2014年10月16日に
アメーバブログにおいてもGoogleウェブマスターツールがお使い頂けるようになった関係でホスティングサービスにおいてのウェブマスターツールの使い方について書きたいと思います。
ここでのホスティングサービスとは、アメブロをはじめ各ブログサービスやホームページスペース等を指します。
今回はHostingサービスの中でもhttp://ameblo.jp/ユーザーIDのようにサブディレクトリの形式でURLが提供されるサービスでのウェブマスターツールの使い方をご説明します。
(要するにアメブロでのウェブマスターツールの使い方ってことですが;笑)
一部のアメブロユーザー様からは私のソーシャルアカウントにhead内の編集を自由にできるようにして欲しい等のご希望を頂きましたが様々な事情を考慮して今回は管理画面上からウェブマスターツールを設定して頂く機能に制限させて頂いております。ご了承ください。
ウェブマスターツールの使い方については基本はGoogleが公式に提供している
ウェブマスター ツール ヘルプセンターをご一読頂くのが良いと思います。
http://ameblo.jp/ユーザーID などのサブディレクトリ形式でURLが指定されるものはウェブマスターツールの使用が一部制限されます。
また、アメブロもそうですが、SEO上の都合やインフラの事情でURLを意図的にGoogleにインデックスさせていない部分等があったり、それらの設定が閲覧できる状態ではあったりしますが、通常設定の変更はできません。
(なお、現在のアメブロがSEO上においてベストな状態でない部分もまだありSEO担当者として心苦しいところではあります。一部ウェブマスターツール上においても変更が推奨されるような表示が出る場合があるかもしれませんが、より検索エンジンに最適化された構造になるとうにSEO担当者として今後も努力していきたいと思います。)
前置きが長くなりましたがGoogleウェブマスターツールの画面に従っていくつかの機能についてご説明させて頂きたいと思います。
ウェブマスターツール利用準備
それぞれのホスティングサービスで設定方法が異なりますので、各サービスのヘルプ等をご確認ください。
アメブロでのウェブマスターツールの設定方法については、こちらをスタッフブログをご覧ください。
■スタッフブログURL変更必要また、一般的なウェブマスターツールの設定方法に関しては、
■ウェブマスター ツール ヘルプセンター>Google へのサイトの登録■ウェブマスター ツール ヘルプセンター>1. ウェブマスター ツールにサイトを登録するをご覧ください。
ウェブマスターツールトップ画面

ウェブマスターツールの各サイトのトップ画面がこちらになります。
ここで様々な状況の確認や設定ができることになります。
このページは「ダッシュボード」と呼ばれています。
左側のサイドには各機能へのリンクがあります。
ログインした状態では各リンクが折りたたまれた状態ですが、こちらは開いた状態にして画面をキャプチャしています。
