
AWS(アマゾン ウェブ サービス)による音声データをテキスト化するサービス「Amazon Transcribe」の日本語対応が始まっています。音声ファイルをアップロードするだけで、AIが分析してテキストデータに変換するサービスです。
画期的なのが料金と時間です。60分間の音声データならわずか10~20分ほどで作業を完了。かかる料金も1.44ドル、日本円にしておよそ150~160円と非常に安価となっています。
読者の方の中には会議の議事録を作成したり、マーケター向けのイベントを録音して後でまとめたりしている人もいらっしゃると思います。果たして、実際に文字起こしとしてどこまで使えるのか。現時点での実力を検証してみました。
(文:Marketing Native編集部・岩崎 多)
【結論:会議や会話には不向きだが、1人語りには強い】
会議やインタビュー、イベントを録音した音源など、複数人が会話するシチュエーションを書き起こす用途としては、実用性はまだ高くないという結果になりました。
人力で文字起こししたテキストとAmazon Transcribeにより出力されたテキストの類似度を「文章類似度算出(速攻ハック版)」で調べたところ、結果は39~58%の範囲に収まりました。しかし、単語の聞き取り間違いが多いため、出力されたテキストから内容を読み解くことは困難で、多くの場合、音声ファイルを改めて聞いて確認する必要があります。
一方、1人で文章を音読した録音データで調べてみると、句読点など多少の修正は必要ですが、ほぼ正確に書き起こすことができます。類似度は80%を超えることもあり、内容も音声ファイルを改めて聞く必要はほぼありませんでした。
【検証方法】

・インタビュー取材時の音声ファイル
・会議やイベントの録音
・一人で読み上げたり話したりする音声
以上の複数の音源を検証用に使用しました。そして、人力で実際に一言一句文字起こしを行ったものと、Amazon Transcribeにより生成されたテキストデータの2つを比較することにしました。
比較する際には2つの文章の類似度を簡易的に測定するサイト「文章類似度算出(速攻ハック版)」を利用し、類似度を算出しました。類似度とはコピペやパクリを検出するために、どのくらい文章が似ているのかを数値で表したものです。音源として使用した音声ファイルは一般的な市販のICレコーダーで録音したもので、MP3ファイル形式のものと、スマートフォンのアプリで録音したWAVファイル形式のものを使用しました。
【検証結果の詳細】
以上の条件で、複数の音声データを用いて検証したところ、Amazon Transcribeを利用した際の類似度の傾向は2つに分かれました。

①複数人の音声を録音した音声ファイルの場合
冒頭の結論でも触れたように、複数人の音声を録音したファイルの類似度は39~58%の範囲内に収まり、数字だけ見ると、内容の半分はうまく書き起こされたかのような印象を与えますが、実際の文字起こしは以下のような感じになります。

意味不明な言葉の羅列のように見えますが、実際の発言内容は以下のとおりです。

以下の赤で塗りつぶした部分が単語を聞き間違えている部分です。

こうして見ると、実際に間違えている箇所が半分以上、50~60%あるだけでも判読が難しく、もはや元の文章は想像できないため、音声ファイルを聞き直すことになりそうです。また、この音声は少しだけ早口だったのですが、文字起こしされたテキスト全体の量が実際よりもやや少ないものとなっていました。音声のスピードも文字起こしに影響を与えるようです。
ただし、ファイルによっては聞き取りやすいものがあるようで、認識の精度は録音状況によって変わりました。発言する人の声の明瞭さや録音状況の良好さなどにより、ほぼ正確に文字起こしできている箇所もあり、その場合は部分的に65%以上の類似度となることもありました(ただし、文章全体で類似度を測定すると30~50%台になりました)。比較的精度の良かったものが、次の文字起こしデータです。

