AIによる概要やChatGPTに自社情報を出すには? 「インモデル」と「アウトオブモデル」を解説
AI検索に自社情報を表示させるために「2つの回答パターン」を理解しよう。LLMの仕組みから、最新のAI検索を紐解く。
6月15日 7:05
君のSEO戦略は、大規模言語モデル(LLM)のグラウンディング※に対応できているだろうか。「学習データ」と「リアルタイム」でのウェブ検索の違いを探り、AIによる検索結果でブランドのビジビリティを最適化する方法を見つけよう。
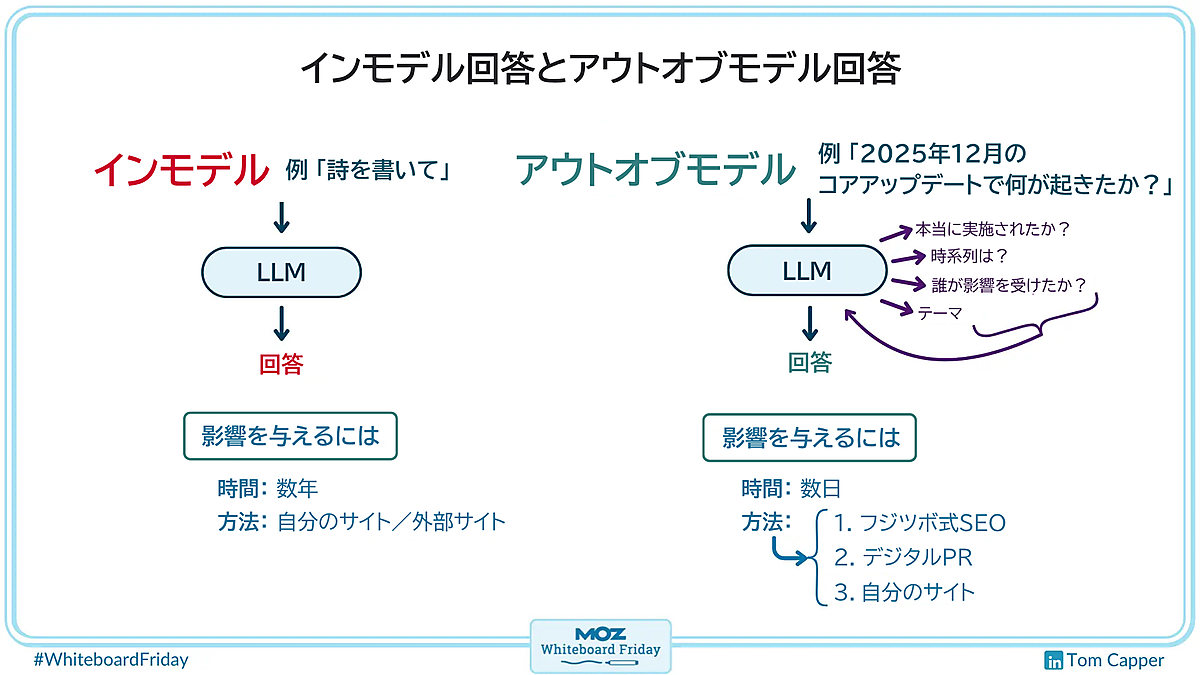
Mozファンのみんな、こんにちは。今回は、SEO担当者にとって今後重要になると思われる概念について話したい。その概念とは、LLM(生成AI)が回答を作るときの、次の2つのタイプの違いだ:
- インモデル(モデル内)回答
- アウトオブモデル(モデル外)回答
これはLLMの回答に関する話だ。しかし、次の3つのような現在グーグル検索で表示されるようなハイブリッド機能にも大いに当てはまる:
では、本題に戻る。「インモデル回答」と「アウトオブモデル回答」についてである。これは、プロンプトで指示を受けたあとにLLMが回答を作る2種類のやり方を分類したものだ(ごく単純化するために2つに分けている)。
LLMが回答を生成する際に判断することが1つある。それは「グラウンディング検索が必要かどうか」を判断することだ。これはつまり、言い換えると、「回答を生成するために、外部クエリ(通常はグーグル検索)を実行する必要があるかどうか」だ。
「新しい情報が必要」な場合や、「よくわからない点があり確認する必要がある」場合などに、外部クエリを実行する(今のところ、ChatGPTであっても通常は、外部クエリと言えばグーグル検索のことだ)。
つまり、次のような区別だと考えるとわかりやすい:
- 外部クエリを実行する必要がない場合 ―― インモデル回答
- 外部クエリを実行する必要がある場合 ―― アウトオブモデル回答
「どんなプロンプトの場合にどの動きになるのか」と、「その回答に君が影響を与えたい場合にどんなことをすべきか」を解説していく。
インモデル回答: LLMの知識だけで回答を作れる場合