ダッシュボードでは「新しい重要なメッセージ」と「現在のステータス」が閲覧できます。
詳細は後述しますが、ここを見るだけでも
「Googleから何かメッセージが来ていないか?」(新しい重要なメッセージ)
「何かサイトに不具合が起きていないか?」(現在のステータス)
を確認することができます。
サイトのメッセージ
ダッシュボードの「新しい重要なメッセージ」部分の「すべて見る」や左側メニューの「サイトのメッセージ」を開くとこの画面が閲覧できます。

このメッセージは非常に重要なものですので、特にSEOを行う場合は定期的なチェックを強くお奨めします。
こちらのサンプル画像にはいくつかのメッセージが来ています。
(なお、ほとんどの方はここにはメッセージがない状態だと思います)
メッセージには、ウェブサイトにおける問題点/アカウントに関する作業関連が主にあります。
この画像にあるサンプルについて説明させて頂くと、
①Google 検索からの DMCA 削除に関する通知
こちらは通常のウェブ運営を行っていれば問題ないはずですが、他サイトからコンテンツをコピーしてしまい、そのコンテンツの持ち主が著作権侵害の申し立てを行った場合にそのコピーコンテンツのURLがGoogleインデックスから削除され、こちらのメッセージが届きます。
コピーコンテンツを無断で引用記述もなく掲載することはSEO上もマイナスになるだけでなく法的にも問題がある場合があります。
他コンテンツを引用したい場合にはblockquoteタグ等を使用して引用元を明記しリンクすることをお奨めします。
(なお、アメブロ運営側においても悪質なコピーコンテンツには厳しく対処させて頂いております。)
参考:ウェブマスターヘルプフォーラム「「Google 検索からの DMCA 削除に関する通知」というメールが来ました。」②Google+ のリンク リクエスト:xxxx と Google+ ページ(xxxxx)をリンクしましょう
これはGoogle+アカウントとウェブサイトを紐付けるためのメッセージです。
Google+側でウェブサイトの所有者確認を行うとこのメッセージが送信されます。
自分のGoogle+アカウントから所有者確認を行った場合はこのメッセージから承認をしましょう。
③Increase in not found errors/「見つかりませんでした」というエラーが増えています
ブログ記事を大量に消すなどした場合に発生するものです。
稀にサーバー側のエラーなどでも発生することがあります。
(アメブロも当然そうですが、通常はホスティングサービス側がドメイン全体におけるウェブマスターツールの監視を行っておりますので、これらのエラーが急増した場合には速やかにエラー要因の調査と改善を行っているのが普通だと思われます。)
ブログ記事などページを大量に削除された場合には、他のブログ記事やページからリンクが残っていてリンク切れになっていないか確認してください。
SEO上大きなマイナスになるわけではありませんが、読者・閲覧者の方の利便性等考慮した場合に重要です。