実際に話した内容は以下のとおりです。

そして、以下も同じく赤色で塗りつぶした部分が単語を間違えている部分です。間違いの割合も減り、先ほどの例よりも文意が読み取りやすくなっています。

精度に差が出る理由は録音状況にあると思われますが、大まかな傾向として以下のことが挙げられます。
・早口の場合、聞き取る精度が悪くなり、話しているのに文字起こしされない言葉も出てきて、全体的に文字起こしされる文字数が減る傾向にある。
・音量が大きく、クッキリと声が聞き取れるもののほうが、音量が小さかったり、やや口ごもって聞こえたりするものよりも類似度が高い。
・2人が対面で話しているもののほうが、4~5人で話しているものよりも類似度が高い。
なお、男女の声の違いで精度が変わるような傾向は見られませんでした。それよりも、ここで挙げたように、話すスピードと言葉の明瞭さの2点が精度に大きく影響を与えたものと思われます。
同時に録音したボイスレコーダーのMP3ファイルと、スマートフォンのアプリを利用して録音したWAVファイルも比べてみましたが、書き起こされた単語に微妙な違いは見られたものの、文章の類似度に大きな違いは見られませんでした。また、Amazon Transcribeは動画ファイル(MP4など)での文字書き起こしにも対応しているため、イベントなど複数の人間が話している状況の動画で試してみましたが、類似度に大きな変化はありませんでした。
また、実際に使った印象としては、以下のケースの音声認識もうまくいかなかった傾向にあります。
・同時に人が発声してしまっている場合
同時に笑い声が起きている場合や、言葉が被ってしまった場合、うまく言葉が聞き取れていないケースも見られました。また、インタビュアーの合いの手にも傾向があり、「はい!」という声の場合は多く認識されていましたが、口をあまり動かさずに小さく発する「えぇ」などはあまり文字起こしには反映されませんでした。
・他者と比べて離れた位置からなされた発言
複数人が話している場合に、やや離れた位置から発せられた音声は、その多くが聞き取られておらず、「そうそうそうそう」「そうですねそうですね」などの表記になってしまうケースが多く見られました。人間の耳では何を言っているかは、何とか聞き分けられる範囲のものでしたが、音声の録音状況によってはAmazon Transcribeでは認識が難しいことがわかります。会議での発音はマイクなどを使って、ハッキリと話すようにすると議事録が取りやすくなると言えます。

② 1人で話している音声ファイルの場合
次に、あらかじめ用意された文章(書き言葉)を1人で読む状況も録音したところ、複数人が話すシチュエーションとは打って変わって80%以上の類似度を示しました。類似度が80%を超えていると、実際の文章とおおむね一致しており、内容確認のため再度音声ファイルを聞く必要もありませんでした。
ただし、音声を早口にしたり、話し言葉の口調に変えたりすると言葉の変換ミスが目立つようになり、類似度は約10%減って70%台になりました。
実際に書き言葉を1人で読んだときの文字起こし例を以下に挙げます。傾向としては、これまであまり入らなかった句読点が多く入るようになりました。なお、書き言葉を読む距離についてもスマホを持ったり、机の上に置いてみたりなどいくつか試しましたが、声をハッキリ出していれば精度にあまり影響はありませんでした。

実際に話している音声の内容は以下のとおりです。

【出典】
インフルエンサーマーケティングの事例と実施する際のポイント Marketing Native
これまでと同様に、単語を間違えた部分は赤色に塗っています。黄色は句読点を間違えている部分です。ここまで精度が高ければ、文字起こしとして十分使用可能です。ちなみに、最後の「やっぱり」は紙をめくった音を日本語として聞き取った結果のようです。

