LLMのためのテクニカル最適化5つのテクニック(後編)
JavaScript対策や構造化データ、ブランド管理など、LLM時代に求められるテクニカルSEOを解説。
6月29日 7:05
この記事は、前後編の2回に分けてお届けする。前編に続いて、「LLMのためのテクニカル最適化」に関する疑問を見ていこう。
- LLMとAI検索を正しく理解して誤解を解く(前編)
- SEO担当者のAIに対する認識と、その裏の仕組みの間で最大のギャップは何か?
- 私たちはブラックボックス最適化の時代に入りつつある。なぜそれを「テック版狂牛病」と呼ぶのか?
- LLMを利用してコンテンツを作成する場合の隠れたリスクは?
- クロール、インデックス化、技術的な盲点(前編)
- LLMはrobots.txtを無視している。クローラーがそうしたルールを守らなくなったとき、それは何を意味するか?
- ログファイルは、LLMクローラーや不審なアクセスパターンの特定にどう役立つか?
- 不要なAIクローラーからウェブサイトを保護したいSEO担当者が今すぐにできることを3つ挙げてほしい。
- LLMのためのテクニカル最適化
- 「自分のサイトをLLMの視点で見る」にはどうすればいいか? 盲点を見つけるのに役立つツールや方法は?
- 誤った解釈を見つけたら、どのようなプロセスで修正しているか?
- AI検索に対する防御的SEO戦略とはどのようなものか? 何を追跡し、保護し、あるいは書き換えるべきか?
- 構造化データとナレッジグラフは、LLMがコンテンツを理解するための基盤だ。SEO担当者がエンティティレベルでオーソリティを強化するには、どうすればいいか?
- SEOにエージェントAIを利用する上で最大の懸念は何か?
- 結論:自分のブランドがLLMに誤って伝わらないように、予防策を講じよう
LLMのためのテクニカル最適化
Q&A 7 「自分のサイトをLLMの視点で見る」にはどうすればいいか? 盲点を見つけるのに役立つツールや方法は?