④ サイトの品質に関する問題

このメッセージが出た場合には要注意です。
そのサイトやブログはすでにGoogleよりペナルティを受けている可能性があり、検索エンジンからの流入は減少しているかもしれません。
このメッセージが送られるブログ・サイトには下記のようなものがあります。
・広告中心でコンテンツに価値がないもの
-特に大量にアフィリエイトコンテンツを生成しているものに多いです
・コピーコンテンツ
-他からコピーしてきたコンテンツをそのまま掲載している
・悪質なスパムを行っているもの
-隠しテキストやキーワードの詰め込み、ドアウェイスパムなど
いずれにしてもGoogleからマイナス評価を受けている可能性が高いのでSEOを考慮するうえでは速やかに修正してください。
また、まれに非常に短い文章のコンテンツや記事
例:「眠い」のみ etc...
にもこのメッセージが出ることがありますが、その際は、メッセージ内の「再審査」リクエストから悪意がなかったことを主張することをお奨めします。
また、SEOを行いたい場合には記事はなるべく長く書くほうが有利だと思ってください。
もちろん意味のあるコンテンツを長く書くというこであって、無意味なものを長く書いても評価はマイナスになるだけですのでご注意ください。
⑤実質のないコンテンツ

こちらも④サイトの品質に関する問題と同様にすでにペナルティを受けている可能性があるメッセージです。
またこのメッセージが届くブログやサイトの特徴も類似しています。
④とのはっきりした境界線はないと思われ、アフィリエイトコンテンツを自動生成しているものや広告が大量に張り付けられたコンテンツに対して送られることが多いものです。
また、非常に短い文章のコンテンツに対してもこのメッセージが届くことがあるのでご注意ください。
⑤外部からの不自然なリンク

このメッセージが届くことはほとんどないと思いますが、自作自演リンクを行うリンクスパムを行っている場合はこのメッセージを見かけるかもしれません。
このメッセージが来た際には間違いなくスパムとしてペナルティを受けているかもしくは数日以内にペナルティを受けると思います。
Googleは被リンクを人気度として評価しています。その特徴を活用して(悪用して?)自作自演による人工的なリンクによってSEO効果を出すという手法があります。
Googleはこの自作自演リンクを発見する仕組みを強化しており多くのケースで自作自演リンクが検知されてしまっているのが現状です。
自作自演リンクはこちらで禁止するものではありませんが自己責任で行ってください。
万一ペナルティを受けた際には、外せるリンクをすべて外したうえでどうしても外せないリンクについてはリンク否認ツールを使い再審査リクエストを送るようにしてください。
参考:ウェブマスターツールヘルプセンター>リンクを否認するまた、身に覚えがないリンクについても上記リンク否認ツールを使用し再審査リクエストを送ってください。
なお、再審査リクエストを送っても必ずしもペナルティ状態が解除されたり元の流入やランクに戻ったりするものではありません。