【レビュー:実際に使ってみて感じたメリット・デメリット】
Amazon Transcribeの検証をするため、20ほどの音声ファイルを検証してみました。使い続ける中で感じた驚きのポイントをまとめます。
●メリット
・文字起こしのコストが大幅に削減できる
Amazon Transcribeは60分の音声データを1.44ドル(150~160円)でテキスト化してくれます。人に作業を頼んだ場合、1000円台~1万円以上かかることもあるため、1/10~1/100ほどの費用で済みます。
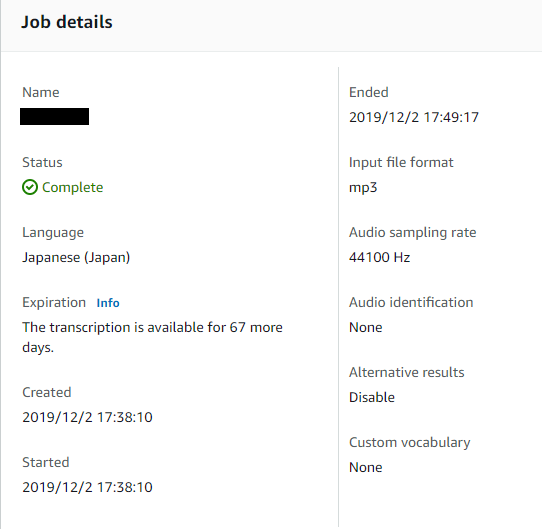
作業時間も60分のデータで10~20分と、人間には不可能なレベルの短時間で仕上げてくれます。上記は45分の音声データを変換した際の記録ですが、約11分で作業が終了しています。
1人語りは状況によって、ほぼ正確に文字起こししてくれるため、メモの口述筆記や、YouTuberのテロップ作成などに使えて応用範囲が広がりそうです。
・データが細かい

各単語に「Confidence:97.90%」というふうに、文字起こしの正確さに対する「信頼度」を示す数値が単語ごとに算出されています。つまり、Amazon Transcribeはこの単語に何%の確信を持って文字起こしをしているかという数字です。これが時間情報とともに、単語ごとに細かく設定されているところは驚きでした。
●デメリット
・データの扱い方が難しい
文字起こしのデータは、一般にはなじみの薄いJSON形式のファイルでダウンロードすることになります。プログラマーの方には扱いやすいファイルかもしれませんが、一般的な使い方としては、そこからテキストを抜き出す手順が必要になってしまいます。また、Amazon Transcribeで文字起こしする音声データはAWSの「Amazon S3」というストレージサービスを利用しなければいけないことも、初めて使う人にはややわかりにくくなっています。
・余分な半角スペースが大量に入ってしまう
Amazon Transcribeは文字起こしの際、単語ごとに認識しているため、データには大量の半角スペースが入っています。テキストとして使用するときには使いにくいので、Wordの置き換え機能などを使って、半角スペースを一括削除しなければなりません。また、テキストデータの中に時折、「 LENCE] 」という文字列が表示されることがあります。こちらもそのままでは使いにくいのであわせて削除することになります。
・発言者の聞き分けができず、区切りがわかりにくい
Amazon Transcribeの文字起こしでは、人物の声を分けて出力しません。そのため、複数の人が思い思いに話していると、文字起こしのどこからどこまでの範囲が、誰の発言内容かということがわかりにくくなっています。また、文字起こしのデータには句読点が入らないことも多いため、文章の切れ目を見つけることも難しい状況です。そのため、複数の発言者が登場する会話や会議の文字起こしにはやや不向きと言えます。なお、話者識別機能は搭載しているそうですが、プログラミングの知識が別途必要になる作業のため、今回は試せていません。
(例)
複数人が会話した際のAmazon Transcribeの出力例(上)と、対応する実際の発言内容(下)。複数人の発言内容がひとかたまりになっています。


