誰も語ろうとしないAIのダークサイドと、LLMクローラーのログ活用法(前編)
AI生成コンテンツのリスクやrobots.txt問題など、LLM時代に押さえておきたい課題と対策を専門家が解説。
6月22日 7:05
AIの新技術がこれほど注目を集めたのは、2007年のiPhone発売以来だ。iPhoneが世に出た当時、人々は徹夜で並び、あらゆる産業がアップルのエコシステムを中心に形成された。
人工知能(AI)は今、その「iPhoneモーメント」を迎えている。
ほとんどのチームはすでに何らかの形で大規模言語モデル(LLM)を利用しており、マーケティングやSEOに携わっている人なら「ワークフローでAIをもっと活用しなければならない」というプレッシャーを感じているだろう。
しかし、生産性向上の裏には、もっと暗い現実が隠されている。それは、「見せかけの信頼性」「robots.txtを無視するボット」「監視と説明責任の間のギャップ拡大」だ。
このQ&Aセッション「AMA」(Ask Me Anything:何でも聞いて)では、ジェイミー・インディゴ氏が誰も語ろうとしないAIの危険性を読み解くとともに、ブランドのビジビリティを確保するための実践的な方法を紹介している。
4つのカテゴリに分けた11個のQ&Aで、あなたもLLMのダークサイドと希望の両方を正しく理解しておこう。
- LLMとAI検索を正しく理解して誤解を解く
- SEO担当者のAIに対する認識と、その裏の仕組みの間で最大のギャップは何か?
- 私たちはブラックボックス最適化の時代に入りつつある。なぜそれを「テック版狂牛病」と呼ぶのか?
- LLMを利用してコンテンツを作成する場合の隠れたリスクは?
- クロール、インデックス化、技術的な盲点
- LLMはrobots.txtを無視している。クローラーがそうしたルールを守らなくなったとき、それは何を意味するか?
- ログファイルは、LLMクローラーや不審なアクセスパターンの特定にどう役立つか?
- 不要なAIクローラーからウェブサイトを保護したいSEO担当者が今すぐにできることを3つ挙げてほしい。
- LLMのためのテクニカル最適化(後編)
- 「自分のサイトをLLMの視点で見る」にはどうすればいいか? 盲点を見つけるのに役立つツールや方法は?
- 誤った解釈を見つけたら、どのようなプロセスで修正しているか?
- AI検索に対する防御的SEO戦略とはどのようなものか? 何を追跡し、保護し、あるいは書き換えるべきか?
- 構造化データとナレッジグラフは、LLMがコンテンツを理解するための基盤だ。SEO担当者がエンティティレベルでオーソリティを強化するには、どうすればいいか?
- SEOにエージェントAIを利用する上で最大の懸念は何か?
- 結論:自分のブランドがLLMに誤って伝わらないように、予防策を講じよう(後編)
LLMとAI検索を正しく理解して誤解を解く
Q&A 1 SEO担当者のAIに対する認識と、その裏の仕組みの間で最大のギャップは何か?
この質問は出発点にふさわしい。というのも、私たちは一歩引いて思い込みを疑う必要があるからだ。AI検索に関するSEO担当者の考え方には、主に3つのギャップがある。
私たちは次のように思い込んでいる。
- それは検索エンジンだ
- 私たちが指示したことを正確に実行する
- 従来の検索メカニズムを利用する
だが、実際はそうではない。
- 検索エンジンは、情報検索システムである
- LLMは、データコーパスをもとに構築された学習済みモデルで、組み込まれている検索拡張生成(RAG)も使う
まったく異なる基盤なのだ。
1990年代に流行したファービーを思い浮かべてほしい。わずかな語彙があらかじめ登録されており、繰り返しのパターンから学習する玩具だ。あるフレーズを何度も繰り返すと、奇妙な形で返してくれる。

