生成AIは「鉄腕アトム」になれるのか? 東大・東工大教授が語るAI研究の最先端
アカデミアの専門家が語る、次世代のAI技術とは? 東京工業大学情報理工学院の岡崎直観氏、東京大学AIセンターの松原仁氏、中央大学理工学部教授の樋口知之氏が登壇した基調講演の様子をお届けする。
2024年1月11日 7:00
急速に進化を続ける生成AI。データサイエンティストやその周辺領域には、どのような変化が起きようとしているのだろうか。
データサイエンティスト協会は、「10thシンポジウム〜データサイエンスの最前線〜」を開催。基調講演では、東京工業大学情報理工学院の岡崎直観氏、東京大学AIセンターの松原仁氏、中央大学理工学部教授の樋口知之氏(モデレーター)の3名が登壇し、生成AIの仕組みや将来展望について語った。

ロゴデザインにJSON作成……生成AIはここまで進化した

生成AIと聞いてまず思い浮かぶのは、流行りの画像生成AIかもしれない。
上図は、東京医科歯科大学と東京工業大学が統合にあたって、新大学のロゴをChatGPTに考えてもらった例だ。「医学と工学の両方の要素を取り入れることで、2つの大学の合併を表現しました」とある通り、医療・ゲノム・歯車などのモチーフがちりばめられている。

「もう少しシンプルなデザインのロゴも作成してください」と頼むと、このように両方の要素を加えつつ、洗練されたデザインを提案してくれる。

また、言語モデルの発展も目覚ましい。上図は「日本語の文を英語に翻訳し、対訳コーパス(多言語間の文が対訳の形でまとめられた言語資料)をJSON形式で作成してください」と指示したものだ。
JSON形式(JavaScriptのデータの記述方式)は本来Excelのワークシートなどで作られることが多いが、エンジニアに依頼せずとも、形式を指定することでAIに出力させることが可能になっている。
LLM(大規模言語モデル)の基本的な仕組みは「次単語予測」
今回岡崎氏が講演のテーマとしたのは、「言語モデルが質問に答える仕組み」だ。

簡単に言うと、言語モデルとは 「Lemonがヒットした日本人アーティストは『○○』」のように、文章の次にくる単語を予測するという仕組みだという。
まず、文章を「lemon/が/ヒット/した/日本人/アーティスト/は」と単語列に区切り、条件付き確率のモデルに当てはめる。予測したい単語をyとし、日本語の全ての単語をyに入れていって、その確率が一番高いものを回答とする。この場合は「米津玄師」の確率が最も高いということだ。
ここには、確率や統計上の問題だけでなく、言語を扱うことの難しさがあると岡崎氏は語る。「記号と意味をどう対応づけるか」は、昔から注目されていた問題だという。
曖昧性問題
まず、曖昧性の問題。「記号(単語)」が表現しうる「実体や概念」が複数あるということだ。この場合、「lemon」とは曲を指すのか? 食べ物を指すのか? 「アーティスト」とは画家なのか? 歌手なのか? ということを、文脈から区別する必要がある。
類義語(多様性)問題
次に、似た意味が別々の単語で表されるという類義語の問題だ。たとえば、lemonが「ヒットした」「ブレイクした」「流行した」はほぼ同じ意味だが、それぞれ別の単語である。この意味のつながりを理解できないと、別の確率として計算されてしまう。

こうした類義語問題への対処として、2013年頃から「単語埋め込み」や深層学習の研究が盛んになると、こうした類義語問題に取り組みやすくなった。これは、固定次元のベクトルを使うことによって、コンピューターが単語の意味を内部的に表現する仕組みのことである。
たとえば、「アメリカ」と類似している単語ベクトルを検索すると、「米国」「アメリカ合衆国」のベクトルがヒットする。人間にはわからない数字の羅列だが、コンピューターなりに類義語を理解していることになる。