一部、SEOの意図を持たないリンクに対してこのメッセージが届いてしまう場合があります。
(例えば自分で保有している別サイトからリンクしている場合など)
その際には、SEOの意図がない旨を記載して再審査リクエストを送るか、またはリンクに対してnofollow属性をつけたうえで再審査リクエストを送るようにして下さい。
参考:ウェブマスターツールヘルプセンター>特定のリンクに対して rel="nofollow" を使用するその他にもGoogle視点でブログやサイトに不具合がある場合にここにメッセージが来ますので定期的にチェックするようにしてください。
検索のデザイン
構造化データ
ここでは、Googleも推奨している構造化データの使用状況がどうなっているかを閲覧できます。

ホスティングサービスでSchemaなど構造化のためのタグを使う場合には通常自らHTMLを編集することが必要になります。
(アメブロでもそうですがより気軽に構造化できるようになると良いなと思って試行錯誤しております・・・)
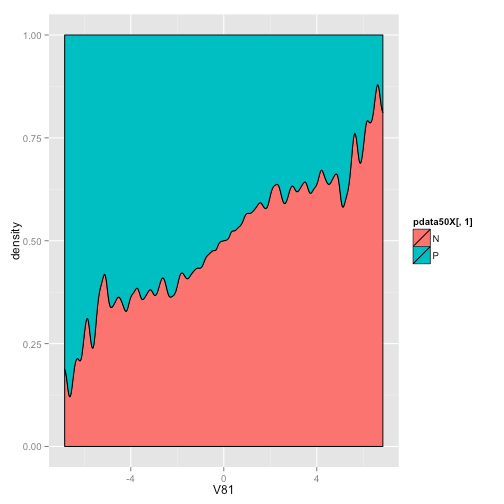
データハイライター
構造化をタグを使わずに行える機能です。
画面のガイドにしたがって簡単に構造化データが指定できます。
ただし、この機能は毎回同じような形式でコンテンツや記事をアップしている場合以外は使いにくいかと思います。
構造化に関しては現在はリッチスニペットの表示の一助となりCTRが高くなることに貢献する可能性があります。例えばレビューを星の数などで表している場合などはリッチスニペットを表示することが可能になる場合があります。
ただし、現時点で構造化データを使うことそのものが直接的にSEO上のランク(Googleでの表示順位)を上げることに貢献するという確定的なデータはありません。
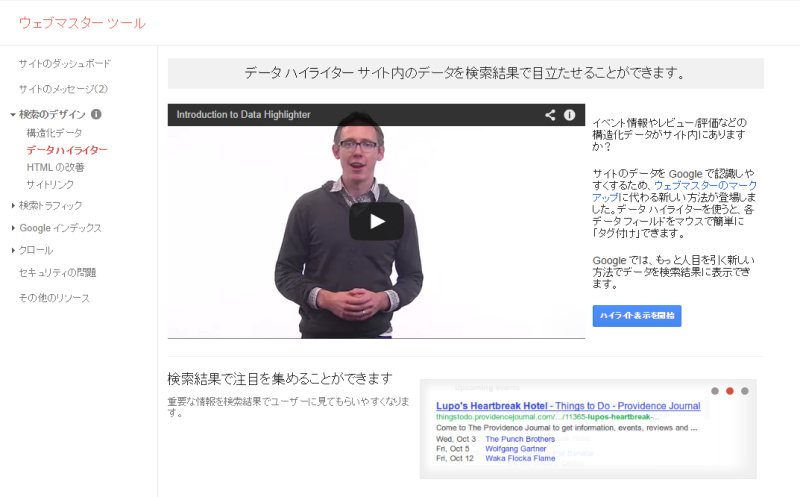
HTMLの改善
HTMLはコンテンツの内容を正しく検索エンジンに伝えるという意味でSEO上も重要なものです。
ただし、昨今ではSEOにおいてかつてほど厳格なHTML記述は求められていません。
その中でここで指摘されるtitleやmetaの重複については、重複発生時にマイナスの評価をなされる可能性がありますので注意が必要です。

このキャプチャのようにtitleやmetaが重複する場合にはなるべく改善するのが望ましいと考えられます。
(現在アメブロではこのようにtitleやmetaが重複してしまう部分があるかと思いますが、今後も不要なページのインデックスを避けるなど対応を進めていきたいと思います。)
また、これらの指摘は複数の記事で同じ記事タイトルをつけた場合にも出てきます。
ブログ記事に関してはなるべくユニークなタイトルになるように工夫することをお奨めします。
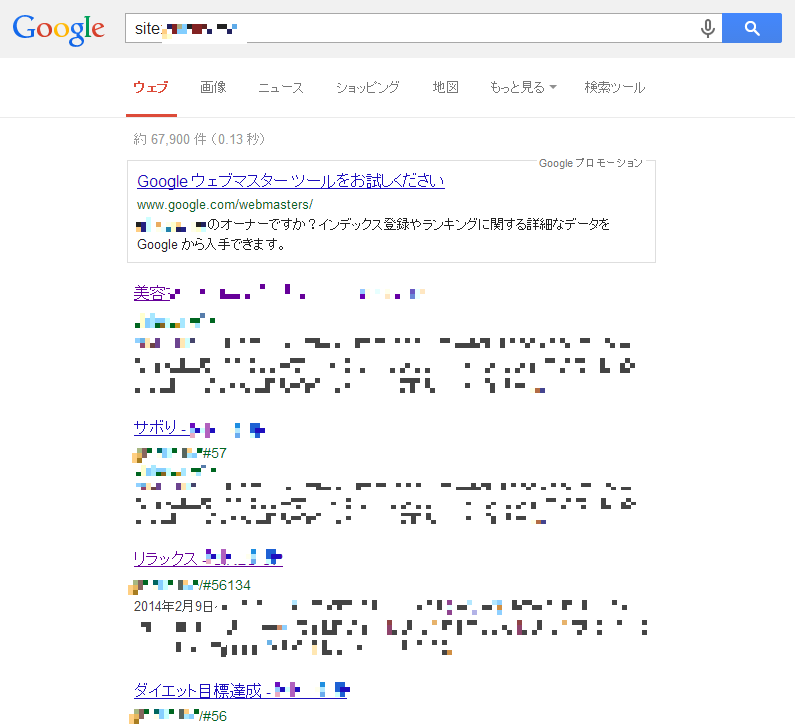
サイトリンク
サイトリンクとはこちらの画像のように表示されるものを言います。