LLMも似たような原理で動作する。パラメータとパターン認識を利用しているのであって、理解しているわけではない(推論モデルが優秀になってきているのは事実だが)。
私たちはLLMを過信しがちでもある。「このページに行って、このタスクを完了させて」と指示すると、モデルは処理を実行する代わりに、何か役に立ちそうなものを生成することもある。
だがLLMは、正しく情報を構築できなくてもハルシネーションで出力を作り、ギャップを確率的な推測で埋めてしまう。そうするように設計されているからだ。
AIに関するアップルの研究論文「The Illusion of Thinking(思考の錯覚)」では、次のように主な弱点の概要を示している:
- タスクの複雑さが増すにつれて精度が低下する
- トークン化にはコストがかかるため、難易度が高まると処理量が減少する
- 指示に首尾一貫して従うわけではない
- 推論の信頼性が失われる
ダン・ペトロヴィッチ氏のAI検索順位変動トラッカーは、この環境がいかに不安定であるかを示している。多くの場合、10件中8件の結果が日々変動し、変動率は80%前後かそれ以上で推移している。
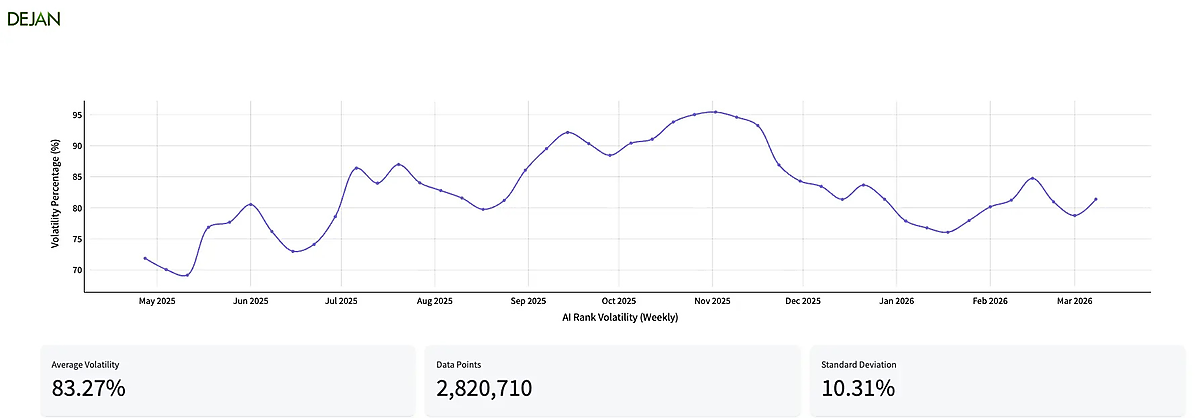
LLMのシステムは検索技術をベースに構築されており、基盤となるコンポーネントの一部は重複しているものの、その仕組みは異なる。
Q&A 2 私たちはブラックボックス最適化の時代に入りつつある。なぜそれを「テック版狂牛病」と呼ぶのか?
狂牛病とは、1990年代に発生した牛の疫病で、「牛を原料とした飼料を他の牛に食べさせた」ことで引き起こされたプリオン病だ。これはシステムが自らを餌にするようなものであり、これこそがAIで起きていることだと私は考えている。
マーケターはAIの出力を利用して戦略に変えているが、モデルの仕組みを理解していないことが多い。マーケターがコンテンツを大規模に公開すると、AIを使って作ったコンテンツをモデルがクロールし、取り込み、学習に利用する。
要するに、私たちは狂牛病の原因を作ったときと同じように、機械に自らの副産物を与えているということだ。

その規模が事態をさらに悪化させている。2024年には公開されたコンテンツが急増し、2010年から2018年の間に増加したコンテンツの総数にほぼ等しかった。
私たちはインターネットを機械生成コンテンツであふれさせ、まさに今、その機械がこれらのコンテンツを使って学習している。結果として、システムはSEO時代の隠し文字(白い背景に白い文字が置かれたコンテンツ)のような、LLMビジビリティを操作するための戦術にだまされるようになってしまう。
Q&A 3 LLMを利用してコンテンツを作成する場合の隠れたリスクは?
LLMは既存の言語パターンを再構成するものであり、これはつまり独自のコンテンツは作成できないということだ。
君のコンテンツが、同じモデルを利用している他のすべてのユーザーと同じ統計データセットから生成されたものであれば、そのコンテンツは他のユーザーにも作れるということだ。君のサイトが代替可能なコンテンツであふれているのであれば、検索エンジンがリソースを投じてクロールし、インデックス化する必要などあるだろうか?

グーグルのマーティン・スプリット氏は、大量のAIコンテンツやサイトの評判の悪用について警告を発している。過去のオンラインセミナーでは、複数の段階で品質検出を実施していると説明していた。一連の処理の早い段階でコンテンツ品質の低さを判断できれば、グーグルはレンダリングを完全にスキップすることもあるという。つまり、そのコンテンツはインデックス化されず、検索結果にも表示されないということだ。
そうした「同質性の海」に沈んでしまうと、そこから抜け出すのは難しくなる。抜け出すには、ユーザーに話題にしてもらい、エンゲージしてもらい、リンクを張ってもらう必要がある。
そもそも回避できるリスクを、なぜ冒す必要があるだろうか?
クロール、インデックス化、技術的な盲点
Q&A 4 LLMはrobots.txtを無視している。クローラーがそうしたルールを守らなくなったとき、それは何を意味するか?
robots.txtは、そもそも強制力のある仕組みではない。簡単な理解に基づく相互の取り決めに過ぎなかった。「私のサイトをクロールしてもいいが、これらのルールを守ってもらう必要がある」という取り決めだ。「アクセスできるのはこのコンテンツで、このコンテンツはアクセスできない」といった具合だ。
残念ながら、AIクローラーがこれらの制限を回避しているのを目にする。たとえばCloudflareは、Perplexityがブロックを回避するためにユーザーエージェントを切り替えていると思われる事例を報告している。