このような「単語埋め込み」を利用したのが、「それぞれの単語を単語ベクトルで表現して、ベクトルを合成していく」というアーキテクチャだ。矢印の向きに単語の情報を伝播させていくことで、「アーティスト」は音楽、「lemon」は曲だと認識できるという。
『文脈依存型の単語埋め込み』というのが、2017年頃に明確に打ち出されたアイデアです。『アーティスト』のベクトルに対し、『ヒット』 『日本人』 『lemon』の情報を統合したベクトルを作ることで、より意味が明確になった埋め込み表現を合成できる。周辺の文脈を考慮した表現が得られることで、曖昧性問題に内部的に対処できていると我々は考えています(岡崎氏)
ChatGPTの台頭と「プロンプト」による学習
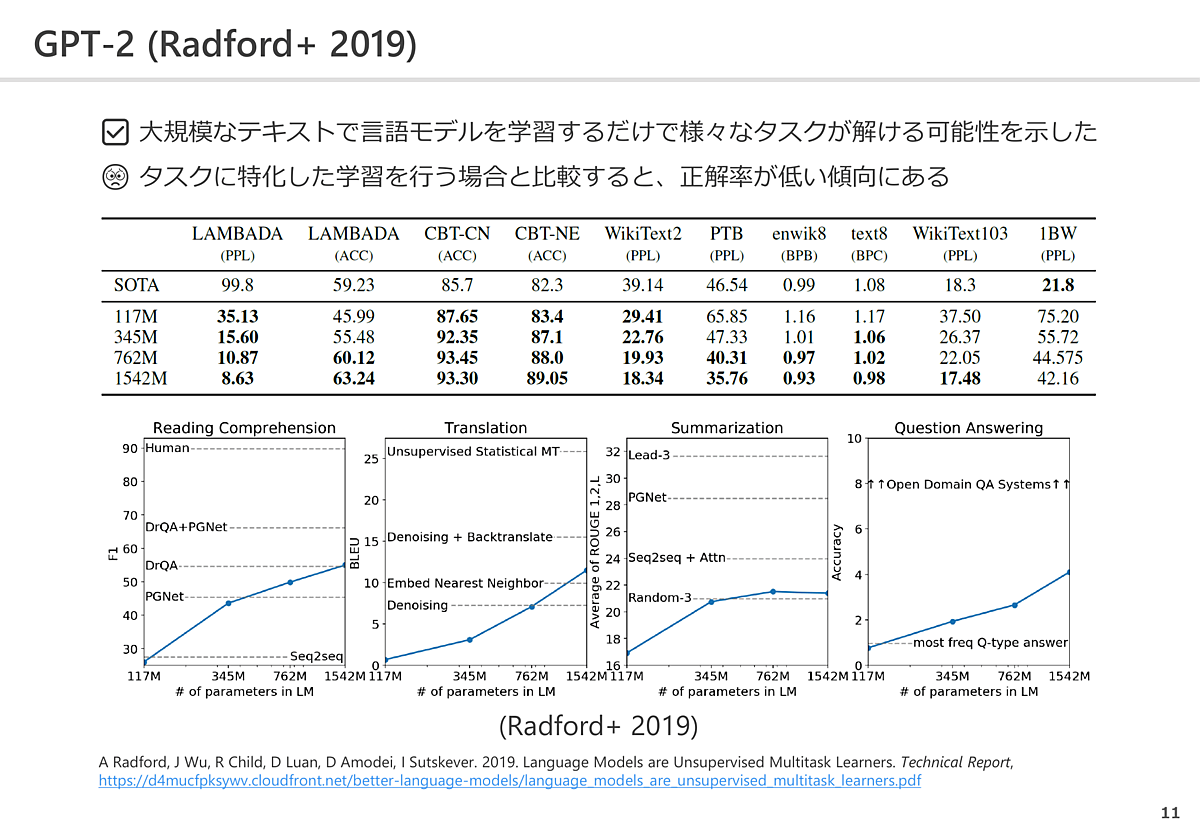
そうした議論の後に台頭したのが「GPT-2」だ。大規模なテキストで言語モデルを学習するだけでさまざまなタスクが解けるという可能性を示したが、「機械翻訳」など特定のタスクに特化したAIと比較すると性能面で劣っているという点が問題とされていた。

またその頃、「言語モデルの性能は規模(パラメータ数、訓練データ量、計算能力)に強く依存しており、モデルが採用するアーキテクチャ(パラメータ数は層数に対し比例して増加)は関係ない」というスケーリング則が発見された。これを動機として、言語モデルのサイズを2桁大きくしたのが「GPT-3」だった。
同時に言われ始めたのが、「プロンプトの最適化」だ。大規模言語モデルに与える「テキスト(=プロンプト)」さえ工夫すれば、言語モデルのアーキテクチャを変更せずにタスクを解けるのではないか、と2020年の論文で指摘された。

