用していてコストを抑えたい場合などで使われる。ただし、集計の「粒度」によっては柔軟性に欠ける面もあるので注意が必要だ。週単位の売上実績を見ていて気になることが生じ、結局は日ごとのデータを参照する(大元のデータベースを見に行く)ことが頻発すると、さしたる効果がなくなってしまう。
データ収集の注意点
データの設計を終えたなら、実際にデータを収集する方法を考えていく。最近では、他のシステムのデータを取り込むのに所定のAPIを経由するものがほとんどだが、この場合はコール頻度や回数に制限があったり、バージョンアップによってAPIの仕様が変わったりすることなどに注意が必要だ。APIを利用できない場合は、WebスクレイピングやFTPなどの方法を検討する。
データ収集時に特に気をつけておくべきこととして「表記の揺れ」がある。日付や金額、男女などのデータは表記や形式がシステムごとに微妙に異なることがある。いずれ、まとめて扱うのであれば、早い段階で揃えておくことが肝要だ。
また、カンマ区切りのCSVフォーマットを取得する際には、例えばアンケートの自由回答欄にカンマが紛れていることが影響して1行あたりの項目数が合わなくなり混乱するといったことが起きがちだ。分析作業に集中したいアナリストに余計な手間をかけないためにも、データ準備の過程で起こりがちな問題をマーケターが理解しておいて、必要に応じて適切な対応をしておく。そのことが分析現場のストレスを軽減することにつながるのだ。

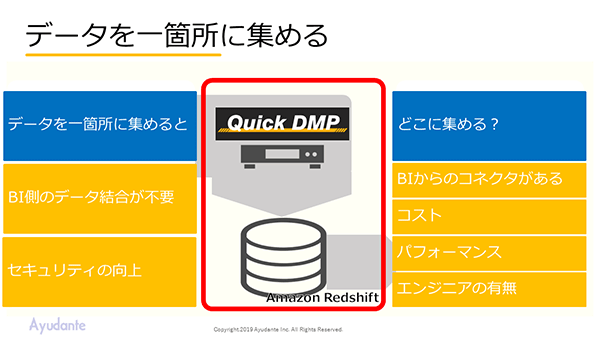
収集したデータを1カ所に集約し一元管理するようにすれば、BI側であらためてデータの結合をすることなく関心事に沿って分析やビジュアライズにあたることできる。データを集める場所としてQuick DMPがAmazon Redshiftを使っているように、基本的にはBIがコネクタを備えている環境を前提として、用途やコストパフォーマンス、エンジニアにとっての使いやすさなどを評価材料にい選定することとなる。
DMPを社内に浸透させるには
最後に井上氏は、Quick DMPを導入した企業の声として、なかなか社内に浸透できないという悩みを聞くことがあると明かす。これらの企業の共通点として「発案者の差」と「認識のハードル」の2つがあると井上氏は説明する。

発案者の差というのは、DMPに関心を寄せるのは一般的にマーケ部門かIT部門だが、双方の思惑や技術的バックグラウンドの違いで歯車が噛み合わなくなることが往々にしてあるという。マーケ部門はデータを使って次の一手を最適化していこうとうモチベーションが高いものの、データ構造などに疎い場合がある。一方で、IT部門はデータをハンドリングする上での問題や解決策には明るいが、分析現場のビジネス上の狙いやデータに求める意味までを理解していないことがある。DMP導入を成功に導くためには、両者が同じ方向を見据えること、つまりは日頃からのコミュニケーションで問題意識を揃え、互いの知見を持ち寄って解決する体制を育むことが欠かせない。
認識のハードルは、データドリブン型の行動に対する部署や個々人の温度差とも換言できるだろう。井上氏は、「とにかく手厚くレポートを配信し、データを気に留める機会を増やすこと。レポートを元にみんなで議論する雰囲気を作ることが大切だ」と話す。メールにレポートを添付して形式的に同報するだけでなく、報告・連絡・相談などの手段として現場に根付き始めたチャットツールにレポートのスクリーンショットを貼り付けて送るなど、関係者の目に触れるような努力を積み重ねることが重要だと改めて強調した。
「ちょっとした知恵や工夫でDMPの導入や運用の煩わしさから開放されるもの。当セッションで話したことが、少しでも皆さんのヒントになれば幸いだ」と井上氏は講演を締めくくった。
バックナンバー
この記事の筆者
筆者の人気記事
5年後の世界を想像できるか? マーケターが押さえておくべき5つのトレンド
2019年1月11日 7:00
最新グーグルSEO要因と順位の関係7つのポイント、サイバーエージェントと京都大学が共同研究
2014年1月17日 8:00
ウェブライダー松尾氏が語る「検索結果1位を目指すなら、徹底的にユーザー思考を追求する」
2018年9月13日 7:00
さらに理解を深めるために今さら聞けないアクセス解析用語集
2007年12月20日 9:00
ビッグデータ活用が進まない3つの理由、データを成果につなげるデータサイエンティストの役割とは/ソフトバンク・テクノロジー
2014年1月29日 10:00
“UX王子”が語る、KPIではなく人間中心設計(HCD)の観点から見るUXデザイン
2014年12月18日 6:00