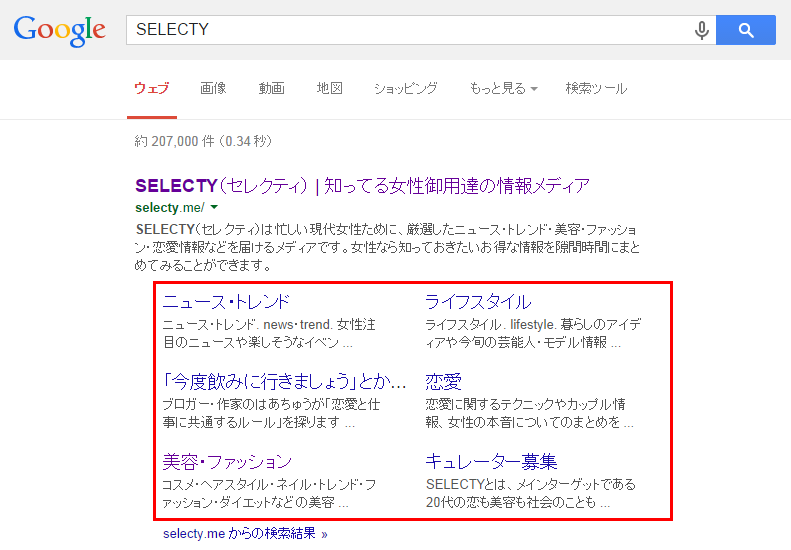
Googleウェブマスターツールではここに表示したくないものを指定することができます。ただし完全な機能ではありませんのでご注意ください。
参考:hinishi.com|WMTに申請しても消せないサイトリンク、手だてはあるの?検索トラフィック
検索クエリ
Googleの検索がhttpsになったことによって、アクセス解析ツールやウェブサーバーのログにはリファラとして検索キーワードが残らなくなりました。(not providedと表示される等)
ウェブマスターツールでは、それらも含めた検索クエリが表示されます。

検索結果の掲載順位も表示されますのでSEOの指標として役立てて頂くことも可能かと思います。
サイトへのリンク
先にも記載した通り、Googleは被リンクを評価します。
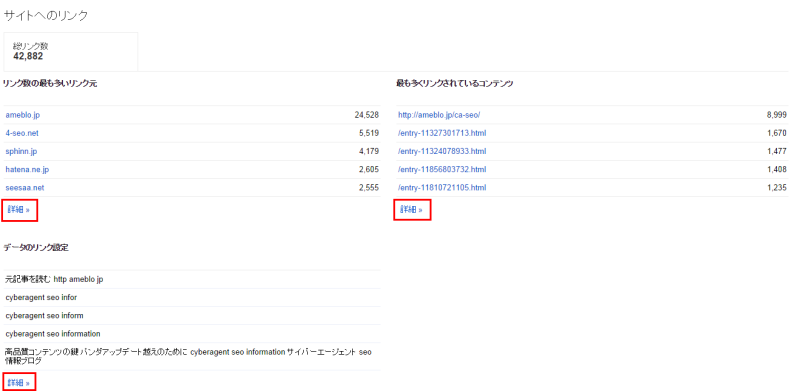
これは当ブログの「サイトへのリンク」です。
「詳細」をクリックするとさらに詳しいデータを見ることができます。

ここではどのような記事にリンクが集まってる(≒人気がある)かやどこのサイトが多くリンクを張ってくれているかなどが分かります。
なお、サイトのメッセージで記述した「外部からの不自然なリンク」によってペナルティを受けている場合は通常ここのデータを見ながらリンクの削除を行ったり否認したりして再審査リクエストを行います。
内部リンク
ブログ・サイト内のリンクデータを表示します。
どこのURLにリンクが集まっているか見ることができます。
(アメブロの場合多くは、「最新の記事」や「テーマ」のページなど全ページからリンクされているページが出てくると思いますが、特に強化したいページはここの数字が大きくなるようにすると効果的です。)
手動による対策
これは「サイトのメッセージ」欄でもふれたスパム行為を行ってしまった際にペナルティを受けているかどかを確認するものです。
(Googleは手動でのペナルティを「手動による対策」「マニュアルアクション」等と呼んでいます。)

手動によるペナルティが与えられている場合は、ドメイン全体に影響しているか一部分に影響しているかが記載されます。
(注:ホスティングサービスの場合、「サイト全体の一致」がブログ単位になるのか、ホスティングサービス全体になるのかは現在確認中です。分かり次第追記いたします。)
手動でのペナルティが与えられているその原因を削除して再審査リクエストを送る必要があります。
インターナショナルターゲティング
場所や言語設定に基づいたターゲットをユーザーの設定を行う機能ですが、現在アメブロではこの機能に対応しておりません。
変更があった場合には別途お知らせいたします。
詳細はこちらをご覧ください。
ウェブマスターツールヘルプセンター>インターナショナル ターゲティングGoogleインデックス
Googleがどのようにブログをインデックスしているかを確認する機能です。
インデックス ステータス