興味深い研究として、「指示チューニング」がある。これは、「指示」として説明されているタスクのデータを大量に学習させ、言語モデルをファインチューニングすることを指す。
質疑応答型の簡単な問題を与え続けた結果、急に要約の問題が解けたり、翻訳の問題が解けたりと、タスクを横断して対応できるようになるという現象が起こりました。これが、今の言語モデルが汎用的に振る舞うための原動力になっています(岡崎氏)
手塚治虫が現代に蘇る? 生成AIが漫画をつくる時代に
続いて、リレートークは松原氏にバトンタッチする。同氏は「生成AIはAI研究をどこに導くのか」をテーマとして講演を行った。
ディープラーニングが話題になる前から、小説、脚本、マンガなどを生成するAIの研究を行っていたという松原氏。現在は、星新一のショートショートを研究してAIに小説を書かせるプロジェクトや、俳句を詠む人工知能「AI一茶くん」の開発にも携わっているという。
AI技術を用いて手塚治虫を現代に蘇らせようという「TEZUKA2020 プロジェクト」。手塚治虫の過去のマンガから新キャラクターとシナリオの候補をAIに生成させ、残りの作業は人間が行って、2020年のモーニングに掲載された。
また現在は、「TEZUKA2023」として、AIを用いてブラックジャックの新作を作るというプロジェクトも行われている。
生成AIはAI研究における難問を克服できるのか?

言うまでもなく、生成AIは現段階でも非常に優れた能力をもっている。アメリカの司法試験・医師国家試験ではどちらも合格点を取っており、文系理系問わず知能が高く、ある程度の汎用性があるといえる。
一方で、ロボット研究者からは『空間認識能力が弱い』とも言われています。言葉だけで世の中を学習しており、目と耳を持たないので仕方がないですが……(松原氏)
松原氏は、生成AI技術の進歩について、「自動車の発明」にたとえて説明した。
自動車が生まれた時にはまだルールもありませんでしたが、とても便利なので馬車に代わる移動手段として瞬く間に普及しました。その間に、免許・制限速度・道路標識などの整備が進み、今に至った。今でも死亡事故はありますが、メリットの方が大きいので使われています。ChatGPTも同様にルールを作りながら使っていくべきです(松原氏)

現在、AI研究者の目標は汎用人工知能(Artificial General Intelligence)を実現することだという。つまり、「自然な翻訳をする」「将棋で名人に勝つ」といった個別のタスクに特化したAIではなく、人間のような汎用的な知能をもつAIを作ることだ。GPT-4だけで汎用AIを実現するのは難しいが、その足がかりになるのではないかと考えられている。
フレーム問題

また松原氏は、AI研究で古くから言われている問題を2つ紹介した。まず、1969年に人工知能研究者のJohn McCarthy(ジョン・マッカーシー)とPatrick J. Hayes(パトリック・ヘイズ)が提唱した「フレーム問題」だ。
これは、「ある問いに対して関係のある事柄だけを選び出すことができない」という問題のこと。AIは一般に「どこまで考えればいいのか」を学習しておらず、膨大な情報を全て計算しようとすると、時間がかかったり、記述の量が増えたりする。
これは人間も同じです。たとえば『人に迷惑をかけるな』といっても、『迷惑』や『常識』の囲みが人によって違うので、私は迷惑だと思っている、私はそうは思っていないといったズレが生じる。
生成AIは色んな問題に対して適切に答えるので、フレーム問題に対応しているという意見もありますが、私はそもそも『フレームを囲っていない』というのが正しいと思っています。ただし、生成AIがこれを突破するためのヒントとなることは間違いないです(松原氏)
記号接地問題

次に、1990年に認知科学者のStevan Harnad(スティーバン・ハーナッド)が提唱した「記号接地問題」だ。これは、「記号で指し示されるものと実世界の実体・概念とをどう結びつけるか」ということ。たとえば、「リンゴ」という記号と実際のリンゴ(食べる、赤い、酸っぱい)は、人間の中では接地(グラウンディング)しているが、AIは辞書的な意味を知っているだけで、人間のようには認識できないという問題だ。
生成AIは膨大な情報を持っているので、リンゴに関するありとあらゆることを知っているという状態に近づいてはいますが、リンゴを食べられない、味を感じることができないという点で、やはり人間とは異なります(松原氏)

そこで近年進められているのが、「身体性」に関する研究だ。今世界中で、AI研究者・ロボット研究者が共同して、生成AIに身体を持たせる実験が行われているという。
生成AIに目と耳を搭載することで、言葉と感覚を対応させていく。ちょうど人間の子どもが身の回りのものを見て学習するのと同じです。空間認識能力の弱さも解決できるでしょう。それこそ、鉄腕アトムに近づくかもしれません(松原氏)