・人力で行った文字起こしよりも聞き間違いが多い
出力されたテキストデータは日本語が並ぶため、一見問題がないように見えますが、文脈を無視した全く無関係な単語が並ぶことも少なくありません。その場合、結局、何を言っているのか聞き間違いの正解を予想できず、音声データを聞き直して修正する必要が出てきます。人力による文字起こしの場合は、文脈からある程度推測できるため、録音を聞き直してまで対応する回数もそれほど多くはなりません。なお、こうした誤変換をなるべく防ぐため、Amazon Transcribeにはよく使う言葉や専門用語を辞書登録できる「Custom Vocabulary」という機能がありますが、検証時にはまだ日本語には対応していませんでした。
間違いが起きる傾向のひとつとして、次に挙げる例のように、想像もできないような漢字の読み方をしているものがいくつか見られました。人間の文字起こしでは起きにくい、AIならではのミスと言えますが、これから日本語への対応が進むことで改善されるものと思います。
(例)
「紙独特」→「神戸とか」
これは「神戸」を「こうべ」ではなく「かみ」+「ど」と読んでしまったミスです。
「あとの話にもつながる」→「熱もあの人とつながる」
「熱」が「ねつ」ではなく「あつ(い)」の読み方が採用されてしまっています。
「茅野市」→「うちの子」
「子」が「こ」でなく「し」と読みかえられてしまったため、「茅野市(ちのし)」が「ちの子」となり、不自然なため「うちの子」となってしまったものと思います。
【珍プレー:Amazon Transcribeのオモシロ聞き間違い集】
「ブランディング」を「プランニング」、「施策」を「失策」、「事業」を「授業」というふうに聞き間違えることは人間でも起こりがちです。Amazon TranscribeはAIによる文字起こしだからこそ、人力ではありえない聞き間違いも多々生まれています。ここでは思わず和んでしまった誤答例を紹介します。
「クリエイティブのUI」
↓
「クリームチーズの具合」

「ブラッシュアップしたポイント」
↓
「漏らしちゃった子もいた」

「マーケターをターゲット」
↓
「負けたも大変だと」

「CMOになりたい」
↓
「貧乏になりたい」

「データは過去のもの」
↓
「伝統か子供」

「ハイパフォーミングなチームづくり」
↓
「はいポンピングチームづくり」
![]()
【まとめ:Amazon Transcribeに期待するポイント】
現状のAmazon Transcribeは、1人が静かな状況で文章を読む音声に関してはほぼ正確に文字起こしできます。ただし、会議やイベントなど複数の人が話すシチュエーションにはやや不向きで、録音状況により精度の差も激しくなっています。
もちろんこれから音声認識の精度は上がっていくと思われますが、Amazon Transcribeに対して期待したいポイントをまとめます。
・発言した人間を聞き分けられるようになってほしい
文字起こしをしたい状況の多くは、会議や取材、イベントが多いと思われます。複数の人間が話し合う場合、人間の声の違いを読み取って、違う人間が話したと感知したら適宜句読点が入ったり、改行したりなどしてもらえると、文字起こしがより読み取りやすくなります。話者識別機能は搭載しているそうですが、別途プログラミング知識が必要になります。特殊な作業を行わなくても、一般人でも手軽に使えるようになればと思います。
・AIの進歩で文脈を把握できるようになってほしい
人力の文字起こしの場合、前後の文脈から判断するため大きな聞き間違いは起きにくいという傾向にあります。Amazon Transcribeの間違いの中には、普段使わないような漢字の読み間違いによるものも多く見受けられました。機械学習によって大量に文章などのデータを読み込ませることでミスが改善されたら、音声ファイルを聞き直す手間が省けて、使いやすくなると思います。
・音声ファイルをAIが判断しやすいように加工する機能が欲しい
録音状況が文字起こしの精度に影響を与えていることはわかったので、ファイルをアップロードする際に、よりAIが判断しやすい音声となるよう自動的に音量を上げたり、音質を加工したりする機能があれば便利ではないかと感じました。
Amazon Transcribeには画面左下に「フィードバック」を送る機能があります。現在のフィードバックには誤変換に関する項目は設けられていませんが、ここで具体的に指摘できるようになったら、間違い回数を減らすことができると思います。
上手に使えば、作業時間や費用面などのコストを大幅に減らしてくれるAmazon Transcribe。現時点では、人力による文字起こしに負けている部分は多々ありますが、今後も順調に進歩して、文字起こしという重労働から人間を解放してくれることを切望します!