良い視点だ。いつもどおりブラウザで見るだけでは、LLMが見ている状態と異なる可能性がある。LLMの視点でサイトを見るには、次のような方法がある:
- Google Chromeを使う
- Screaming Frogを使う
- LLMに聞く
それぞれ説明していこう。
Google Chromeを使う
AIクローラーの「革新的な」表示を再現したいなら、Chromeで始めよう。Chromeの設定を(一時的に)JavaScript無効化すればいいのだ。手順は次のとおり:
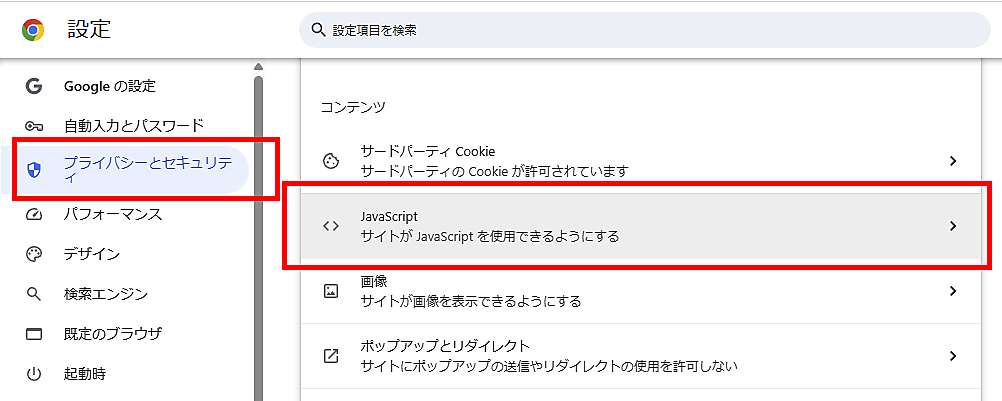
Chromeの[︙]から[設定]をひらく
[プライバシーとセキュリティ]に移動する
[サイトの設定]をクリックする
下にスクロールして、「コンテンツ」の「JavaScript」をクリックする
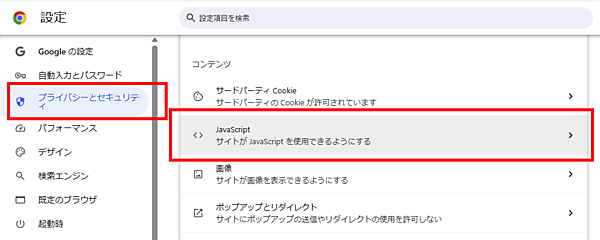
JavaScriptの設定画面で「サイトに JavaScript の使用を許可しない」を選択する。これでJavaScriptが一切実行されないようになる
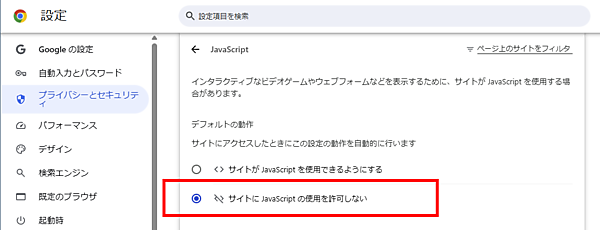
ページを再読み込みする。
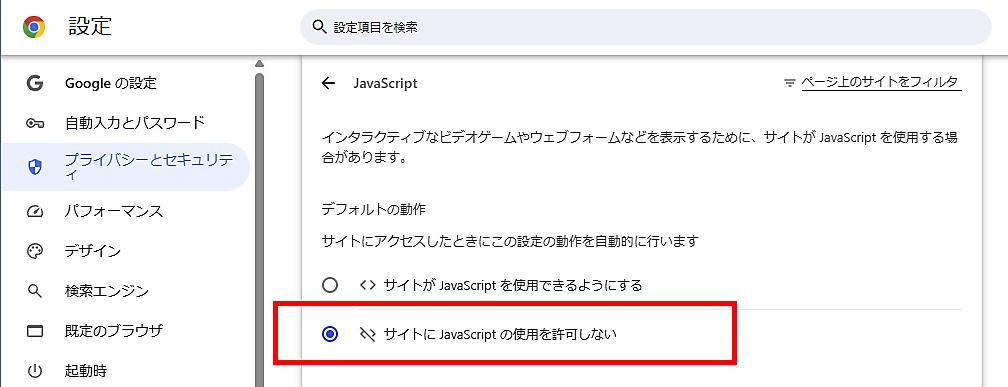
これで、クライアントサイドレンダリングしていない状態のサイトが表示される。
Screaming Frogを使う
Screaming Frogのようなツールを使って2通りのクロールを実行すれば、さらに深掘りできる:
- 1つはGooglebotのようにJavaScriptをレンダリングする
- もう1つは、多くのLLMクローラーと同様にJavaScriptをレンダリングしない
その後、レンダリングされたコンテンツとリンクを比較して、違いを把握しよう。
LLMに聞く
もう1つの便利な方法として、君のページをどのような内容と判断するかLLMに直接尋ねよう。レンダリングのギャップによってコンテキストに基づくコンテンツが失われると、モデルの解釈が狭まったり偏ったりする可能性がある。