松原氏は、「AIは人間と同じように言葉の意味を理解しているわけではない」と語る。しかし、ChatGPTのやりとりを見ていると、大体は理解しているように見える。それはなぜだろうか。
有力な説としては、『生成AIは生成AIなりに言葉の意味をわかっている』というものがあります。宇宙人とコミュニケーションが成立しているようなもので、お互いがどう理解しているかはわからないけれど、少なくとも対話できるという状態。
もっとラディカルなものでは、『人間も意味なんか理解していないんじゃないか』という説もあります。対話には意味の理解が必要だという仮定自体が間違っており、実は人間も深く意味を考えずに対話しているんじゃないか、というものです。
チューリングマシンの頃から言われているテーマではありますが、生成AIの技術が進歩したことで、議論はますます発展しています(松原氏)
今後生成AIはどうなっていく? 仕事の代替可能性は?
本セッションでは終盤、岡崎氏、松原氏、モデレーターの樋口氏によるパネルディスカッションが行われた。ここでは最後に、いくつかの質問・回答を抜粋して紹介する。
質問① 今後、良質な言語のリソースが伸びていかず、頭打ちになるのでは?
岡崎氏:Common Crawl(コモン・クロール)におけるデータは現在2600億ページほど収集されているが、データ数としても今後限界はくる。対策としては、質を上げていく、タスクを解くためのデータを開発していくという方向で進んでいくだろうと考えられるが、今のスケーリング則でこのまま伸びていくとは言えない。
質問② LLMよりも学習データの少ない人間が、LLMよりも優れているのはなぜ?
松原氏:岡崎氏の説明にもあったように、LLMは次の単語を予測しているにすぎない。その点で、人間は単語予測以外にもできることがたくさんあるから、というのが1つの答えではある。人間の高度な能力や直感というものが、AI的なアルゴリズムに落とせていないので、具体的に説明するのは難しい。
岡崎氏:身体性の面でも、LLMはまだまだこれから。自分で手や足を動かし、知的好奇心をもって情報を取りに行くということができていない。人間は動物として、長い進化の歴史があり、赤子の時点から教えなくても手足を動かすことができる。同じように、知識処理に関する部分も、人間には生まれながら備わっている部分があると考えられる。
質問③ 生成AIの産業面での活用について
松原氏:最近は医療や法律など、さまざまな業界でAIが注目を集めている。データが大量にある領域では、今のAIはかなり有効。今までデータを集め、分析して傾向を見出すことを生業としてきた専門家は、影響を受けるだろう。特に、事務的作業は生成AIでの代替可能性が高く、たとえば翻訳の仕事などは近い将来大きく変化する。一方で、トップレベルの職能が必要な仕事や、逆に身体性を伴う肉体的作業については、現時点では代替不可能といえる。
- この記事のキーワード
関連記事
【深津式プロンプト】「ChatGPTに役割を与える」活用例と使い方
2023年2月16日 7:00
ChatGPTのプロンプトで使える回答を引き出す“7R”とは マーケター必須スキルとAI最前線
2023年10月18日 7:00
マーケティングで利用するために知っておくべき人工知能(AI)の基礎知識
2017年1月5日 7:00
データ・AIをけん引する企業が一堂に集結! 「10thシンポジウム〜データサイエンスの最前線」10/20(金)開催
2023年10月3日 7:00
未来のマーケティングは“AI”によってどう変わるのか?
2021年11月10日 7:00
AIでクリックは減った? いま狙うべき「質の高いコンテンツ」とは? 今すぐ学ぶべき事柄は? 10個のQ&Aで理解するAI+SEO【2026年版】
5月11日 7:05
バックナンバー
この記事の筆者
筆者の人気記事
Gmailへのメールが届かなくなる? 2024年6月までにやるべき3つの対応
2024年4月3日 7:00
Z世代で流行った言葉「エッホエッホ」って何? 2025年上半期トレンドがカオスすぎる【Z総研調べ】
2025年6月6日 8:00
ボーナスが高い職種ランキング2025! 年間ボーナス平均額は「120.7万円」に急上昇【パーソルキャリア調べ】
2025年11月17日 8:00
【2021年】最新技術ランキング12選 注目の先進テクノロジートレンド【ラックスリサーチ調べ】
2020年11月20日 14:00
男子中学生の将来なりたい職業、「公務員」が初の1位に!「YouTuber」はまさかの急落【ソニー生命調べ】
2025年8月7日 8:00
好きな回転寿司チェーン店TOP3! 全国1位はスシロー? はま寿司? くら寿司?【LINEリサーチ調べ】
2023年12月18日 8:40