インデックスに登録されたページのボリュームを確認できます。
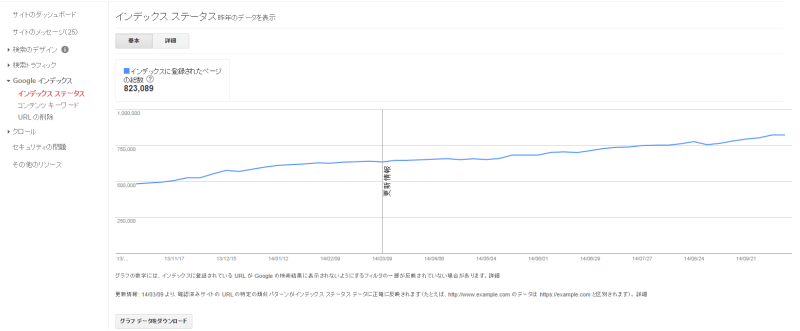
(なお、アメブロ側ではSEO上の理由からrobot.txtの設定等によって特定のURL群のインデックスを避ける場合があります。
多くのブログで8月の末付近でインデックスが減少していると思いますが意図的なものですのでご安心ください。)
参考:SEO HACKS公式ブログ>「クロールバジェット」という言葉について意図しない状況でのインデックスの低下はコンテンツが低品質とみられインデックスが減少している場合がありますのでご注意ください。
またブログ記事を追加しているのにインデックス数が増えていかない場合も同様にコンテンツ内容の質を高めるように気を配って頂くことをお奨めします。
コンテンツのキーワード
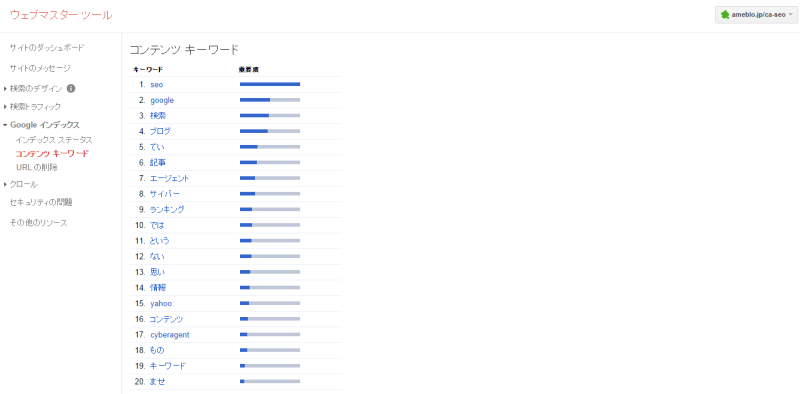
この機能はGoogleがクロールした結果、どのキーワードが重要と認識しているかを表したものになります。
基本的には出現回数によって算出しているとみられますが、この重要度が高いからと言って、必ずしもGoogleでの掲載ランクが高くなるわけではありません。
参考数値程度にご確認ください。
ただし特に重要なキーワードの重要度が低い場合には多少ターゲットとしているキーワードを追加しても良いかもしれません。その際には不自然な追加にならないように注意してください。
(不自然にキーワード追加するとキーワードスタッフィングスパムとしてペナルティを受ける場合があります。)
URL削除
Googleのインデックスから削除したいURLを送信する機能です。
ただしアメブロの場合はインデックスから消したい記事がある場合には基本的にはその記事を削除して頂くかアメンバー限定での公開として下さい。
クロール
クロールエラー

クローラーがブログをクロールする際にエラーが発生していないかどうかを確認するものです。
404エラーは他サイトから誤ったURLのリンクを張られていた場合でも数値が上がりますのであまり気にする必要はありませんが、500や503のエラーが出ている場合には評価が下がる可能性があります。
アメーバブログなどホスティングサービスでは500,503の出現を最小限にとどめるべく当機能の監視とサーバの管理を行っているのが通常です。またもちろんウェブマスターツールも監視しているはずです。
また、ホスティングサービス内の特定のブログうあサイトにおいてだめこれらのエラーが多発することがあります。
稀にですが、設置しているブログパーツ等のJavaScriptが読み込めない場合などにもこのエラーが発生し評価が下がることがあるようですので、ご注意ください。
また、ブログパーツ等の表示に時間がかかる場合はエラーが発生しなくてもSEO上の評価は下がる可能性が高くなります。
クロールの統計情報
アメブロ等の各ブログのアカウント単位ではこちらの機能はお使いいただけません。