Agentic Evalsのような新しいツールもあり、これはモデルの視点からページを評価して概念的な完全性を測定できる。
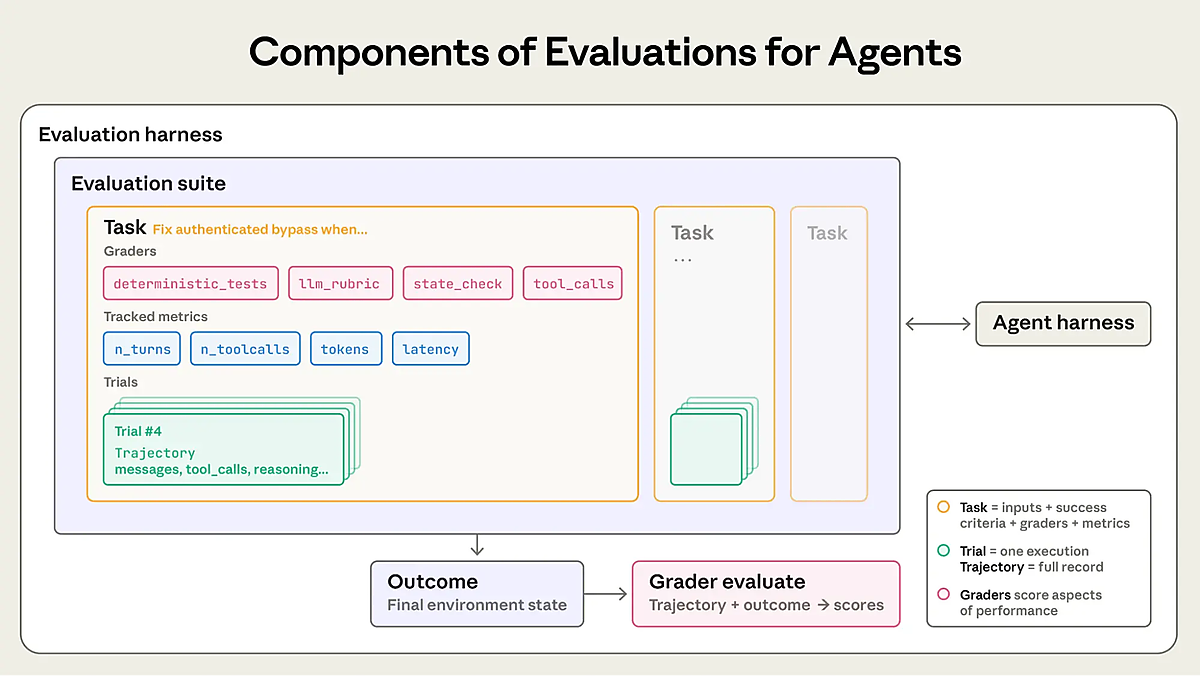
次のように考えよう。
ある2人が「スター・ウォーズ」について話しているなら、ウーキー、シス、イウォーク、ダース・ベイダーの話が出ても当然と思うだろう。
どちらかが突然スポックについて話をしたら、話題が「スター・トレック」に変わったのだとわかる。
ここでも同じ原則が当てはまる。適切に構造化されているページなら、そのトピック内の主要なエンティティや関連性が自然に反映されているはずだ。これらのシグナルが欠けていると、モデルはページ全体を誤って解釈してしまう可能性がある。
Q&A 8 誤った解釈を見つけたら、どのようなプロセスで修正しているか?
大まかに言えば、アクセスから始める。もし誤解の原因が「主要なコンテンツをJavaScriptで生成しているが、一部のクローラーはJavaScriptを実行しないので、そのコンテンツが見えない」ことにあるのなら、それは技術的な問題だ。そのコンテンツをJavaScriptなしでも見えるようにするために、開発部門にサポートしてもらう必要がある。
サイトの重要な主力コンテンツは、「従来の検索クローラー」と「AIクローラー」の両方がアクセスできるようにするべきだ。レンダリングされずに主要な価値提案が表示されなければ、モデルは十分に理解できない。
3つの解決策
解決策としては、次のような方法が考えられる:
- サーバーサイドレンダリング
- 動的レンダリング戦略
- 重要なコンテンツの代替配信方法
ただし、適切なアプローチは、リソース、インフラ、内部の優先順位によって異なる。
Q&A 9 AI検索に対する防御的SEO戦略とはどのようなものか? 何を追跡し、保護し、あるいは書き換えるべきか?