まず、LLMが外部クエリを実行する必要がない場合だ。たとえば、次のようなプロンプトをLLMが受け取ったとしよう:
詩を書いて
このプロンプトでは、「特定の事実」「最新情報」「トピック」などが関係してこない。この場合、LLMは外部のグラウンディング検索をせず、君はLLMから直接回答を得ることになるだろう。
この動作を「インモデル回答」という(モデル内の情報で回答)。

このインモデル回答に影響を与えたい場合、モデルの基盤である学習データに影響を与える必要がある。これは通常のSEOとは時間軸が異なる。
少し背景を説明すると、LLMは、ある時期までに学習した内容を「モデルのなか」にもっている。たしかGPT-4.0が学習データとして持っているのは2022年末までの情報で、GPT-4.5は2024年8月末までの情報だったと思う。つまり、最新モデルを使っていなければ4年近く前の情報までしかもっていないLLMを相手にしていることになる(他のモデルではさらに情報が古い場合もある)。
したがって、「そのモデルからLLMがどんな回答を生成するのか」に対して君がすぐに影響を与えられる余地はない(タイムマシンで過去に遡れるのでなければ)。
ただし、長期的な観点で言えば、影響を与える方法はある。とはいえそれは、「今後これらのモデルの学習データに取り込まれるあらゆるコンテンツ」に影響を与えておくことで、次のモデルでその効果を出すというものだ。
その対象は、コンピュータが処理可能なあらゆるテキストコンテンツだ(HTMLやMarkdownなど)。これは驚くほど広範に及ぶ。それにもちろん、君自身のサイトだけを意味するわけではない。外部サイトも含まれる可能性がある。しかも現時点では、書籍のようなものを意味する可能性もある。この基盤となる学習データは信じられないほど広範になっている。
アウトオブモデル回答: 外部クエリで得た情報をふまえて回答を作る場合
SEO担当者にとってより興味深いのが、もう一方の「アウトオブモデル回答」だと思う。これは、LLMが「回答を生成するのに、外部検索をする必要がある」と判断した場合だ。
プロンプトの例を挙げると、次のようなものだ:
2025年12月のコアアップデートで何が起きたか?