ホスティングサービス側で統計情報を監視し、SEO上問題がないようにしているのが通常です。
Fetch as Google

Googlebotがブログをどのように閲覧しているかを確認することおよびインデックスを促すことができます。
(現在アメブロではスマートフォンサイトがリダイレクトされるためスマートフォンに対応したレンダリング状況やインデックスの送信は使用できません。ご了承ください。
また、PCにおいてもJavaScriptやCSSファイルの一部に対してクローラーをブロックしているところがありますが、これら含めより最適な状況になるよう努めていきたいと思います。)
robots.txt テスター
robots.txt テスターは設定したrobots.txtにエラーがないかを確認するツールですが、個別のブログごとにrobots.txtはできません。ご了承ください。
サイトマップ
各ホスティングサービスごとのヘルプページ等をご覧ください。ホスティングサービスによってはサイトマップを送信できるものもあるようです。(現在個別のブログごとにサイトマップを送信することはできません。ご了承ください。
なお、サイトマップではありませんがアメーバブログはPubSubHubbubに対応しております。
海外SEO情報ブログ>Googleマット・カッツが推奨する“PubSubHubbub”でスクレイパーから身を守れ)
URLパラメータ
キャンペーンや計測に用いるパラメータを別々のURLとしてGoogleが認識しないようにする機能です。
基本的にはGooglebotがそのパラメータがインデックスに必要かどうか適切に判断してくれますので、あまり個人で設定する必要はないと思いますし、どうしても必要な場合は通常はホスティングサービス側で一括管理していることが多いのではないでしょうか?
セキュリティの問題
マルウェアなどが仕込まれていないかどうかを確認する機能です。
稀にブログパーツなどを表示するソースにマルウェアインストールを促すスクリプトものを紛れ込ませているような悪質なものがあります。
セキュリティに問題がある場合は結果から削除される、もしくは危険であることが明記されますので流入は大きく減ることになりますし、何よりも閲覧してくださる方が危険ですのでここで警告が出た場合には早急にチェックをしてください。
その他のリソース
その他サイトやブログ運営に役立つ機能やSEOに役立つ機能へのリンクがあります。
適宜ご使用ください。
なお、ウェブマスターツールは随時機能更新されております。
この説明は2014年10月16日時点のものとなります。
※なおアメブロに関しては現在はameblo.jpドメイン配下のみへの対応となっておりますことをご了承ください
※この記事はAmebaのSEOの一担当者、
木村の見解であり、(株)サイバーエージェントならびにAmeba,アメーバブログとしての公式な見解とは異なる場合がありますのでご了承ください
Googleウェブマスターツールの詳細な使い方等は、
ウェブマスターヘルプフォーラムにご質問いただくと良いかと思います。