楽天が日本語に最適化した高性能なLLMを公開、オープンモデルで提供してAI発展に貢献
「基盤モデル」「インストラクションチューニング済モデル」「チャットモデル」の3つ
2024年3月22日 7:02
楽天グループは、日本語に最適化した高性能の大規模言語モデル(LLM)を公開した、と3月21日に発表した。基盤モデル「Rakuten AI 7B」と、同モデルを基にしたインストラクションチューニング済モデル「Rakuten AI 7B Instruct」、さらにファインチューニングを行ったチャットモデル「Rakuten AI 7B Chat」の3モデルを「Apache 2.0ライセンス」で提供する。楽天の公式「Hugging Face」リポジトリからダウンロードできる。
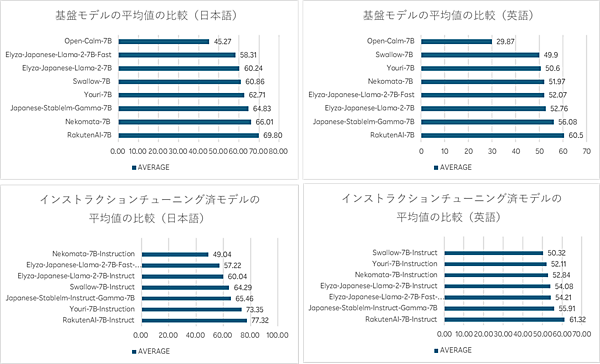
「Rakuten AI 7B」はフランスのAI(人工知能)スタートアップのMistral AIのオープンモデル「Mistral-7B-v0.1」を基に大規模なデータを学習させた70億パラメータの日本語基盤モデル。「Rakuten AI 7B Instruct」は指示形式のデータで基盤モデルをファインチューニングし、入力した指示に対して返答を生成する。「Rakuten AI 7B Chat」は会話形式の文章生成のためのチャットデータを用いてファインチューニングした。
基盤モデルとインストラクションチューニング済モデルは、評価ツール「LM Evaluation Harness」で高いパフォーマンスが評価され高性能と実証された。全3モデルは文章の要約や質問応答、一般的な文章の理解、対話システムの構築など、さまざまなテキスト生成タスクにおいて商用目的で使用できる。基盤モデルは他のモデルの基盤としても利用が可能。オープンなモデルとして提供することで、国内外のAIの発展を後押しする。
- この記事のキーワード
この記事の筆者

筆者の人気記事
国民生活センターが道交法の基準上限を上回る「電動アシスト自転車」を新たに公表
2023年9月11日 7:02
イオンが「電子マネーWAONポイント」を「WAON POINT」に統合、分かりにくさ解消
2025年11月12日 7:03
アマゾンジャパンが「インボイス制度」に対応、販売事業者に代わって適格請求書を発行
2022年10月28日 7:03
総務省が「Pinterest」「Amebaブログ」「爆サイ.com」「ニコニコ」を情プラ法で指定
2025年6月3日 7:03
「後払い決済サービス」のトラブルが3年間で3倍に急増、国民生活センターが注意喚起
2025年7月3日 7:02
「Yahoo!メール」が3月から新ドメイン「@ymail.ne.jp」のメールアドレス提供開始
2022年2月28日 7:01