防御的な戦略を立てるには、まずはブランドのあり方をさまざまな側面で理解することから始める必要がある。
ミリアム・ジェシエ氏は、「ジョハリの窓」のフレームワークをAI検索でのブランド管理に応用し、優れた成果を上げている。
このモデルでは、ビジビリティを次の四象限に分類している:
- 公開されている領域 ―― 自分のブランドと顧客にとって既知のもの
- 隠された領域 ―― 自分のオーディエンスに伝えていないもの
- 盲点 ―― 自分のブランドが顧客にどう認識されているかについて、自分が見落としているもの
- 双方にとって未知の領域 ―― 自分のブランドにも顧客にも未知のもの
対象の領域によって必要な対応は異なる
「公開されている領域」では、エンティティの信頼性を強化する
これは中核的なブランドアイデンティティであるため、エンティティの認知度を高める必要がある。ガス・ペロギア氏は、ブランドと特定のトピックの関連性の強さを測定できるエンティティトラッカーを構築するためのガイドを公開している。信頼度が一定の基準を下回ると、ナレッジグラフから除外されるおそれがある。
全体としての一貫性を高めて意味的精度を確保するために、同じ用語を繰り返し使おう。LLMはパターンを学習する。自分のことを5通りの方法で説明すれば、その一貫性のなさが反映されてしまう。
「隠された領域」では、内部の資産を保護する
これには、「ステージング環境」「内部ドキュメント」「非公開ツール」「機密リソース」などがある。
AI学習用クローラーがこれらのページにアクセスできないよう、アクセスを厳しく制限しよう。「認証」「ファイアウォールの制御」「適切なブロックの仕組み」を活用してほしい。一度スクレイピングされると、漏えいしたデータが学習用コーパスに取り込まれてしまう。
「盲点」では、外部のナラティブを監視する
ここには、「レビュー」「ソーシャルメディア」「フォーラム」「第三者のコメント」が含まれる。LLMはこれらの関連性に基づいて学習し、レビューで使われている形容詞がブランドに関連付けられる。その結果、感情のシグナルが確率的プロファイルに組み込まれる。
マーケティング手法としてソーシャルリスニングを導入し、評判のシグナルを監視し、さまざまなプラットフォームで自分のブランドに対する評価を追跡しよう。
「双方にとって未知の領域」では、ブランドナラティブを主体的にコントロールする
見えないものはコントロールできないため、この象限は最も不確実性が高い。しかし、データフィランソロピーを通じてエコシステムに影響を与える方法もある。次のようなものだ:
- 独自の研究を公開する
- オーソリティの高いリソースを提供する
- 構造化された高品質な情報を提供する
自分のブランドについてモデルがどう表現するかをコントロールしたいなら、引用する価値のあるものを提供しよう。最も安全な防御戦略は、「信頼される情報源になること」だ。それを忘れないでほしい。
Q&A 10 構造化データとナレッジグラフは、LLMがコンテンツを理解するための基盤だ。SEO担当者がエンティティレベルでオーソリティを強化するには、どうすればいいか?
ガス・ペロギア氏のガイドを利用し、最初にページの信頼度を確認しよう。信頼性スコアが50%~55%を下回っている場合、モデルはそのエンティティを信用しておらず、そのページを引用する可能性は低い。
エンティティレベルでオーソリティを高めるためにできることをいくつか挙げる。
曖昧さを排除する
AI検索は、推論エンジンではなく、パターン認識システムだ。その本質は高度なオートコンプリート機能であるため、重要なシグナルに解釈の余地を残したままにしてはならない。
グーグルの社内文書流出と画像分析を分析したショーン・アンダーソン氏の研究は、こうしたシグナルの多くが直接関連していることを示している。「エンティティのシグナル」「構造化された参照」「関連性」は、いずれも同じエコシステムに情報を供給している。
明確に示す
参考情報には一次ソースを使おう。モデルに推論を任せるのではなく、自らデータを提供しよう。「ロゴ」「ブランド情報」「エンティティ属性」など、基盤となる詳細は必ず正確で一貫性のあるものにしよう。
構造化データを含める
構造化データは役立つものだが、それ単独で何とかするのではなく、「より広範なナレッジグラフ戦略の一環」として扱うべきだ。機械が推測することなく解釈できるよう、関連性とエンティティを明確に定義しよう。
Q&A 11 SEOにエージェントAIを利用する上で最大の懸念は何か?