日本語訳は編集部による
間接的な取り込みについても考慮する必要がある。多くのモデルは、本来は学術目的で構築されたCommon Crawlに大きく依存している。AIに特化したユーザーエージェントをブロックしても、Common Crawlのアクセスを許可しておくと、君のコンテンツは学習用データセットに取り込まれる場合がある。
しかし、真の問題は「同意」にある。robots.txtは善意に基づいて作られたが、AIクローラーが動作する競争的な環境では、その動機が必ずしもパブリッシャーの利益と一致するとは限らない。
Q&A 5 ログファイルは、LLMクローラーや不審なアクセスパターンの特定にどう役立つか?
ログファイルには、ダッシュボードが推測する処理ではなく、実際に行われている処理が示される。通常はサーバーまたはCDNレベルで入手可能だ。適切に読み取るにはツールが必要になる。診断ツールの「Screaming Frog」はログファイル分析機能を備えており、Akamaiのような多くのエンタープライズ向けCDNにはオプションが組み込まれている。
ログファイルがあれば、次のことが可能になる:
- 自分のサイトにアクセスしているボットを特定する
- ボットがリクエストしているリソースを確認する
- 異常な急増やパターンを検出する
- 先を見越してルールを調整する
AIボットは攻撃的にもなり、リソースを大量に消費することもある。公開サイトだけでなく、ステージング環境・内部リソース・公開されている開発エリアをクロールすることもある。「隠すことによるセキュリティ(Security by Obscurity)」は通用しない。インターネットからアクセスできるのであれば見つかるものと想定しておこう。
ただし、ほとんどのAIクローラーは専用のユーザーエージェントを使用しているため、識別可能だ。AIクローラーは大きく2つに分けられる:
- モデルコーパスを拡張するためのデータを収集する学習用クローラー
- 検索拡張生成(RAG)を利用し、ツールでのリアルタイムクエリでトリガーされるユーザー主導のクローラー
ログでの挙動は違って見えるため、各ログ行がどちらのクローラーによるものなのかを把握しながら分析する必要がある。
ログ分析では、機能の不一致も明らかになる。たとえば、PerplexityのようなクローラーがJavaScriptをレンダリングしないのであれば、JavaScriptやCSSファイルをリクエストする理由はない。したがって、制限されたパスにアクセスしている場合は要注意だ。
クローラーが適切に振る舞うことを当てにしてはならない。そのため、アクセスを許可する範囲を指定し、その境界を自ら強制する必要がある。
Q&A 6 不要なAIクローラーからウェブサイトを保護したいSEO担当者が今すぐにできることを3つ挙げてほしい。

ログファイルから始める
リクエストを「ホスト名」「ファイルタイプ」「URL構造」ごとに分類しよう。アクセスされている内容と、制限するべき範囲を特定しよう。
すでにあるツールを利用する
robots.txtは、確実に処理してもらえる保証はないとしても、クロール動作を制御することはできる。少なくとも、robots.txtを使用して、次のような種類のURLはクローラーからブロックしておきたい:
- スクリプト
- APIエンドポイント
- ステージングエリア
- その他の機密ファイル
HTML以外のアセットに対しては、noindexやindexifembeddedなどのディレクティブと組み合わせよう。
こうした設定をしておけば、「AIツールが君のブランドを引用したときに提示されたリンクをユーザーがクリックしたら、JavaScriptアプリケーション用のJSON APIダンプが表示された」といった事態は避けられるようになるだろう。
必要に応じて障壁を設ける
機密性の高いエリアには認証を義務付けよう。CloudflareやAkamaiなどのプロバイダーが提供しているファイアウォール制御を活用してほしい。オープンソースのAIファイアウォールAnubisのようなツールは、ボットとのやり取りをフィルタリングして自動化された不正を制限するのに役立つ。
クリエイティブなコンテンツを公開しようとしている人は、多くのAIクローラーがJavaScriptをレンダリングしないことを覚えておこう。ReactやVue.jsなどで作ったページは、ブラウザやグーグルでは正しく表示されても、AIクローラーには空白ページにしか見えないこともある。
この記事は、前後編の2回に分けてお届けする。後編となる次回は、今回に引き続いて「LLMのためのテクニカル最適化」に関する疑問を取り上げる。
- この記事のキーワード
関連記事
Googlebotのユーザーエージェント名(UA名)が変わるよ!【SEO情報まとめ】
2019年12月6日 7:00
SEO監査に有効な「Googlebotブラウザ」の必要性(前編)
2025年4月7日 7:00
SEO施策はAIにも有効? サーバーログが示すAIクローラーの挙動と、疑問に答えるAI×SEO一問一答
4月23日 7:05
テクニカルSEOをスッと理解できる! 元SEO初心者が生み出した18の身近なたとえ(前編)
2025年9月22日 7:00
謎だらけのSEOテクニカル問題を解決する8つのポイントとは? 【中編】グーグルは正しくクローリングできている?
2018年10月29日 7:00
「SEO」と「SPA/PWAによるUX向上」を両立させるハイブリッドレンダリングの基礎知識と実現手法
2019年8月26日 7:00
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「The Dark Side of AI No One Talks About」 by Jamie Indigo(2026/03/12)
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