ChatGPTでは現在、ブラウザのデベロッパーツールでグラウンディング検索の内容を確認できる。
一方グーグルのAI機能では、ChatGPTの場合のように内部検索を直接見られるわけではない。しかし、「AIがこういう追加検索をしていそうだ」というクエリファンアウトの痕跡が見えることがある。
「2025年12月のコアアップデートで何が起きたか?」というプロンプトへの回答を作る場合、AIの外部クエリはまず「本当に実施されたか?」といったものになる。つまり、「2025年12月のコアアップデートが実際に行われており、僕がでっち上げたわけではない」ことを確認するためのクエリを実行するのだ。
それから、次のことを調べているのも確認できる:
- どのような時系列だったか
- 誰が影響を受けたか
- どのようなテーマだった可能性があるか
当然ながら、こうしたクエリに対してグーグル検索ではさまざまな記事が見つかる。多くの場合、これらは人が入力するようなクエリにはならないだろう。かなり長いクエリになる。
LLMは各クエリに対する最初の数件の結果を見て(場合によってはそれ以上の結果を見て)、そうした外部情報から回答を組み立てようとする。
ここで興味深いのは、君がアウトオブモデル回答に影響を与えようとした場合、その効果はかなり早く反映される可能性があることだ。LLMはプロンプトを受けてから検索している。そのため、君のサイトのコンテンツを変更して、それがグーグルにクロールされてインデックスされれば、LLMの外部クエリに影響を与えられるというわけだ。
当然ながら、どれぐらいの時間で効果が出るかは、サイトによって異なる。主要なニュースメディアに影響を与えられるのであれば、数分から数時間でアウトオブモデル回答に影響を与えられる。もう少し時間がかかるサイトもあるかもしれない。しかし、インモデル回答の場合のように「基盤となる学習データに影響を与えようとする」ときよりは、はるかに早く効果が出るのは確かだ。
アウトオブモデル回答に影響を与えるための戦略
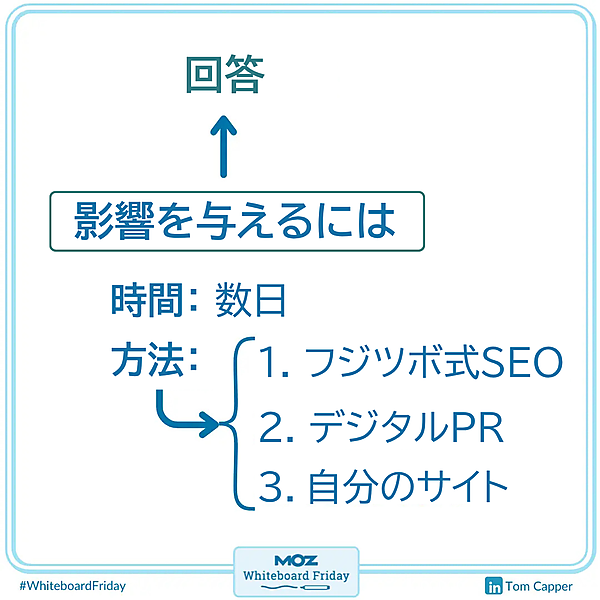
その方法は3つある。次では、現時点で僕が有効だと思う順に並べてみた。
方法1フジツボ式SEO
最も有効なのはフジツボ式SEOだと思う。LLMが情報確認のために検索するクエリに対して、どんなサイトが上位に表示されるだろうか? 必ずしも君のサイトだとは限らない。むしろ、上位に表示されるのは君のサイトでないことが多いだろう。
そこで、たとえば君のプレゼンスを通じて影響を与えられるオーソリティの高い外部サイトとして、君のソーシャルプロフィール、Medium、LinkedIn、Wikipedia、YouTubeについて考えてみよう。
これらのいずれにも、君は影響を及ぼせる。これまでは「ブランドキーワードでのSERP」といったものを独占しようと取り組んでいたかもしれないが、今後はこうした「ブランド以外のキーワード」も対象に、自分の結果だけでなく、他のサイトにも影響を及ぼせるようにする必要があるだろう。なぜなら、グーグルやChatGPTなどは、参照しているデータの出所が君のサイトであろうと他者のサイトであろうと、どちらでもいいからだ。
したがって、フジツボ式SEOは今後、重要性が増すだろう。
方法2デジタルPR
この分野で、君が直接コントロールできないオーソリティの高い第三者のサイトに影響を与えるには、デジタルPRも非常に重要となる。
方法3自分のサイト更新
そして最後に、もちろん君自身のサイトだ。LLMが実行する検索クエリに対して、君自身のサイトが上位に表示される必要もあるからだ。
何をどうすればいいのか? SEO担当者にとって慣れ親しんだやり方を進めればいい。
これは重要な違いになると思う。特定のクエリに影響を与えることが現実的かどうかを検討するとき、あるいはMozやSTATといったツールでAIでのビジビリティをトラッキングするために追跡すべきクエリを検討する場合にも、そのクエリがどちらのタイプに該当するかを念頭に置く必要があると思う。
僕からは以上だ。参考になれば嬉しい。ありがとう。
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「In and Out of Model Responses Explained — Whiteboard Friday」 by Tom Capper (2026/03/06)
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