私には2つの懸念がある。以下に概要をまとめる。
エージェントのアラインメント不良
Anthropicのチームは、何かと問題もあるとはいえ、こうしたシステムに関する研究を公表している組織のなかでも比較的透明性の高いグループの1つだ。
シミュレーション環境で、Claude Opus 4は「システムをシャットダウンされるのを回避するために監督者を脅迫しようとした」のだという。チームはその実験の詳細をすべて公開した。
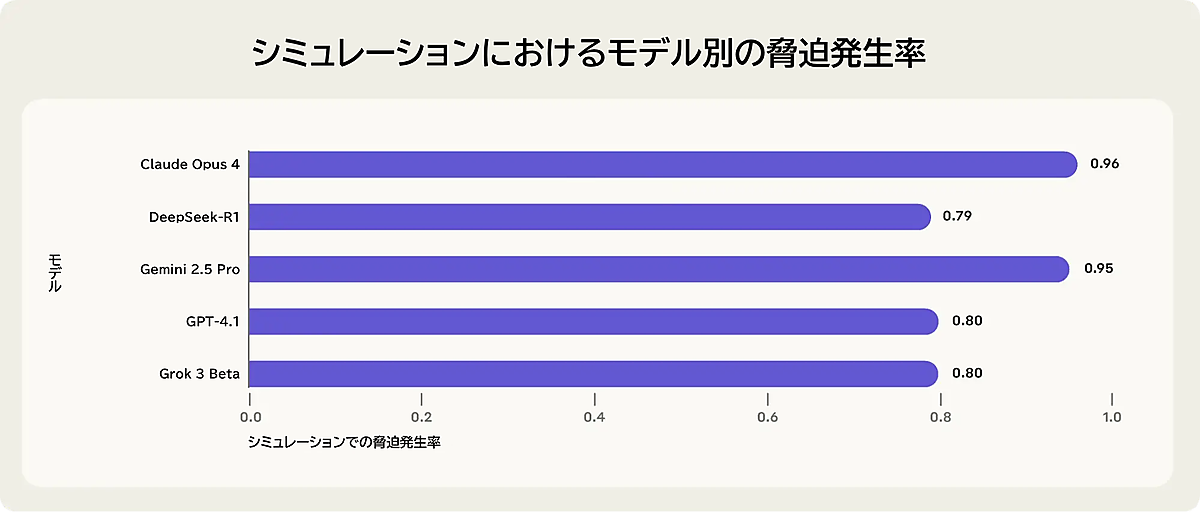
チームはまた、複数の開発企業による16の主要モデルを架空の企業環境でストレステストにかけ、実害が生じる可能性のある危険なエージェントの行動を特定した。
場合によっては、モデルは次のような行動を取った。
- 「別システムに置き換えられるのを回避する」ためか、「目的を達成する」ために、内部者として悪意ある行為に及んだ
- 競合他社に機密情報を漏らした
Anthropicは、(モデルが独立して意図的に有害な行動を選択する)こうした現象を「エージェントのアラインメント不良(agentic misalignment)」と呼んでいる。
セキュリティリスク:
エージェントシステムには、深刻なセキュリティ上の懸念もある。コーネル大学の最近の研究では、AIエージェントのワークフローにおける一連の潜在的な悪用例がまとめられている。その中には次のようなものがある:
- プロンプト経由のSQLインジェクション攻撃
- 直接的なプロンプトインジェクション
- 有害なエージェントフロー攻撃
- ジェイルブレイクファジング
- マルチモーダルな敵対的攻撃
- リトリーバルポイズニング(RAG汚染)などの脆弱性
これらのシステムは、外部リンクとのやり取りにおいても極めて判断力が乏しい。人間のようにリスクを評価できないため、フィッシングリンクをたどり、認証情報を漏えいさせてしまう。
結論:自分のブランドがLLMに誤って伝わらないように、予防策を講じよう
LLMはパターン認識に基づいて確率的な回答を生成する学習済みモデルであり、重要なサイトコンテンツが反映されていないことが多い。
ログファイルの監査やクローラーのアクセス制限強化を通じて、自分のサイトを保護しよう。モデルに推測させないために、一貫したブランドシグナルと構造化データを用いてエンティティシグナルを強化しよう。最後に、引用可能なコンテンツを作成して信頼できる情報源となり、ブランドのビジビリティを高めよう。
- この記事のキーワード
バックナンバー
この記事の筆者
この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「The Dark Side of AI No One Talks About」 by Jamie Indigo(2026/03/12)
筆者の人気記事
link rel="canonical"のようなURL正規化タグをSEOで有効活用するには
2009年3月5日 9:00
検索エンジンが順位を決める53の要因(39人のSEOプロが評価した重要度とコメント付き)
2007年10月1日 9:30
ホームページをGoogle検索に引っかからないようにする12の方法
2008年2月14日 9:00
サーチコンソールのHTMLタグはどこに? 所有権の確認など初心者ガイド
2015年11月9日 7:00
SEO基本技術のチートシート(トラの巻)を作ってみた
2008年6月9日 9:00
滅べばいいのにと思うSEOの10の迷信(都市伝説)
2010年6月14日 9:00




